
Toshiba Develops a Dedicated Massively Parallel Processing Circuit
for Simulated Bifurcation Algorithms
-Provides real time combinatorial optimization solutions in rapidly changing environments
and solves problems related to finance, robotics, logistics, and drug development-
Toshiba Corporation
TOKYO─Toshiba Corporation (TOKYO: 6502) has reinforced its position in the vanguard of solving complex combinatorial optimization problems with the release of a dedicated large-scale parallel processing circuit(Note 1) that maximizes the high-speed performance of the company's simulated bifurcation (SB) algorithm.
In April this year, Toshiba announced its SB algorithm as a highly parallelizable solution that is scalable on current computers. The algorithm delivers high-quality approximate solutions (good solutions) for large-scale, complex combinatorial optimization problems in a short time, in diverse fields, from finance to transportation.
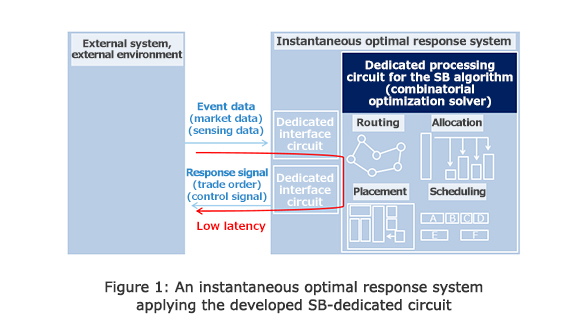
Installation of the newly developed circuit builds on the early achievement by supporting large-scale parallel computations and faster calculations of good solutions. Further, because the circuit is not controlled by software running on a general-purpose processor, it allows construction of an instantaneous optimal response system (Figure 1) that can detect changes in the external environment and select good solutions that reflect changes within a huge range of possibilities in extremely short times of less than 0.001 seconds.
For example, when conducting financial transactions in continually changing market conditions, more profitable transactions can be found instantly among a huge number of combinations. In industrial applications, robots will be able to assess their surrounding conditions and select the most efficient operations in real time.
Details of the new circuit(Note 1) were announced on September 9 at the IEEE's FPL 2019 Conference in Barcelona, Spain.
Combinatorial optimization can be applied to many problems in order to increase productivity in social and industrial systems, including optimization of financial portfolios, optimization of industrial robot operations, optimization of logistics and travel routes to improve delivery efficiency, mitigation of traffic congestion, and molecular design for drug discovery. Combinatorial optimization has long been recognized as economically important problem. However, as the scale of problems grows, combination patterns increase exponentially in a "combinatorial explosion" that makes finding solutions very difficult on current computers. Many technologies have been developed in response, including quantum computers(Note 2) and coherent Ising machines(Note 3). Toshiba has also announced its own quantum computer, the quantum bifurcation machine(Note 4), and its SB algorithm,(Note 5,6) which extends quantum theory to classical dynamics and enables optimization at the world's highest speeds and largest scales.
Innovations in solving combinatorial optimization problems allow the most appropriate judgments to be instantaneously made and subsequent actions to be determined, even in systems requiring ultra-fast real-time responses. Achieving this requires not only calculation processing time for solving problems, but also ultra-low latency to significantly shorten response times, including data input and output and system control times. Combinatorial optimization solutions must also meet stringent system requirements such as power consumption, stability, and flexibility..
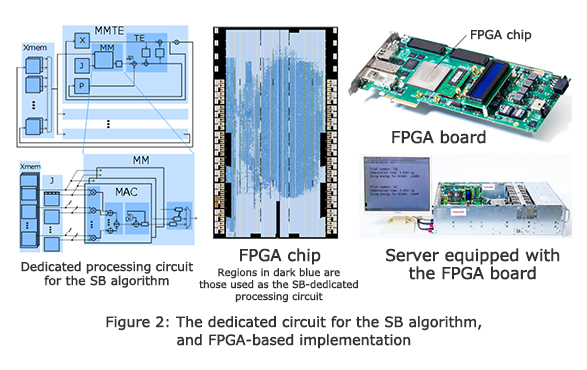
Toshiba has expressly addressed these issues by developing a dedicated circuit for hardware processing of the SB algorithm: a large-scale parallel processing circuit designed using the circuit techniques of spatial parallelization and temporal parallelization based on the parallelism analysis to determine arithmetic operations that can be simultaneously executed (Figure 2). Optimizing the circuit at the finest level for each clock cycle and per-bit data, has achieved both high-speed processing and power saving performance.
The new circuit does not require control by software processing, which can increase response times and fluctuations. The circuit takes a problem as input and then outputs a good solution calculated after a specified calculation time, determined at the time of design. To attain ultra-low latency at levels less than 0.001 seconds, it is essential to provide both a high-speed optimization circuit and but also dedicated interface, plus other circuits according to the application. The high-speed optimization circuit has been written in a high-level synthesis language that enables describing circuits at a higher level of abstraction than conventional hardware description languages, allowing the interface to be more flexibly changed and directly connected to peripheral dedicated circuits.
The new circuit can be implemented on commercially available field-programmable gate arrays (FPGA)(Note 7) and requires no special peripheral equipment such as refrigerators. Further, its processing performance (i.e. circuit scale) can be more flexibly changed, and it is possible to select an implementation method with optimal cost according to the delay performance required in the target system. This circuit is thus a highly flexible system component.
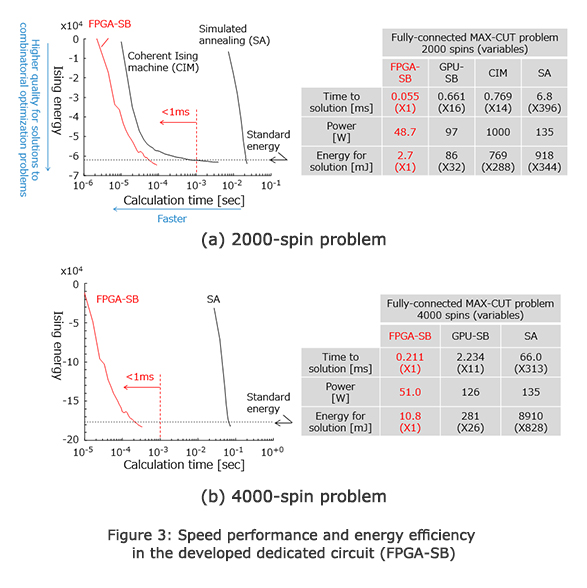
Implemented on a 20-nm-generation FPGA(Note 7), the circuit can handle combinatorial optimization problems with up to 4,096 fully coupled variables (approximately 8 million connections). As Figure 3 shows, this implementation is approximately four times the size of Toshiba's previously announced FPGA implementation, and it is 11% faster, and it can obtain a good solution to problems with 4,000 fully coupled variables in 0.211ms. Further, the solution is obtained with power consumption of only 51W power and 10.8mJ of energy. This is 11 times faster and 26 times more energy efficient than running the SB algorithm on GPUs(Note 8) (general-purpose parallel processors), and 313 times faster and 828 times more energy efficient than the conventional simulated annealing method(Note 9).
This technology makes it possible to build combinatorial optimization solutions that can respond in real time to rapidly changing environments in applications such as financial transactions and industrial robots.
Toshiba is proceeding with research and development of a proof-of-concept system that demonstrates the concept of a field-specific real-time response system that applies the developed circuit to rapidly solve combinatorial optimization problems, with the aim of announcing the system within 2019.
- (Note 1)
- K. Tatsumura, A. R. Dixon, H. Goto, "FPGA-based Simulated Bifurcation Machine," The International Conference on Field-Programmable Logic and Applications (FPL), pp.59-66 (2019) https://ieeexplore.ieee.org/document/8892209 (IEEE)
- (Note 2)
- M. W. Johnson et al., Nature 473, 194 (2011).
- (Note 3)
- T. Inagaki et al., Science 354, 603 (2016). https://www.jst.go.jp/impact/hp_yamamoto/en/overview/index3.html (Japan Science and Technology Agency)
- (Note 4)
- H. Goto, "Bifurcation-based adiabatic quantum computation with a nonlinear oscillator network," Scientific Reports 6, 21686 (2016).
- (Note 5)
- Development of an innovative algorithm that enable world-fastest and largest-scale combination optimization: Building a service platform that can quickly solve problems in logistics and drug discovery, https://www.global.toshiba/ww/technology/corporate/rdc/rd/topics/19/1904_01.html
H. Goto, K. Tatsumura, A. R. Dixon, "Combinatorial optimization by simulating adiabatic bifurcations in nonlinear Hamiltonian systems," Sci. Adv. 5, eaav2372 (2019). - (Note 6)
- [Toshiba Digital Solutions] Toshiba Digital Solutions Corporation's Simulated Bifurcation Machine, Software Enabling Massive Combinatorial Optimization at High Speed, Now Available on AWS Marketplace: - Company starting a demonstration experiment towards solving problems in diverse fields -, https://www.toshiba-sol.co.jp/en/news/detail/20190717.htm (toshiba digital solutions corporation)
- (Note 7)
- Field-programmable gate array: A type of arithmetic processing integrated circuit that allows users to rewrite functions after manufacturing according to the application. When using an Intel Arria10 GX1150 FPGA fabricated using 20-nm-generation semiconductor processes.
- (Note 8)
- Graphics processing unit: An integrated circuit including a large number of arithmetic processing units for image processing and other purposes.
- (Note 9)
- Value according to the simulated annealing method implemented on the CPU by Toshiba. Power consumption according to the thermal design power (TDP) value of the CPU used.