
Features
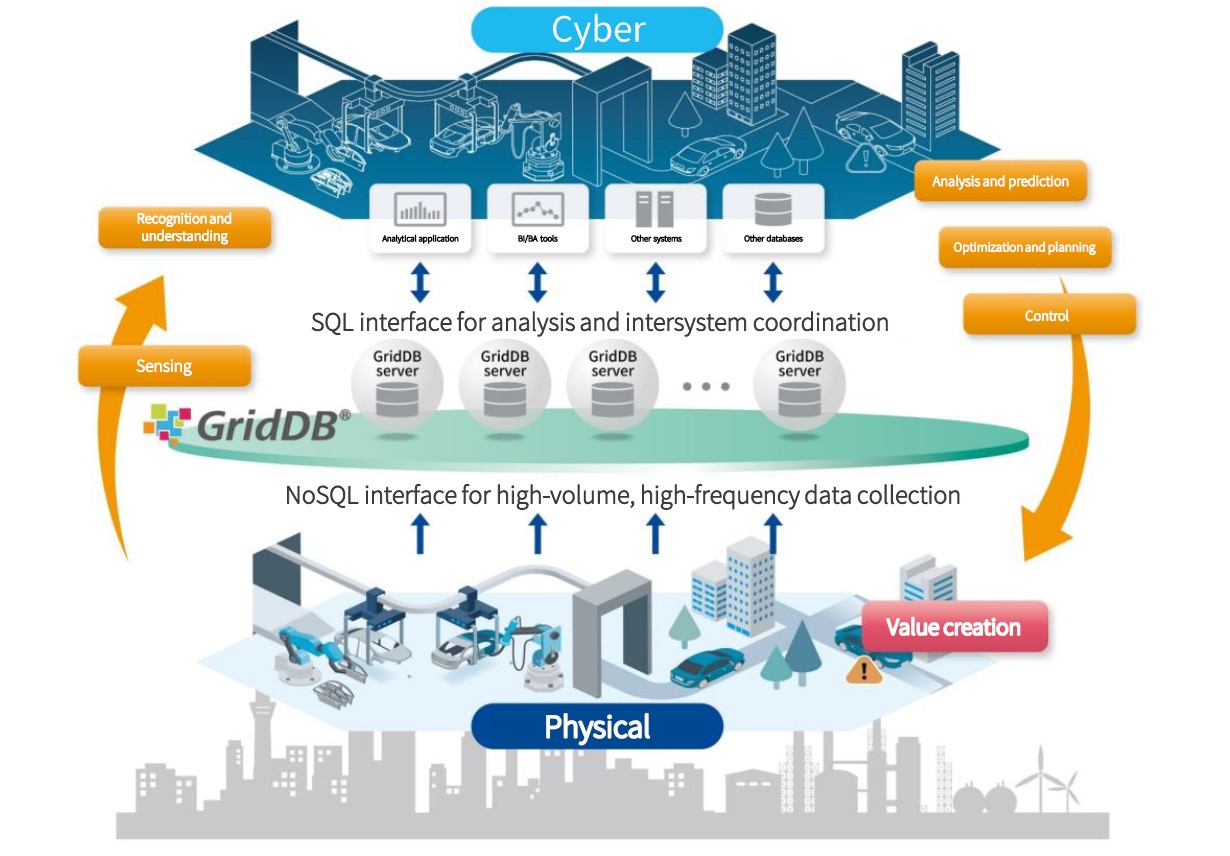
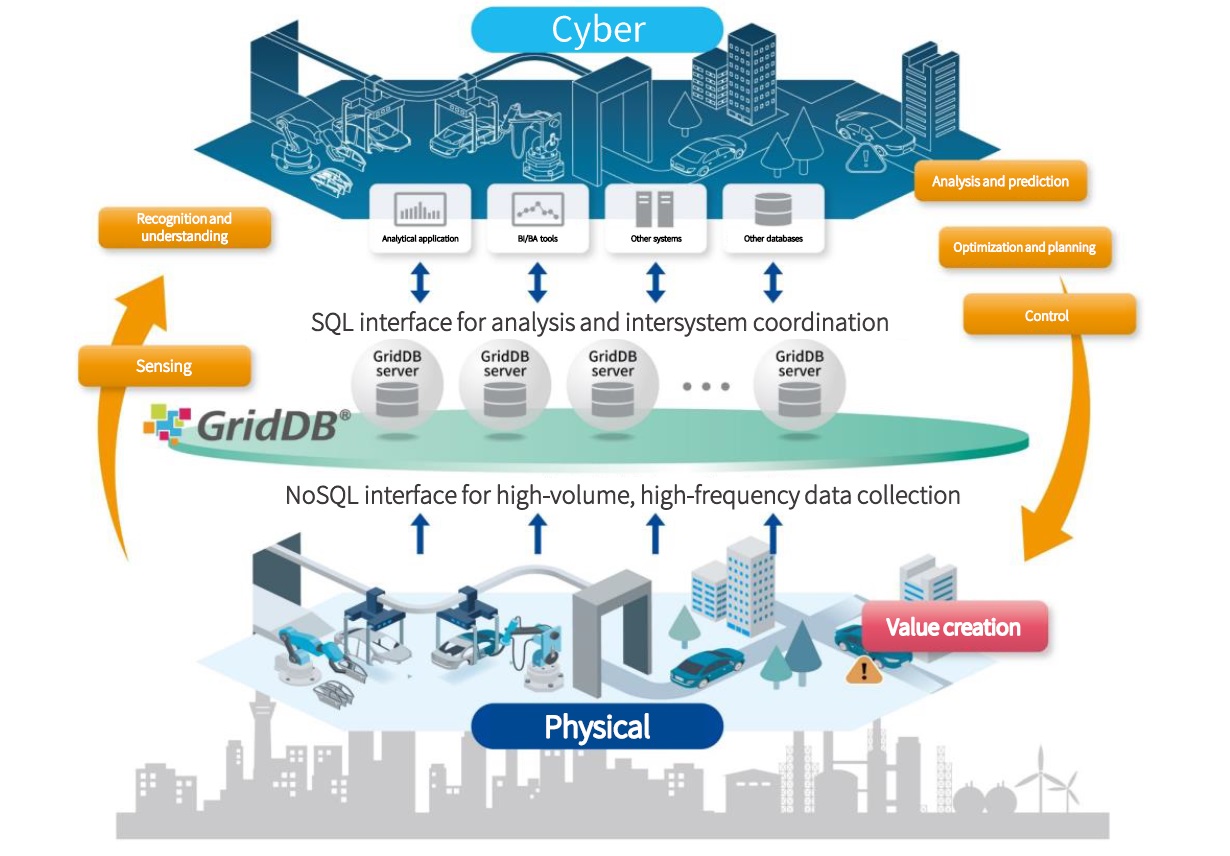
Optimized for Time Series Data and Multi-Model support
Multi-model architecture capable of supporting various data stores with time-series data-oriented and pluggable data stores for efficient real-time processing and management of huge amounts of time-series data at high frequency*.
*In the future, the system will support not only row-oriented stores suitable for registration and updating, but also column-oriented stores suitable for data analysis and object stores suitable for unstructured data representation.。

Petabyte-Scale Performance for Big Data System
Various architectural innovations, such as in-memory orientation with "memory as the main unit and disk as the secondary unit" and event-driven design with minimal overhead, have been incorporated to achieve processing capabilities that can handle petabyte-scale applications.

Highly Available and Reliable
High reliability for non-stop operation in the event of failure or server expansion, and flexible scalability to scale up or down as well as scale out or in according to requirements.

Developers Friendly
SQL interface as well as NoSQL interface, enabling real-time processing in SQL while collecting large amounts of data in NoSQL
Lineup

GridDB
Community Edition
GridDB is an open source database designed to store large amount of time series data in real time.

GridDB
Enterprise Edition
The best way to run GridDB in a production environment. Equipped with advanced security and professional support.

GridDB Cloud
Fully managed GridDB as-a-service deployed on the cloud. Our experts take care of troublesome database maintenance for you.
 Top
TopDifferent products for your needs
| Item |
Functionality |
GridDB Cloud | ||
|---|---|---|---|---|
| Support |
✓ | ✓ | ||
| Professional Service |
✓ | ✓ | ||
| Data Management |
Time Series Container |
✓ | ✓ | ✓ |
| Collection Container |
✓ | ✓ | ✓ | |
| Tree Index |
✓ | ✓ | ✓ | |
| Data Affinity |
✓ | ✓ | ✓ | |
| Table Partitioning |
✓ | ✓ | ✓ | |
| Query Language |
TQL | ✓ | ✓ | ✓ |
| SQL | ✓ | ✓ |
✓ | |
| NoSQL Interface |
Java | ✓ | ✓ | ✓ |
| C | ✓ | ✓ | ✓ | |
| NewSQL(SQL) Interface |
JDBC | ✓ | ✓ | ✓ |
| ODBC | ✓ | ✓ | ||
| WebAPI | ✓ | ✓ | ✓ | |
| Time Series Data |
Time Series Analysis |
✓ | ✓ | ✓ |
| Expiry Release (Data Retention) |
✓ | ✓ | ✓ | |
| Clustering |
Cluster Configuration |
✓ | ✓ | |
| Distributed Data Management |
✓ | ✓ | ||
| Replication |
✓ | ✓ | ||
| Administration |
Rolling Upgrade |
✓ | ||
| Online Backup |
✓ | ✓ | ||
| Export/Import |
✓ | ✓ | ✓ | |
| Operation Management GUI |
✓ | ✓ | ||
| Operation Command |
✓ | ✓ | ✓ | |
| Security |
Data-In-Transit (TLS/SSL) |
✓ | ✓ | |
| Authentication (LDAP) |
✓ | |||
| On Premise | On Premise | ✓ | ✓ | |
| Cloud Service | Cloud Service | ✓ | ||
| Item |
Functionality |
GridDB Cloud | ||
|---|---|---|---|---|
| Support |
✓ | ✓ | ||
| Professional Service |
✓ | ✓ | ||
| Data Management |
Time Series Container |
✓ | ✓ | ✓ |
| Collection Container |
✓ | ✓ | ✓ | |
| Tree Index |
✓ | ✓ | ✓ | |
| Data Affinity |
✓ | ✓ | ✓ | |
| Table Partitioning |
✓ | ✓ | ✓ | |
| Query Language |
TQL | ✓ | ✓ | ✓ |
| SQL | ✓ | ✓ |
✓ | |
| NoSQL Interface |
Java | ✓ | ✓ | ✓ |
| C | ✓ | ✓ | ✓ | |
| NewSQL(SQL) Interface |
JDBC | ✓ | ✓ | ✓ |
| ODBC | ✓ | ✓ | ||
| WebAPI | ✓ | ✓ | ✓ | |
| Time Series Data |
Time Series Analysis |
✓ | ✓ | ✓ |
| Expiry Release (Data Retention) |
✓ | ✓ | ✓ | |
| Clustering |
Cluster Configuration |
✓ | ✓ | |
| Distributed Data Management |
✓ | ✓ | ||
| Replication |
✓ | ✓ | ||
| Administration |
Rolling Upgrade |
✓ | ||
| Online Backup |
✓ | ✓ | ||
| Export/Import |
✓ | ✓ | ✓ | |
| Operation Management GUI |
✓ | ✓ | ||
| Operation Command |
✓ | ✓ | ✓ | |
| Security |
Data-In-Transit (TLS/SSL) |
✓ | ✓ | |
| Authentication (LDAP) |
✓ | |||
| On Premise | On Premise | ✓ | ✓ | |
| Cloud Service | Cloud Service | ✓ | ||
Download GridDB Community Edition here
Notes
The following condition apply to Community Edition:
・Server
- Multi nodes configuration is not available.
・Administration
- Operation commands are limited.
- For example, full backup, differential / incremental backup, archive storage, etc. cannot be used.
・C client(C API)
- Spatial data is not supported.