
知能化システム
製品の異常を画像から世界トップレベルの精度で検知する異常検知AIを開発
-検査対象の外観が部位や製品の種類によって異なる場合においても
高精度に異常を検知、様々な製造現場の生産性向上に貢献-
2020年12月14日
株式会社東芝
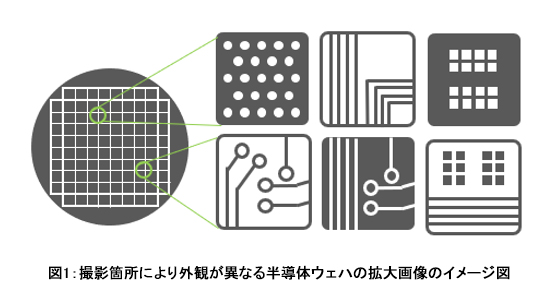
当社は、製造現場における製品の外観画像を用いた異常検知AIの開発において、公開データ(注1)での検知精度(注2)を従来技術(注3)の69.5%から79.1%と約10ポイント向上し、世界トップレベルの検知性能を達成することに成功しました。独自の深層学習手法を用いることにより、製造現場では収集が困難な異常データを使用することなく正常データのみから高い精度で学習し、検査対象の外観が、撮影した部位や製品の種類によって異なる場合(図1)においても高精度に異常を検知します。本AIにより、従来目視で行っていた半導体ウェハの品質検査等の自動化が期待でき、製造現場における生産性の向上に貢献します。
当社は、本技術の詳細を、12月14日から17日にかけてオンラインで開催される第19回ICMLA2020(19th IEEE international Conference on Machine Learning and Applications)で発表します。
近年、製造現場では、AIを活用し製品の歩留まりを改善するといった生産性向上の取り組みが進んでいます。製造部門向けAIの市場は、2020年の11億ドルから2026年には約15倍の167億ドルに成長すると予測されています(注4)。
製造現場における製品の外観画像を用いた異常検知においては、そもそも製品の異常の発生頻度が低く異常データの収集が困難であるため、正常データのみから学習する手法が求められます。異常データを必要としない手法の一つとして、基準となる正常データとの差分を検知するものがあります。この手法は、ボルトやナットのように部品を固定の画角・構図で撮影できる場合には有効ですが、図1のような検査対象の外観が、撮影した部位や製品の種類によって異なる場合においては、基準となる正常データを準備することができず、適用が困難です。例えば、半導体ウェハの欠陥検査ではウェハ上の複数個所を撮影し、その拡大画像から欠陥となる塵や傷の有無を確認します。撮影箇所の外観は撮影した部位や製品の種類によって異なり、塵や傷の形状も多種多様であることから、一つの見本(正解)に対する正誤で欠陥の有無が判定できないという状況があります。
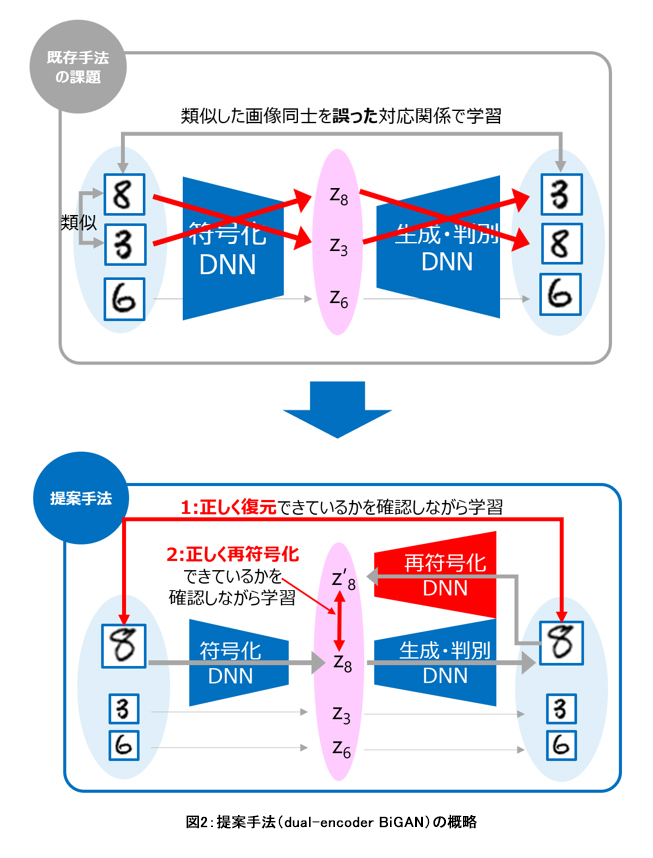
こういった状況に対応する深層学習を用いた技術として、正常データのみから「正常データらしさ」を学習するAIを使用する手法があります。この手法では、画像データから画像の特徴を潜在変数に数値化(符号化)し、それを再度画像データに復元します。正常データのみを用いて学習したAIでは、異常データは正しく復元できません。そのため、入力時と復元時の画像データの差から、撮影した部位や製品の種類によって状況が異なる場合においても異常検知につなげることができます。一方で、類似した画像同士を誤った潜在変数に対応づけて学習してしまうことがあり、正常データを正確に復元出来ず、検知精度が十分ではありません。
そこで当社は、正常な画像データの復元性能を大幅に改善する独自のdual-encoder BiGAN手法を用いた深層学習AIを開発しました。本AIは、潜在変数から復元された画像データを再度潜在変数に数値化(再符号化)し、2つの潜在変数が一致するような制約を課して学習します。従来の、入力時と復元時の画像データの比較をより厳密にすることに加え、潜在変数の比較も行うことで、撮影した部位や製品の種類によって状況が異なる場合においてもより高い精度で画像を復元させ、高精度に異常を検知することに成功しました。
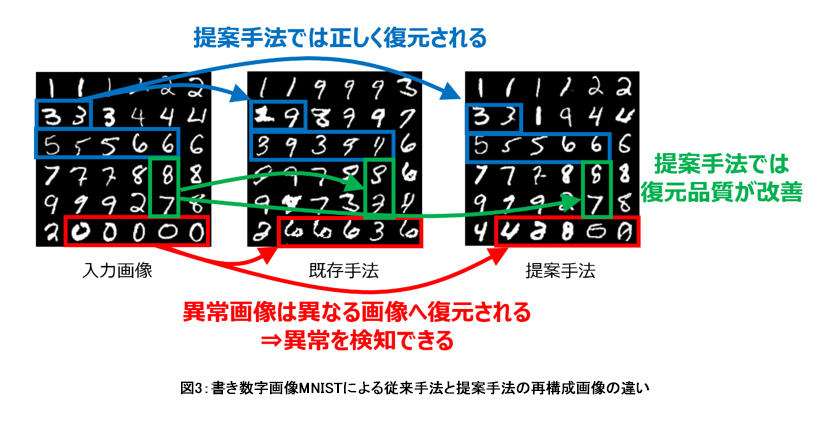
本AIを使用し、世界共通の手書き数字画像の公開データで異常検知を実施したところ、検知精度が従来の69.5%から79.1%に改善し(図3)、世界トップレベルの性能を達成しました。また、社内の半導体製造工場で収集した検査画像に対しても、50.5%から91.6%へと検知性能を改善しました。今後、様々な検査工程・製品にも適用し、性能実証を行います。
当社は、本AIを2021年度に東芝デバイス&ストレージ株式会社傘下の半導体製造工場の画像検査工程に適用する計画です。高精度な異常検知を実現することで、欠陥品検知作業を効率化し、歩留まりの改善に貢献していきます。また、当社グループの製造現場で培った実績をもとに、東芝デジタルソリューションズ株式会社の製造業向けソリューション「Meisterシリーズ」への展開をすすめていきます。
(注1)MNIST:AIの性能検証で使用される代表的なデータセット。0~9の手書き数字のデータ。
http://yann.lecun.com/exdb/mnist/ (Yann LeCun)
(注2)数字1~9を正常データとして学習し未学習の0を異常データとして検知するAIにおいて、全異常データの中で正しく異常と判定した割合を、1~9それぞれの数字を異常データとした場合も含めた10通りで算出し、それらを平均した値を異常検知精度としている。
(注3)BiGAN : Zenati et al. "Efficient gan-based anomaly detection." arXiv preprint arXiv:1802.06222 (2018).
(注4)https://www.value-press.com/pressrelease/252857(株式会社バリュープレス)