


As objects around the world are increasingly being connected to the Internet of Things (IoT), more and more attention is being drawn to cyber-physical systems (CPS). CPSs are systems that collect diverse information from IoT devices and sensors in the real world (physical space) and analyze them in real-time in the virtual world (cyberspace) using large-scale data processing technologies, etc. The information and value created in the virtual world are then returned to the real world to stimulate industry and help solve social problems. In this three-part series, we will explain the data platform technologies essential for creating CPSs and the database management system (DBMS) at the core of the data platform.
Part 1 will look at the background that led to the creation of the NoSQL DBMS, which differs from conventional DBMSs, and GridDB, Toshiba’s database management system.
The different types of database management systems and the history behind them
We live in an era where data, whose volume is growing explosively, is being called on to be used to solve the problems faced by society. It would be no exaggeration to say that expansion of data usage is the product of the evolution of database management systems (DBMSs). To understand why, let’s look back at the history of the DBMS (Fig. 1).
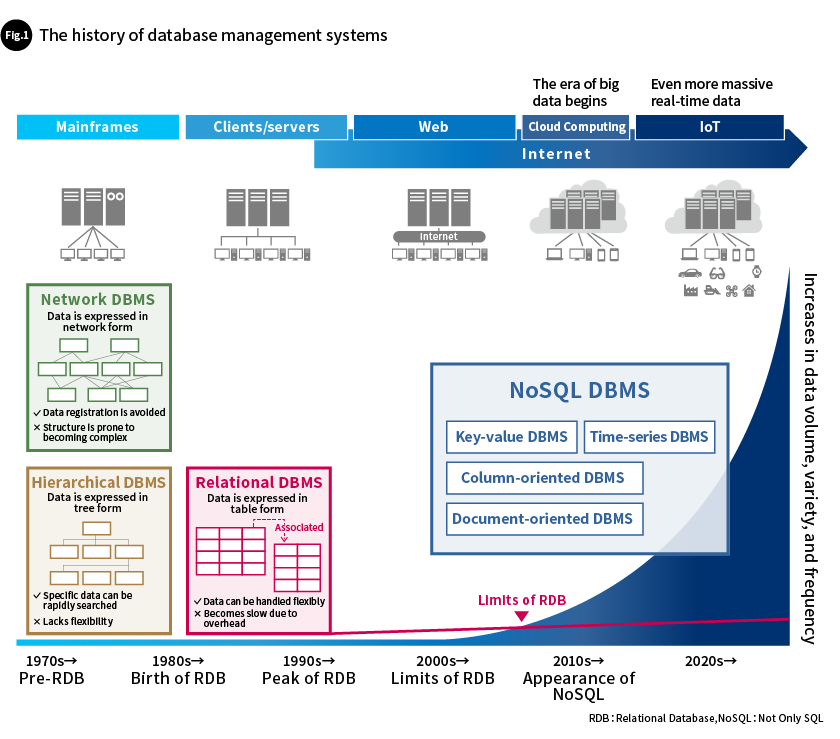
In the 1960s, data was primarily managed using file systems. However, it was saved in disparate parts across multiple file systems. This created problems such as duplication and a lack of consistency, and managing the data was no easy matter. The DBMS was developed as a solution to these problems. The following DBMS data models were created.
- Hierarchical database management system (Hierarchical DBMS)
Hierarchical database management systems are DBMSs that use hierarchical structures to manage data.
They were used primarily in large enterprise systems from the 1960s to the 1970s. These DBMSs are organized in hierarchies, in a tree structure, so they can express all related information. Each record can have multiple child records, but a child record cannot have multiple parent records. The data’s structure is fixed, so these DBMSs are easy to manage, but they lack flexibility and are incapable of expressing complex data interrelationships. - Network database management system (Network DBMS)
Network database management systems are DBMSs developed to replace hierarchical database management systems. They were used primarily in the fields of science & technology, and the manufacturing industries from the 1960s to the 1980s. In these databases, data is expressed using a network structure, so child elements can have multiple parent elements. In other words, each record can have multiple child records and multiple parent records. While this type of database can express more complex relationships between data than hierarchical database management systems, changing and updating data is difficult. Therefore, these systems were mostly used for specific applications and industries and were not commonly used. - Relational database management system (Relational DBMS (RDBMS))
Relational database management systems (RDBMSs) were based on the relational data model proposed by Edgar F. Codd in 1970 to address the shortcomings of the databases of the time. With this data model, data is expressed in the form of tables made up of rows and columns, and tables are associated with each other using keys. This approach makes it possible to flexibly express relationships between items of data and makes management easy. RDBMS supports Structured Query Language (SQL), a standard query language for looking up information in databases, so it greatly improves the process of writing database inquiries.
Although RDBMSs offer these features, initially they faced difficulty in operating efficiently due to hardware limitations, so they were not immediately adopted. Later, as computer hardware evolved, RDBMSs gradually became practical and started being deployed in commercial applications in the early 1980s. Ever since then, they have been the most common type of DBMS used for many databases.
In the 2010s, digital technologies such as the internet and sensor technologies made rapid advances, launching the age of big data. Big data acquired from the IoT or other means began to be processed and analyzed to produce new insights or make decisions more efficiently. However, RDBMSs encountered difficulty in handling the three big data features of volume (the amount of data), velocity (the speed at which data is input and output), and variety (the number of types of data and the range of data sources). A new type of database, called the Not Only SQL (NoSQL) database, was created as a database capable of dealing with these characteristics of big data.
How NoSQL DBMSs differ from RDBMSs
IoT systems collect, analyze, and control data from various devices and sensors that are mutually connected via the internet. This data has the following characteristics.
- High frequency generation: Data is sometimes generated with a high frequency, on the order of milliseconds or microseconds.
- Continuous generation: Most devices and sensors operate 24 hours a day, 365 days a year, so data is constantly being collected.
- Real-time usage: Data must be looked up and processed immediately after it is generated.
- High volume management: Large amounts of data are collected, and the amount of data tends to rise steadily.
These characteristics differ from those of the data used in transaction-based systems, such as business and product sales systems, that had heretofore been handled using RDBMSs. Therefore, RDBMSs were not well-suited to managing big data such as IoT data. Let’s look at the reasons for that in detail by comparing the differences between RDBMSs and NoSQL DBMSs (Fig. 2).
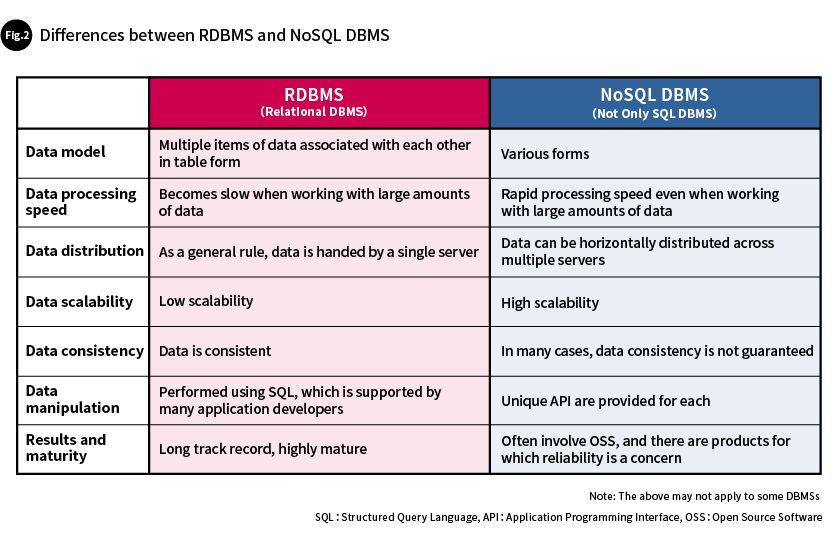
Data model
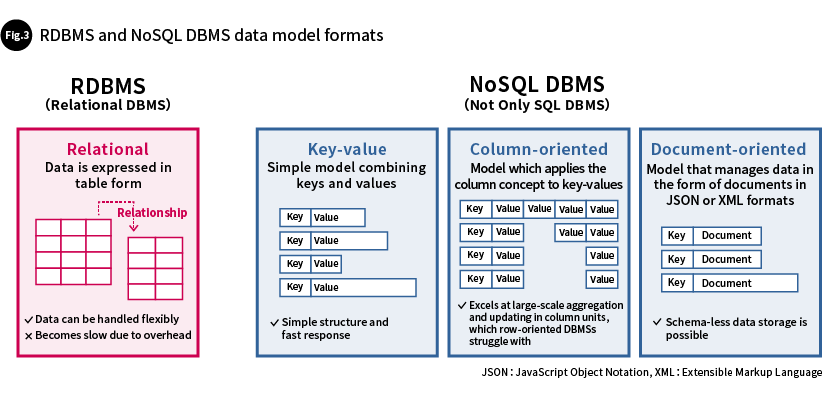
RDBMSs express data in the form of tables, and excel at handling multiple items of related data. On the other hand, most NoSQL DBMSs express data in self-contained data structures in which each element can independently exist. There are various types of data models, such as key-value, column-oriented, and document-oriented data models, which can be selected based on the characteristics of the data they will be used with (Fig. 3).
Data processing speed
RDBMSs excel at looking up multiple items of data associated with tables and at transaction processing. These require maintaining database integrity and consistency, which can cause overhead and slow data processing speeds when working with a large amount of data. NoSQL DBMS, on the other hand, has a simple structure. There is no need to look up multiple items of data or maintain consistency across tables, so processing can be performed quickly.
Data distribution and scalability
RDBMSs are designed to operate on a single server in order to maintain data consistency, so it is difficult to distribute data across multiple servers. In order to deal with the growing amount of data, servers must therefore be scaled up by replacing their hardware with higher performance hardware. On the other hand, NoSQL DBMSs place limits on the scopes of data consistency so that data can be horizontally distributed. Systems can be expanded simply by adding servers, which provides major cost benefits.
Data integrity
RDBMSs provide strong support for atomicity, consistency, isolation, and durability (ACID). If, for example, an error occurs during a transaction, the processing results will not be reflected in the database, preventing data contradictions and inconsistencies. NoSQL DBMSs, on the other hand, use a data integrity model that is based on the CAP theorem. The CAP theorem states that any given decentralized system can only achieve two of the following three: consistency, availability, and partition tolerance. In other words, NoSQL DBMSs select two whether to maintain consistency, availability, or partition tolerance in a decentralized system. While RDBMSs are focused on transaction reliability and thus maintain data consistency, NoSQL DBMSs are focused on flexibility and scalability, so data consistency may not be assured.
Data manipulation
RDBMSs have the advantage of being able to store, query, and update data using SQL, a standard query language that has long been supported by many application developers. NoSQL DBMSs, on the other hand, have unique application programming interfaces (APIs) and provide query languages appropriate for specific applications and data models.
RDBMSs are database management systems suited for use with traditional operation systems, which require structured data, transaction processing, and data consistency. NoSQL DBMSs, in contrast, are suited to the management of big data such as IoT data, which requires fast, scalable processing.
GridDB, a database that supports time-series data for big data and IoT systems
In the past, Toshiba has used RDBMSs to handle the data processing involved in recording and using device operating status data for social infrastructure systems, factory systems, and the like. This was the case in the days when the amount of data was on the order of several hundred megabytes to several terabytes. However, with the coming of the age of big data, the frequency with which data is generated has risen, and data volume has ballooned to anywhere from several hundred terabytes to several petabytes. It was clear that the data processing capabilities of RDBMSs were approaching their limits.
At the same time, the key-value and document-oriented data models used in NoSQL databases had difficulty with efficiently processing time-series data, which is generated at high frequency by the IoT. That is why we began developing GridDB, which combines the advantages of both approaches.
GridDB is a NoSQL time-series database specially designed for big data, especially IoT systems. In the real world, devices typically have multiple connected sensors, each of which gathers various data. To make this easy to model, we developed a "key container data model." This GridDB data model introduced "containers" (similar to RDBMS tables) as key-value values. With this unique data model, for example, device names could be set as keys, container columns could consist of time stamps, and rows could consist of values obtained from multiple sensors, from sensor 1 to sensor n, to store time-series data (Fig. 4).
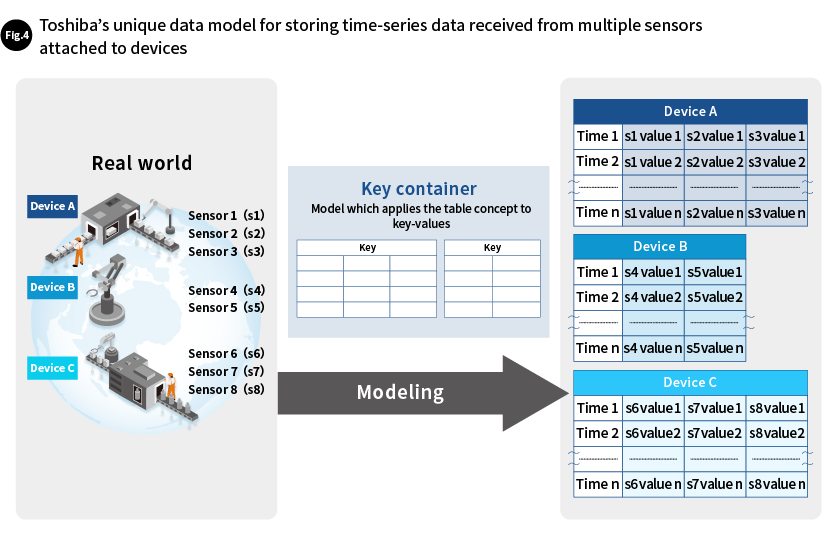
Furthermore, when storing time-series data, data can sometimes be lost due to network delays. With RDBMSs, this requires the preparation of another mechanism to make up for lost data. GridDB, on the other hand, comes with functions that automatically fill in missing data by using averages, median values, or moving averages based on stored data. It also has mechanisms for visualizing data in timeline form and for issuing alerts when threshold values are exceeded.
In Part 1 of this running feature, we have looked at the background that led to the creation of NoSQL and GridDB. In Part 2, we will cover the features of GridDB’s data platform technologies and examples of how it has been used, so don’t miss it.
Up next: (Part 2) Unraveling low-latency, high-throughput technologies using application examples

KURITA Masayoshi
Group 2
Managed Services Business Development Dept.
Digital Engineering Center
Toshiba Digital Solutions Corporation
Since joining Toshiba, KURITA Masayoshi has been involved in research and development of the software and middleware used in industrial computers and workstations, along with internet platforms, and in product planning for big data, AI, and machine learning platforms. He is currently engaging in product planning and promoting the widespread use of open source software.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of June 2023.
- GridDB is a registered trademark of Toshiba Digital Solutions Corporation in Japan.
- All other company names or product names mentioned in this article may be trademarks or registered trademarks of their respective companies.
>> Related information
Related articles
Running feature: Data platform technology for real-time processing of the massive time-series data generated by the IoT(Article list)

