
GridDB V5
GridDB 生まれ変わる!
2013年にGridDBをリリースして以来、さまざまな機能強化を取り入れてきた結果、ソフトウェアの構造が複雑化してきました。 そこで、GridDB V5ではソフトウェア構造を刷新し、保守性の向上、今後の迅速な機能強化基盤を実現しました。 今後も末永くGridDBをお使いいただくために、GridDBは生まれ変わりました。
ビッグデータやIoTシステムにおけるデータベースは高速性や拡張性、信頼性が求められています。GridDBでは、イベント駆動処理技術や自律データ再配置技術 (ADDA) を開発し、これらの要件を満たすデータベースを提供してきました。近年、IoTで扱われるデータやその活用方法が多様化しており、その結果、データモデルも多様化しています。新たなデータモデルを扱う際、複数のデータベース管理システム(DBMS)を用意したり、あるいは無理やり単一のDBMSで対応したりしているのが現状です。しかしそのような対応方法では、システムの煩雑化、構築・運用コストの上昇、リアルタイム性の損失などの問題が生じます。
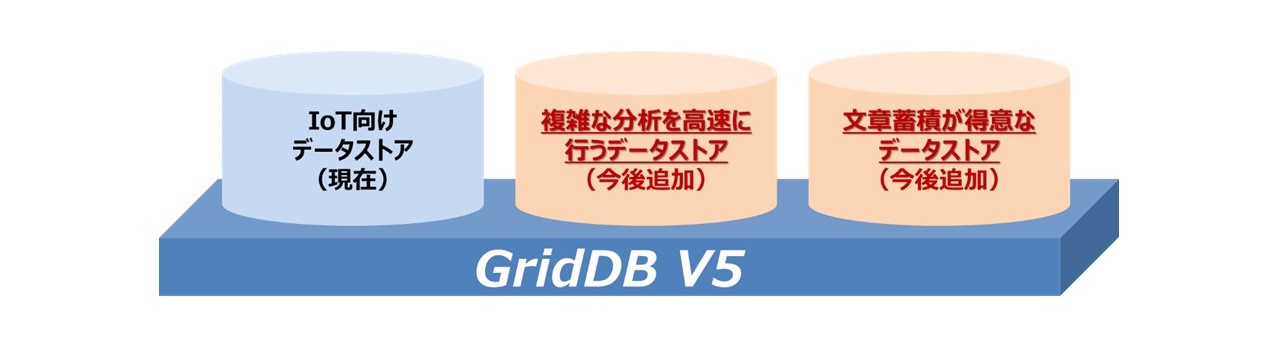
GridDB 5 ではアーキテクチャを刷新し、単一のDBMSでありながら複数のデータモデルを扱うことを可能とした、プラガブルデータストアを実装しました。これまでGridDBが提供してきた高頻度で大量なデータ登録に適したデータストアに加え、複雑な分析を高速に行うことができるデータストアや、ログなどの文章を蓄積することが得意なデータストアを組み込むことができます。
これまでのIoTシステムでは大量のセンサーデータを貯めて、可視化することで価値を提供してきました。しかし最近では貯めたデータを用いて複雑な分析を行い、新たな知見を得ようとする動きが出てきています。大量高頻度のデータを貯める機能と、複雑な分析を高速に行う機能は、DBMSとしては相反する要件になります。
これをプラガブルデータストア機能により、それぞれに適したデータストアを一つのDBMSの中に実現できるようになります。複数のDBMSを使用するのではなく、単一のDBMSで統合的に処理することが可能となり、複数のDBMSが混在することによるシステムの複雑化や、構築・運用コストの上昇などを避けることができます。
今後、複雑な分析を高速に行うデータストアや、文章の蓄積が得意なデータストアを順次提供していきます。
GridDB 5.0 では、独自の高効率チェックポイントアルゴリズム技術 HCAL (Highly efficient Checkpoint Algorithm for Large-scale data) による新チェックポイント方式を導入し、チェックポイント時のファイルへのログ書き込み量を削減し、ディスクI/O負荷を低減させました。これにより頻繁にデータの追加・更新を行うシステムでは、システムの負荷が下がり、その結果、より多くのデータベース処理を実行できるようになりました。
また、テーブルごとに固有のブロックを割り当てることで、テーブル単位のスキャンや削除を高速化できる機能を追加しました。テーブルスキャンが多用されるデータ分析クエリなどで有効です。また削除予定のテーブルを指定しておけば、テーブル削除が高速になります。
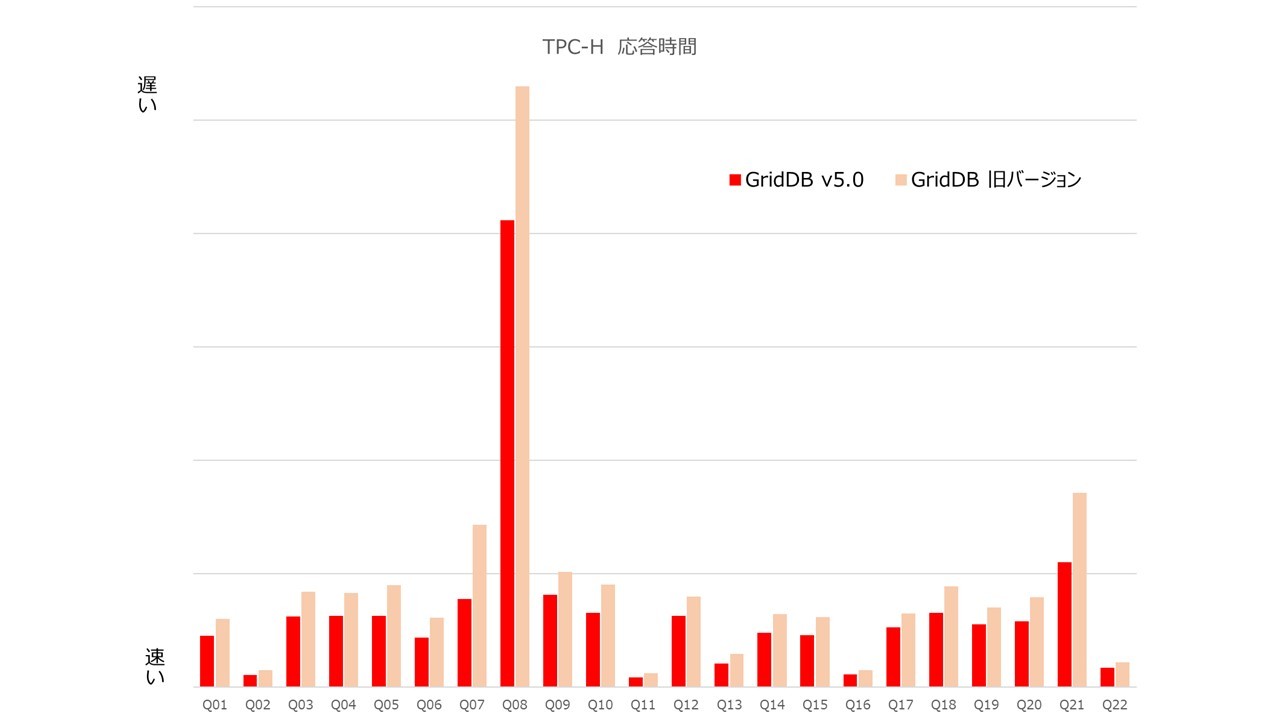
これらの性能改善をおこなうことで、データベースの性能比較するためのベンチマークテスト(TPC-H注9)で、次のように17%~46%(平均26%)改善しました。
 このページのトップへ
このページのトップへ