
News Releases
Toshiba’s Compaction Technology for Deep Neural Networks Opens Way to High Accuracy Recognition Processing on Edge Devices
- Toward Self-Learning AI from Manually Applied AI -TOKYO―Toshiba Corporation (TOKYO:6502) and the Institute of Physical and Chemical Research (RIKEN) have developed technology for compacting deep neural networks (DNN) obtained by deep learning. The technology reduces the parameter yielded resulting from the learning process by 80% while maintaining DNN performance, and opens the way to implementing highly accurate recognition processes for speech and images and the like on edge devices.
The technology was developed by the RIKEN AIP-Toshiba Collaboration Center, established in April 2017 to accelerate practical applications of basic research into innovative next-generation AI technology. Details will be presented at the IEEE International Conference on Machine Learning and Applications (ICMLA) 2018 in Orlando, Florida, from December 17 to 20 2018.
Neural networks, a core AI technology, are calculation modeled on the human brain and designed to recognize cluster and classify patterns. Recent advances have seen the development of multilayer DNN with increasingly more processing layers between the input and output layers. Such DNN can perform ever more sophisticated and larger scale recognition are seen as delivering higher accuracy than those derived from conventional approaches, which require manual setting of feature extractions. DNN are being considered to use in various applications, from speech recognition and machine translation to image recognition for autonomous driving.
As DNN that deliver higher performance have more layers, they tend to be larger in scale and more complex, and difficult to implement on hardware with only limited computational power and memory capacity, such as edge devices. While there have been multiple proposals for compacting large-scale DNN to achieve practical application, those have been requiring special constraints on learning DNN, or post-processing for identifying and deleting parameters with low importance.
In investigating DNN, Toshiba discovered a “group sparse phenomenon:” the automatic convergence of some parameters of a DNN towards zero, and Toshiba and RIKEN subsequently examined and explained the principles under which it occurs, and confirmed that the parameters that converge on zero after learning also have no effect on recognition results. They were able to compact large-scale DNN by deleting those parameters (Fig. 1).
Experiments using open datasets confirmed the ability to reduce the number of parameters by about 80% while keeping the classification error rate at a lower level than achieved by conventional methods (Fig. 2). Toshiba and RIKEN also demonstrated that the number of parameters converging to zero can be changed depending on the strength of the regularization function, bringing additional flexibility to changing DNN size (Fig. 3).
Toshiba and RIKEN discovered that the group sparse phenomenon occurs in conditions where ReLU*1 is used as the activation function, L2 normalization of parameters is applied as the regularization function*2, and Adam*3 is used as the optimization method. Even though these are generally used learning conditions, the occurrence of the group sparse phenomenon was not previously observed or reported.
The technology can be implemented by performing learning under general conditions and then deleting unneeded parameters. These is no need for special constraints during learning, or to identify and delete parameters with low importance after learning, as conventionally required. DNN can now easily be compacted.
Toshiba and RIKEN will continue to promote R&D for the utilization of advanced DNN in diverse embedded equipment and edge devices, such as image recognition systems for autonomous driving, and aim for practical application of the technology in the next two to three years.
-
Note:
- *1
- Rectified linear unit. A nonlinear function that is generally introduced to increase the expressiveness of DNNs.
- *2
- L2 regularization function. A function that is introduced to reduce overfitting to training data and that keeps parameter values small. The effect is greater as the regularization function becomes stronger.
- *3
- Adaptive moment estimation. A parameter optimization method, known as the stochastic gradient descent method.
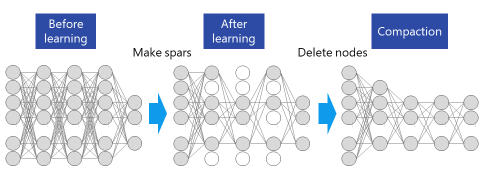
(Figure 1) Schematic diagram of DNN compaction using this technology. Compaction is possible simply by deleting the sparse parameters.
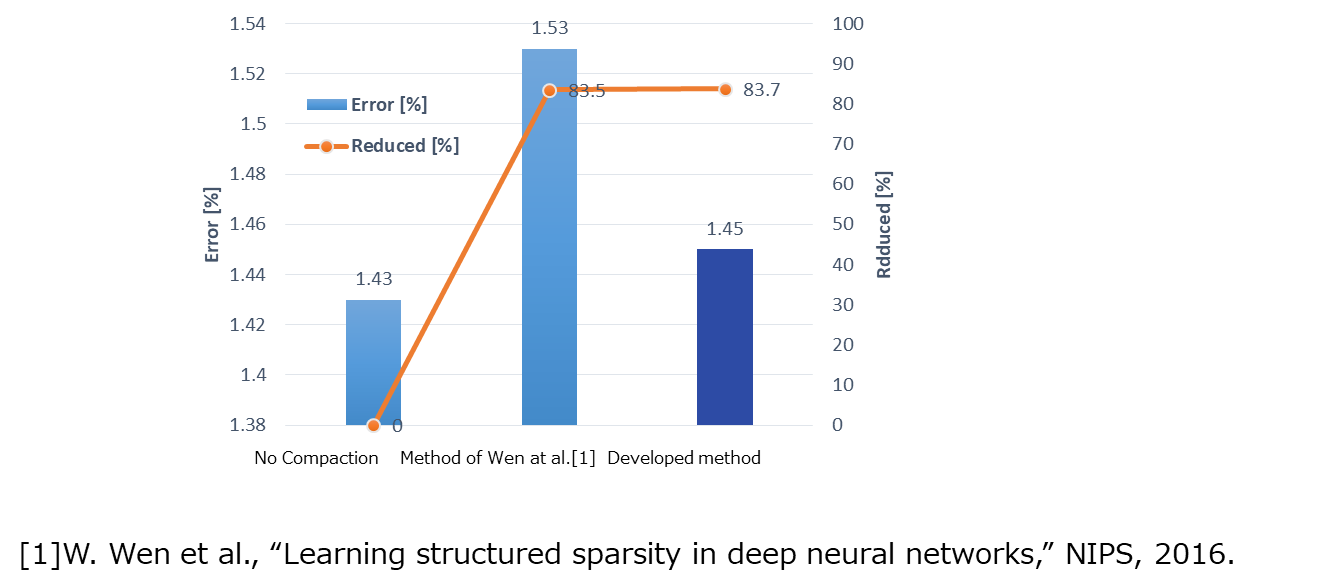
(Figure 2) In experiments using a 4-layer fully connected network and the MNIST dataset of images of hand-written digits (“0” to “9,” 10 classes), it was found that the number of parameters could be reduced by 83.7% while the misclassification rate increased by only 0.02% compared with a network without compaction.
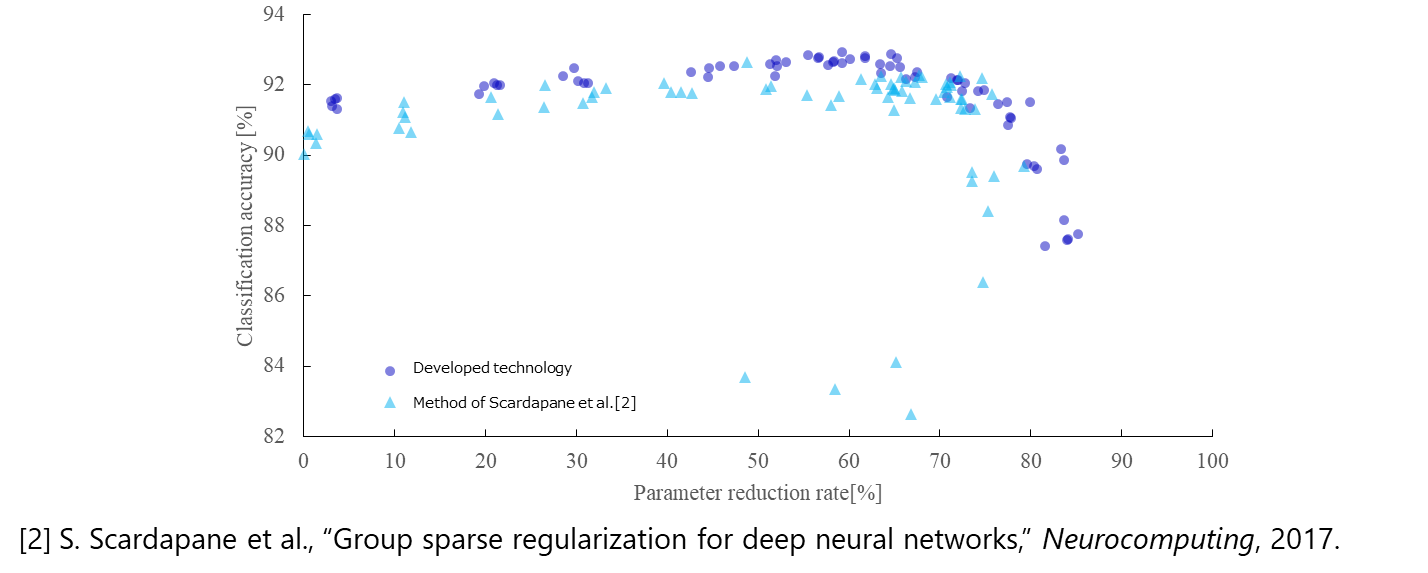
(Figure 3) In experiments using a 16-layer convolutional neural network and the CIFAR-10 image dataset that is often used for benchmarking general object classification, it was found that the number of parameters in the network could be reduced by around 30% to 70% in the range where classification accuracy is degraded by less than about 1%, and the DNN size could be flexibly changed by changing the strength of the regularization function.