
概要
当社は、効率的な金融取引、配送ルート計画など、様々な社会課題に現れる組合せ最適化問題を解く、世界最速の組合せ最適化計算機「シミュレーテッド分岐マシン™」(*1,2)の計算速度と規模(取扱い可能な最大問題サイズ)の両方を向上するスケールアウト(分散協調)技術を開発しました。スケールアウトはサーバーや計算チップ(*3)を増設することでシステム全体の処理能力を高める手法で、増設するほど処理能力を高めることが可能です。当社は、複数のチップを接続し、各チップが分散協調して処理を行うことで、従来困難だった、計算速度・規模の両方を向上しました。全結合型組合せ最適化計算機(*4)において世界で初めてスケールアウト性を実証しました(*5)。具体例としては、チップを8つ連結したシミュレーテッド分岐マシン™は、シングルチップ実装のものよりも速度が5倍、規模が16倍となります。本技術を、膨大な銘柄数の金融取引や複数のロボットの協調制御など、従来は困難だった高速・低遅延性と規模拡張の両立が必要な用途で活用することにより、より大規模で複雑な社会課題解決への貢献が期待されます。
本技術の成果は、2021年3月1日付(英国ロンドン時間)の英国オンライン科学雑誌「Nature Electronics」に掲載されました(*6)。
開発の背景
金融取引の最適化(*7)、産業用ロボットの動作の最適化、移動経路や送電経路の最適化など、社会や産業における課題の多くは、膨大な選択肢から最適なものを選び出す組合せ最適化に帰着します。組合せ最適化は、問題の規模が大きくなるにつれて組合せパターンの数が指数関数的に増大するため、既存の計算機で高速に解くことは困難です。このため、組合せ最適化の専用計算機の開発が国内外で活発に行われています。当社は、独自の量子コンピュータ理論から生まれ、全く新しい原理で組合せ最適化問題を解くシミュレーテッド分岐アルゴリズム(SBアルゴリズム)を発表しています(*1,2)。SBアルゴリズムは計算並列度が高いことが特長で、そのアルゴリズムを専用に処理する超並列処理回路(*8)として実装した場合に特に優れた高速性・低遅延性を発揮します。この専用回路を実装したシミュレーテッド分岐マシン™は、金融システムや産業用ロボット、動画処理など高速なリアルタイム応答が求められる用途において活躍が期待されますが、これまで取り扱い可能な組合せ最適化問題のサイズが計算チップのメモリ容量に制限されてしまうことが課題でした。
本技術の特徴
そこで当社は、複数のチップを接続し、各チップが分散協調処理することでシミュレーテッド分岐マシン™の計算速度と規模の両方を向上するスケールアウト技術(*9、図1a)を開発しました。
一般の組合せ最適化問題はイジング問題という形式(図1b)に変換することが可能であり、近年活発に開発されている組合せ最適化計算機の多くはイジング問題を高速に解くイジングマシンです。イジングマシンの中でも全結合型は、すべてのスピン変数が互いに相互作用することを可能とする方式であり、問題をイジング形式に変換する際の制約が少なく、実用性が高いとされます(*11)。一方、全結合型はその複雑なスピンの相互作用のために、1つの大きな問題を複数のチップで分割して扱うことが難しいとされていました(図1b)。
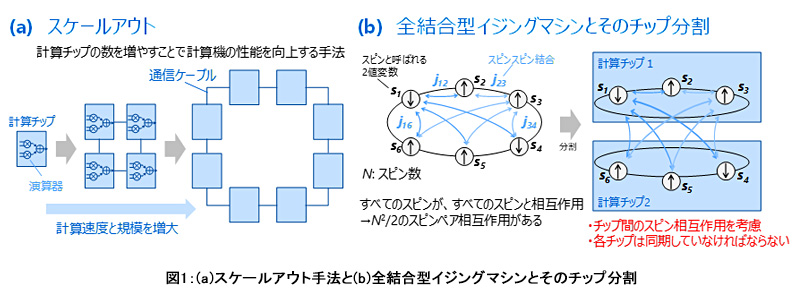
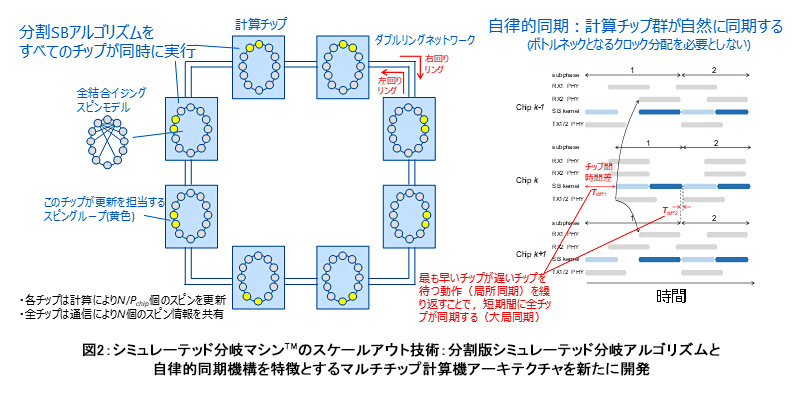
今回、SBアルゴリズムの高い計算並列性に着目し、全結合型イジング問題に適応可能な分割版シミュレーテッド分岐アルゴリズム(分割SBアルゴリズム)を開発しました(図2)。複数の計算チップは同時に分割SBアルゴリズムを実行します。全スピン数(問題サイズ)をN、チップ数をPchipとしたとき、各計算チップはN/Pchip個のスピンの更新を担当します。各チップは、相互にスピン情報を交換することですべてのスピンの最新情報を共有し、その情報を使って複雑なスピン相互作用を計算し、さらにそのスピン相互作用に基づき自身が担当するN/Pchip個のスピンを更新します。この際、すべての計算チップは同期して動作する必要がありますが、自律的同期機構を特徴とするマルチチップ計算機アーキテクチャを今回新たに開発することで、同期のための通信時間オーバーヘッドを全体性能に影響を与えない程度にまで最小化することに成功しました。
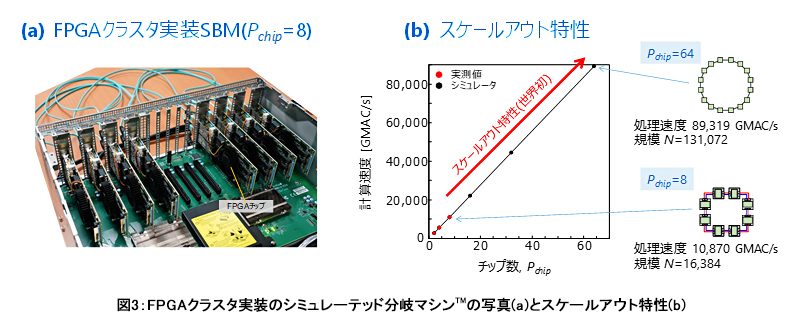
当社は、今回開発したマルチチップ計算機アーキテクチャのシミュレーテッド分岐マシン™をFPGA(Field-Programmable Gate Array、書換え可能論理回路)チップを用いて装着しました(図3)。8チップのマシンは、16,384スピンの規模(256百万結合)となり、また、1秒間あたり10,870x109回の積和演算を実行する計算処理能力 (GMAC/s)を持ちます。これは、シングルチップのマシンと比べて、スピン数で4倍の規模(結合数で16倍)、5.4倍の計算処理能力です。
また、当社は今般、マルチチップ計算機アーキテクチャの実測性能を1クロックサイクルレベルで説明できる精巧なクラスタシミュレータも開発しました。シミュレータによる64チップのマシン(131,072スピン)の処理性能は89,319 GMAC/sです。この値は、図3bに示すように、より小さな実機クラスタを用い実験的に検証された線形なスケーリング特性の延長線上に正確に乗るものです。図3bのスケールアウト特性は、複数のチップを接続することで計算速度と規模の両方を継続的に向上することが可能であることを示します(*6)。
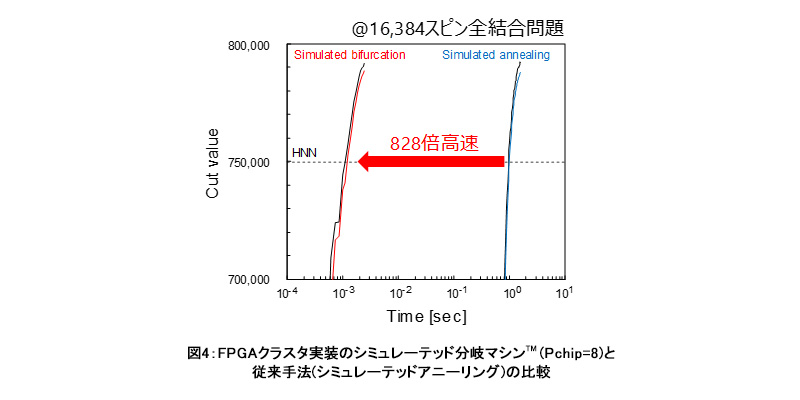
今回開発した8つのFPGAチップからなるシミュレーテッド分岐マシン™は、従来手法であるシミュレーテッドアニーリング法(SA)の高度に最適化された実装(*11)よりも828倍高速です(図4)。一方、シングルFPGAチップに実装されたシミュレーテッド分岐マシン™はSA法よりも313倍高速でした(*8)。つまり、問題規模にあわせて、チップを増設するほどシミュレーテッド分岐マシン™の速度の優位性は拡大します。これは、シミュレーテッド分岐マシン™はSA法よりも相互接続された計算チップの計算資源をより効率的に利用できるためです。
今後の展望
東芝は、今回開発したシミュレーテッド分岐マシン™のスケールアウト技術を高速・低レイテンシ性が決定的に重要となる金融取引システムや制御システムなどの様々な用途に活用することを通じて、効率的で持続可能な社会の実現に貢献していきます。
(*1)東芝プレスリリース:https://www.global.toshiba/jp/technology/corporate/rdc/rd/topics/19/1904-01.html; H. Goto et al., Science Advances 5, eaav2372 (2019).
https://advances.sciencemag.org/content/5/4/eaav2372
(*2)東芝プレスリリース:https://www.global.toshiba/jp/technology/corporate/rdc/rd/topics/21/2102-02.html; H. Goto et al., Science Advances 7, eabe7953 (2021).
https://advances.sciencemag.org/content/7/6/eabe7953
(*3)計算チップ:ここでは、微細加工技術により作成される計算処理用集積回路を指す。
(*4)全結合型組合せ最適化計算機:ここでは、イジングマシンと呼ばれる汎用性のある組合せ最適化計算機を指す。全結合型は、イジングマシンのスピン変数のすべてのペアに相互作用係数を設定可能(完全プログラム性)なもので、目的問題をイジング形式に変換する際の制約が疎結合型もしくは隣接結合型と比べて少ない。
(*5)当社調べ。
(*6)K. Tatsumura et al., Scaling-out Ising machine using a multi-chip architecture for simulated bifurcation, Nature Electronics 4, (2021).
https://doi.org/10.1038/s41928-021-00546-4
(本論文に関する解説記事BEHIND THE PAPER https://devicematerialscommunity.nature.com/posts/scaling-out-ising-machines)
(*7)東芝プレスリリース:https://www.global.toshiba/jp/technology/corporate/rdc/rd/topics/19/1910-02.html; K. Tatsumura et al., IEEE Int’l Symp. on Circuits and Systems (ISCAS), 1-5 (2020).
https://doi.org/10.1109/ISCAS45731.2020.9181114
(*8)東芝プレスリリース:https://www.global.toshiba/jp/technology/corporate/rdc/rd/topics/19/1909-03.html; K. Tatsumura et al., IEEE Int'l Conf. on Field-Programmable Logic and Applications (FPL), 59-66 (2019).
https://doi.org/10.1109/FPL.2019.00019
(*9)計算機の性能向上手法には大きく、スケールアウトとスケールアップがある。スケールアウト手法は相互接続された計算チップの数を増やすのに対して、スケールアップ手法は1つの計算チップのサイズを大きくする。スケールアウトによって、計算規模が拡大するのは自明であるが、チップ間通信のオーバーヘッドが問題になるために計算速度の向上は自明ではない。計算速度のスケールアウトを実現するためには、アルゴリズムおよび計算機アーキテクチャにおける新規の技術開発が必要。
(*10)R. Hamerly et al., Science Advances 5, eaau0823 (2019).
(*11)最適化SA法[Comput. Phys. Commun. 192, 265 (2017)]をPCクラスタに最適実装したもの。