

As objects around the world are increasingly being connected to the Internet of Things (IoT), more and more attention is being drawn to cyber-physical systems (CPS). CPSs are systems that collect diverse information from IoT devices and sensors in the real world (physical space) and analyze them in real-time in the virtual world (cyberspace) using large-scale data processing technologies, etc. The information and value created in the virtual world are then returned to the real world to stimulate industry and help solve social problems. In this three-part series, we will explain the data platform technologies essential for creating CPSs and the database management system (DBMS) at the core of the data platform.
Part 1 looked at the background that led to the creation of NoSQL rather than RDBMS, and GridDB, which is Toshiba's specialized database for big data and IoT systems. Among GridDB's core features, we also introduced the key container data model as GridDB’s unique data model. In Part 2, we will illustrate the features of the data platform technologies used by the constantly evolving GridDB and actual examples of the contributions GridDB has made to the utilization of petabyte-level manufacturing data.
Uninterrupted, high-speed, distributed processing of petabytes of time-series data
In general, the features of NoSQL DBMS, such as GridDB, can be explained in terms of the three elements of the CAP theorem: consistency (C), availability (A), and partition tolerance (P). As demonstrated in Part 1, the CAP theorem posits that no distributed systems can ever achieve all these three. GridDB is categorized as a CP database, prioritizing data consistency and system’s partition tolerance over availability. If a serious network failure causes a lack of consistency in data handling, the DBMS will stop operating. To maintain continuous DBMS operation, GridDB uses unique techniques to improve availability.
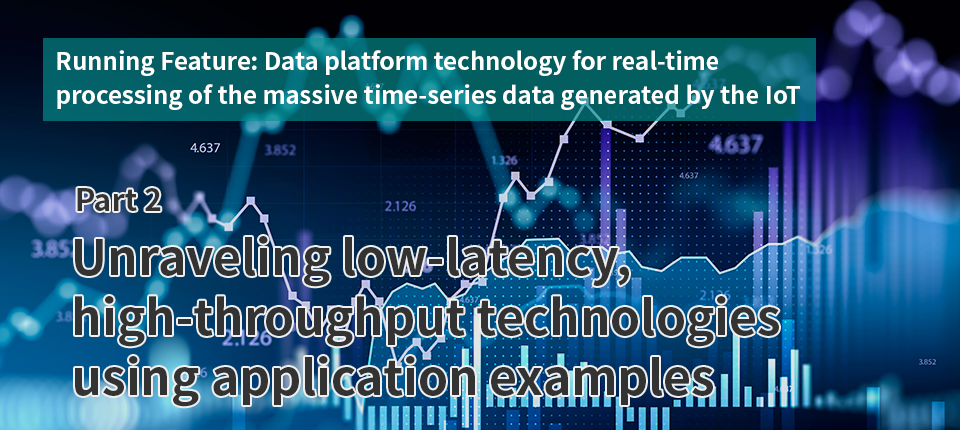
The core of these techniques is Autonomous Data Distribution Algorithm (ADDA). The data in a cluster is divided into units called cluster partitions, which are replicated and distributed across multiple nodes. Based on ADDA, cluster partition replicas are automatically redistributed during normal operation to maintain a balance between each node (Fig. 1).
This allows the DBMS to continue operating even if some of the nodes stop due to an anomaly because the automatic failover operation is completed in a very short time by utilizing the replicas optimally located on each node. Even in the unlikely event of a “split-brain,” where the network between nodes is divided, each node can make the decision to shut down its DBMS based on a quorum policy (a policy in which a cluster consisting of the majority of the nodes is considered the active cluster). This prevents the data from becoming inconsistent.
ADDA also provides benefits when adding new nodes. The "nonstop scale-out" functionality enables the addition of machines without stopping the DBMS. This has the potential to improve distributed processing performance commensurately. When a new node is added to expand the system's machine resources, data is automatically reallocated based on the ADDA, further distributing access to each item of data. This makes it possible to operate a petabyte-class database with high levels of reliability and processing performance just by combining the minimum number of general Intel Architecture (IA) servers or equivalent virtual machines (VMs) required for the amount of data.
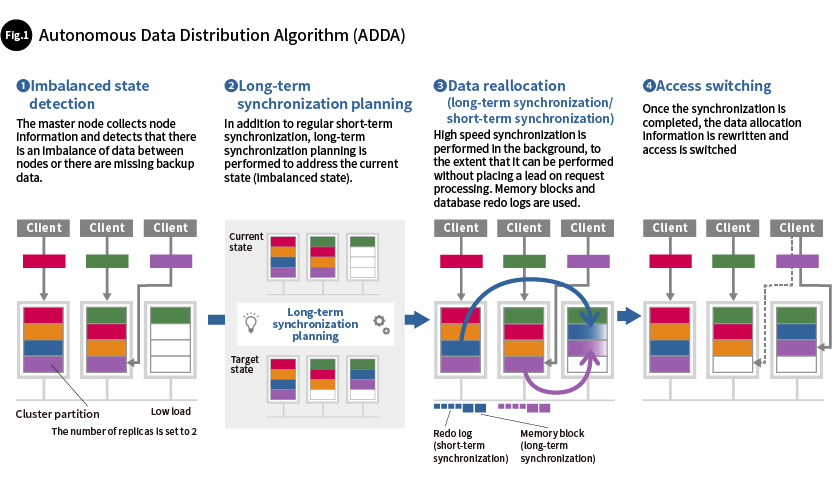
To further improve its reliability, GridDB also supports the functionality for forming clusters across multiple data centers within the same region and for backing up data to distant data centers (Fig. 2). Thanks to these functionalities, the IoT system can continue to operate even if an outage occurs in part or all of a data center. GridDB also provides three other functionalities that allow systems to operate even when a network specific to the customers, such as a private network in the cloud, is built: cluster configuration which does not require to use multicast packets*, route settings in which communication channels are set up according to their purposes, and Secure Socket Layer (SSL) connections.
* Multicast packets: Packets that are simultaneously sent to multiple machines in a network, containing the same data. GridDB uses multicast packets to easily manage lists of nodes that make up clusters. However, considering that some cloud services do not allow multicast packets due to constraints on network environments, GridDB supports alternate configuration functionalities.
Technologies for continually and efficiently storing time-series data
Among the systems that work with big data, IoT systems are especially likely to have data simultaneously generated on many edge devices connected to the system. Therefore, they require high capabilities for in-memory processing. In addition, it is essential that storage can be accessed efficiently over the long term, as IoT data is generated constantly, 24 hours a day, 7 days a week. GridDB excels in both of these areas.
First, GridDB's high level of in-memory processing performance is supported by its event-driven processing engine, which we have developed. GridDB allocates threads that process requests for each cluster partition and hence makes lock-free buffer processing possible, eliminating the need for buffer unit locks. Furthermore, there are database log processing functionalities that reduce the amount of writing to storage and high-speed replication processing functionalities, fully leveraging the capabilities of multicore CPUs and multi-CPU environments.
Next, to improve storage access over the long term, GridDB uses a time series data placement algorithm (TDPA) that makes maximal use of memory. Time-series data is placed in containers not in the order in which they were inserted but in the order of the time in which they occurred. This makes it possible to search more efficiently and to allocate data optimally across containers.
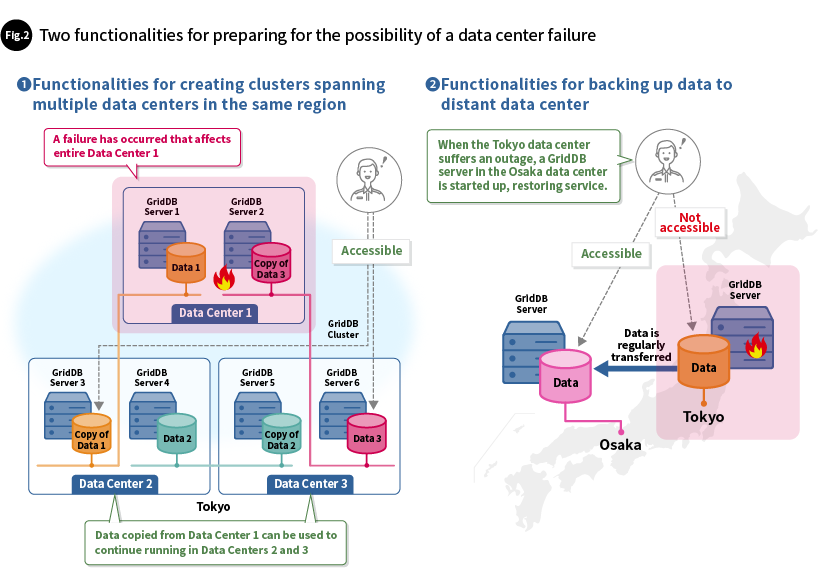
For example, with the key container data model used by GridDB, each sensor is assigned its own container, and the system handles multiple containers. One feature of this is that data that is chronologically close to other data can be placed in data blocks next to these other blocks, even if they are in different containers. This allows for a quick search of data in multiple sensors in the same time zone across containers and thereby improves the efficiency with which required data is read from storage. We have confirmed in actual benchmark testing that the system maintains its high level of processing performance over the long term (Fig. 3).
Furthermore, to maintain the high performance for storing and reading data for a longer period of time, GridDB supports the functionalities for splitting containers according to the time axes and placing them in multiple cluster partitions, for batch deleting old data for each division unit, and for assigning unique blocks to specific containers.
Dual interfaces that make real-time analysis even easier
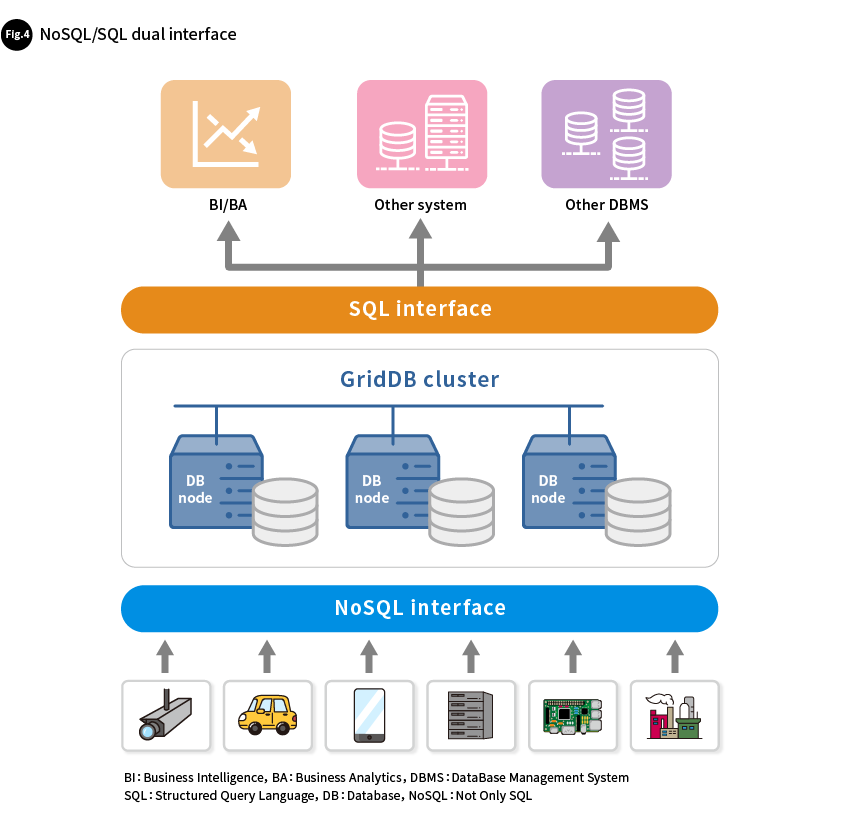
GridDB is a NoSQL database but has the same standard interfaces as an RDBMS. These two types of interfaces, called a dual interface, consist of a NoSQL interface that takes full advantage of GridDB's high speed and an SQL interface that makes advanced real-time analysis easy (Fig. 4).
Like a typical NoSQL DBMS, GridDB supports a its own application programming interface (API) as a NoSQL interface. The database client obtains the cluster configuration and contains its own system for interpreting it, and therefore data can be sent and received directly by specifying the node that manages the data, without needing to go through an intermediary server. Data is transferred in batches corresponding to each cluster partition, which are the units the data is segmented into, so GridDB connects directly to the event-driven processing engines within nodes, performing all processing with only a small amount of overhead. This produces low latency and high throughput, making it possible to efficiently store IoT data, for which large amounts are created simultaneously. GridDB supports various programming environments and APIs for Java/C/Python/Node.js/Go.
For its other SQL interface, it offers standard APIs such as Java DataBase Connectivity (JDBC) and Open DataBase Connectivity (ODBC), so SQL queries can be used with GridDB. A query execution plan which is optimized for distributed parallel processing is generated on the cluster node and the machine resources of each node are leveraged to their fullest to achieve high-speed processing. The SQL interface eliminates the need to extract data using batch processing before performing data analysis. Instead, up-to-the-minute data, which is constantly being stored, can be analyzed in real-time, just as with a data warehouse (DWH). GridDB also has standard APIs, so ordinary business intelligence (BI) tools can be used to easily analyze data without programming.
Furthermore, it has mechanisms for improving SQL parallel distributed processing performance. These include optimization based on filter conditions (predicate pushdown optimization), optimization for container partitioning and its placement and query-based scanning and joining (partition pruning optimization and partition-wise join optimization), and technologies for optimizing various query execution plans. It has a wide array of other SQL functions to assist with data analysis, including a window function (OVER clause) and distribution, median, and percentile functions.
In addition, GridDB provides a functionality (GROUP BY RANGE clause) for upsampling and downsampling at fixed intervals to analyze time-series data.* This functionality can be used, for example, on time-series data with missing data to use a single SQL statement to perform linear interpolation based on the data before and after the missing data.
* Standard SQL and common DBMS (MySQL, PostgreSQL, SQLite, Oracle, etc.) do not directly support GROUP BY RANGE clauses as a method of grouping data by specifying a range. However, although the process is somewhat complex, multiple syntaxes can be combined to accomplish what this functionality does.
Contributing to a high-level use of petabytes of IoT data
GridDB, which specializes in working with big data, especially from IoT systems, is in use in several actual worksites, primarily systems used in societal infrastructure and factories. Let's look at one example.
GridDB is adopted in the quality management system of a hard disk manufacturer to accumulate and analyze sensor data from manufacturing equipment over a long period of time so that the findings can be used to make product quality improvements. This system is intended to accumulate all data related to manufacturing and quality, which has amounted to 1.9 petabytes over the course of five years. Before the introduction of GridDB, the company used specialized database devices to analyze the large volume of data. However, these specialized devices were expensive, and the company found itself having to add more of these expensive database analysis devices to keep up with the amount of data, which was growing year by year. This presented the company with a major cost problem.
That is why the company decided to switch from using specialized database devices to GridDB, which could be configured as a cluster of ordinary IA servers. Switching to GridDB reduced expenses significantly, and the company has been using GridDB for roughly three years.
While the factory is in operation, sensor data is constantly being generated by the factory's manufacturing equipment. GridDB distributes this data based on the key container data model, accumulating the data while maintaining a good balance of data storage across multiple nodes. In parallel with this data accumulation, the company is also analyzing the data by using a distributed query execution plan to execute SQL statements. GridDB is enabling the company to use tried-and-trusted BI tools to analyze manufacturing data over a wider range and over a longer period of time. This improves the accuracy of the analyses and enables results to be used in advanced quality management. GridDB has highly reliable cluster processing technologies, technologies for accumulating and analyzing data in a way that enables long-term, high-speed processing, and diverse interfaces, so it has broadened the company's ability to leverage its petabytes of manufacturing data.
GridDB is also adopted in systems that require high reliability and high performance, such as the low-voltage wheeling operation systems used by power companies.
* This is introduced in detail in DiGiTAL T-SOUL Vol. 22.
In Part 2, we have presented the technical features of GridDB, which are suited for working with massive time-series data, and an example of how its strengths are being put to use. In Part 3, we will look at GridDB Cloud, a managed service based on all of our GridDB operation expertise, and at GridDB's open source software (OSS) activities.
Up next: (Part 3) Database cloud services and OSS activities that make the IoT easy for anyone to use!

HAMAGUCHI Taihei
Specialist
Group 2, Software Development Dept.
Software Systems Research and Development Center
Toshiba Digital Solutions Corporation
Since joining Toshiba, HAMAGUCHI Taihei has been involved in the research and development of database management systems and document management systems. He is currently engaged in the development of GridDB and other middleware.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of September 2023.
- GridDB is a registered trademark of Toshiba Digital Solutions Corporation in Japan.
- All other company names or product names mentioned in this article may be trademarks or registered trademarks of their respective companies.
>> Related information
Related articles
Running feature: Data platform technology for real-time processing of the massive time-series data generated by the IoT(Article list)

