


世界中に衝撃が走った、OpenAIによるChatGPTの登場。その利用者数は、公開からわずか2日間で100万人に、2か月間で1億人に達するなど、歴史的にも類を見ないスピードで拡大を続けています。ChatGPTをはじめとする生成AI(Generative AI)が社会にもたらすインパクトの大きさを、AIの研究者や専門家だけでなく、世界中の企業や政治家、有識者たち、さらには一般の人々も含めて、驚きと関心を持って注視しています。生成AIによって、IT業界で何が起き、ビジネスや社会システムにどのような影響が出ているのか。そして、私たちの生活は生成AIによってどのように変わっていくのか。ここでは、生成AIの基盤である大規模言語モデル(LLM:Large Language Model)にフォーカスし、技術的なポイント、ビジネスへの活用、未来に向けた展望を3回にわたって解説します。
第1回では、AI技術全般から俯瞰(ふかん)した生成AIの性質と位置づけを、また第2回では、ビジネス活動に生成AIがどのように関わっていくのかという観点で、東芝デジタルソリューションズの取り組みを紹介しました。連載最終回となる第3回では、生成AIがより身近になる未来の社会を想像します。前編として当社が実証検証を進めている「マルチモーダル応用」と「設計・開発業務効率化」へのAI適用の取り組みを、後編として当社が考えるAIのあるべき進化と人とAIの新たな関わりを解説します。
後編はこちら。
「Scaling Law」 論文が示した生成AIの2つの大きな可能性
生成AI(Generative AI)は、「人が認知可能な、新たな成果物を生み出すAI」であり、画像の判定や不良品の検知などを得意とする従来の識別系AIとは動作や役割がまったく異なります。Transformer[1] と呼ばれる大規模言語モデル(LLM:Large Language Model)の実装方式の1つが、今日の生成AIの進歩に大きく寄与しました。もともとTransformerは、英語やドイツ語、フランス語の機械翻訳を行うために考案された、「言語データ」を処理するモデルです。このモデルの登場により、LLMが言語をどこまで理解して自在に操れるようになるのかという研究が深まった結果、生成AIは、言語や文書のデータ処理だけでなく、さまざまなタイプのデータを同じ枠組みで高精度に処理できることが明らかになってきました。
私たち人間は、「言語(言葉)」を用いて意思の疎通を図ります。言葉を発するとき、まず伝えたい意味を思い浮かべ、その意味を表現するために単語を組み合せて文を作り、文を連ねて言葉にします。つまり、私たちは意思を通じ合わせるために、記号としての単語を組み合わせて文を作り、さらに文章というデータセットを構成して伝達し、そこから意味を読み解く(理解する)というデータ処理を、互いの脳で行っています。この一連の処理を実現するために、ありとあらゆる単語や文、文章、意味の組み合わせを把握しています。これが、言語(言葉)を理解している状態です。
では、どのくらいの量の単語や文の組み合わせを機械(AI)に把握させれば、人間に近い「言葉による意思の疎通」ができるようになるのでしょうか。この課題に取り組んだ研究と検証結果が、「Scaling Law※」に関するOpenAIの2本の論文[2][3]で示されています。そこでは生成AIの驚くべき可能性が、2つ明らかにされました。その1つは、AIの学習演算を左右する3つの変数を拡大すればするほど、言語を理解する性能がべき乗則に従って向上し続けるという予測です。この予測を実証するため、7千万冊を超える良質な文書を入力し、1750億パラメーター、12288次元という、とてつもない空間のベクトル演算を、毎月数十億円分もの計算機資源(データセンターの電気代なども含む)を投じて実験し、研究されました(図1)。その結果として2022年にOpenAIにより公表された成果が、GPT-3モデルと、その応用であるChatGPTサービスです。それらの性能は、周知のとおりです。
※自然言語処理におけるScaling Law(スケーリング則)とは、モデルのサイズ(パラメーター数)、学習させるデータセットのサイズ、そして学習に使用される計算量という3つの変数のみで、モデルの性能が決定するという法則。
![図1. 論文[2]で示された3つの変数(計算量C、データサイズD、パラメータ数N)のべき乗則](/content/toshiba/jp/company/digitalsolution/articles/tsoul/tech/t0703-1/_jcr_content/root/contentsArea/mainarea/layoutcontainer/layoutcontainer/image_208283237_copy_550555433.coreimg.png/1710147985470/t0703-zu01.png)
生成AIが持つもう1つの可能性は、Transformerに投じるデータは言語(単語)にとどまらず、画像や音声、センサーの数値のようなさまざまな種類のデータ、いわゆるマルチモーダルデータであっても、Scaling Lawが適用されるという予測です。実験の結果、世の中のあらゆるデータセットの裏に、人にとって有意な内容が含まれていると認識できる場合には、Transformerによってデータセットが持つ構造そのものが把握され、意味を理解しうることが示されました(図2)。
![図2. 論文[3]で示されたマルチモーダルデータのべき乗則](/content/toshiba/jp/company/digitalsolution/articles/tsoul/tech/t0703-1/_jcr_content/root/contentsArea/mainarea/layoutcontainer/layoutcontainer/image_208283237_copy.coreimg.png/1710148038264/t0703-zu02.png)
例えば、画像は「光の三原色の縦横の空間配置」というデータセットで表現されます。人はそこから画像の意味(表現している内容)を理解します。同様にTransformerは、画像を構成するデータセットから画像の意味を理解し、またその逆も実現できます。OpenAIが開発した画像生成AIのDALL-E[4]は、その実証事例の1つです。
マルチモーダルデータへの生成AI活用で製造現場の課題解決をサポート
ChatGPTサービスによって、自然な文章による質問と応答の圧倒的な賢さに注目が集まり、生成AIを文書処理へ活用する動きが急速に拡大しました。一方で、論文[3]で示されたとおり、生成AIは言語(文書)だけでなく、さまざまなデータセットに応用できる可能性を秘めています。そこで東芝デジタルソリューションズでは、生成AIを、文書処理への活用に加えて、産業・製造領域における製造装置のセンサーデータや検査データ、さらには画像や映像、作業行動ログ、日次報告文書、作業員同士の連絡(会話)といった多様なマルチモーダルデータを扱わせる取り組みにも注力し、先進の技術開発を推進しています。
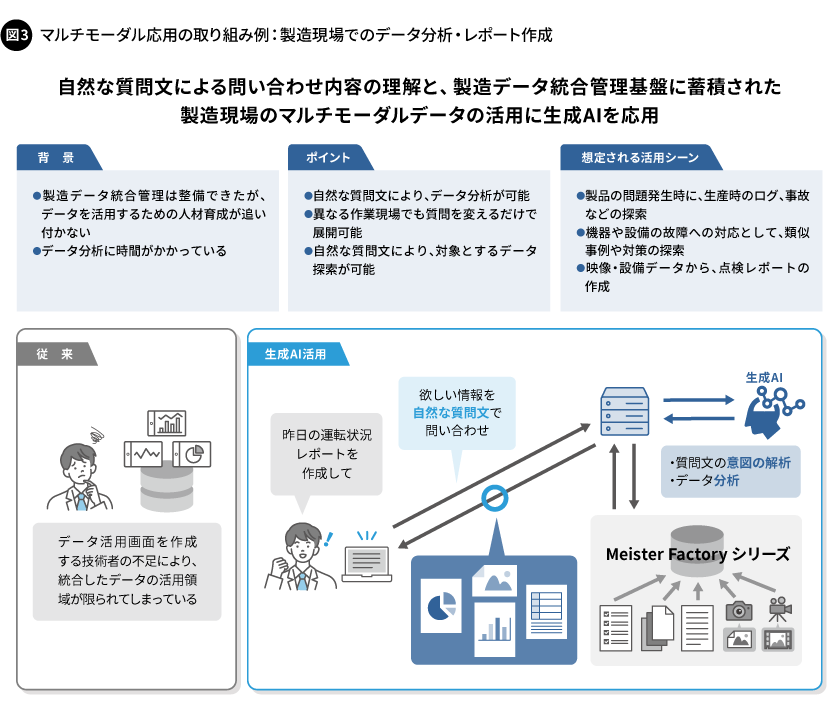
工場の製造現場では、製造した製品の品質を把握したり製造装置を管理したりするために、現場で取得した膨大なデータを蓄積し、データセットから必要な情報を抜き出して加工し、データを見比べて判断するという一連の業務を行います。これを実現するためには、どの部分のデータを取り出せばよいか、どのような分析技法を使えばよいか、さらにはどのようなデータの見せ方がよいかなどを判断するスキルに長けた人材が必要になります。また、たとえその人材をアサインできたとしても、必要なタイミングに合わせたデータの整理は容易ではありません。なぜなら、現場の状況は日々刻々と変化するため、状況に応じて柔軟かつ迅速なデータの整理が必要なこと、また状況によってはデータを整理するための時間的な余裕がないケースも少なくないからです。
一方、製造現場で注力したい業務は本来、多方面の切り口からデータを見比べ、課題解決へのアタリを付ける取り組みです。決して、データの抜き出しや加工といった作業に時間を割きたいわけではありません。課題を掘り下げて解決を目指したい現場が期待することは、必要なときに、さまざまな角度からデータを比較検討できることや、課題解決につながるディスカッション(議論)やサジェスチョン(提案)に活用できることです。
データの抜き出しや多角的な観点でのグラフ化、比較、見え方の切り替えなどは、統合管理ツールやBI(Business Intelligence)ツールといった一般的なツール群に機能として存在しており、ツールを利用すれば実現できます。しかし問題は、現場の期待に沿う形で、これらのツールを思い通りに使いこなすことが難しい点にあります。これまでは、現場の期待値をくみ取り、ツールの操作に「トランスレーション(翻訳)」する部分を、分析ツールを使いこなすスキルを持った人の読み解き力でカバーしていました。この読み解きの役割は、まさに生成AIが得意とする領域になります。
当社では、製造データの見える化や分析、レポートの作成に生成AIを活用することを目指し、製造データの統合管理基盤と現場の作業者との間に生成AIを介在させる仕組みを開発し、実証検討を進めています。具体的には、現場が求めるデータ閲覧の要件(期待値)を自然文で与えることで、生成AIが意図を解釈し、その意図に沿って、適切な範囲によるデータの抽出や、データの加工や分析、グラフや表などによる見せ方までを判断してデータ処理を行い、現場の期待値に沿った形でデータを提示する仕組みを開発しています(図3)。これにより、例えば機器や設備が故障したときに、類似の事例やその対応策、直近の運転状況などを自然な質問文で問い合わせて比較や検討がしやすい形で回答を得られるようにすることなどを考えています。
ソフトウェア設計・開発業務への生成AI活用でレガシープログラムを読み解く
生成AIを用いてプログラムコードを自動生成させるさまざまな取り組みが、世界中で試行されています[5]。Webページやユーザーインターフェース、汎用データ処理モジュールなどは、サンプルコードがインターネット上の各種サイトに広く存在することから、既存の生成AIはこれらのデータセットを教師データとして学習しています。そのため、高い精度で類似した目的のプログラムコードを生成できます。
そこで同じように、産業・商用用途のプログラムコードも生成できるのではないかと期待が高まります。しかし、既存の産業・商用用途のプログラムコードは世の中に出回ることがないため、学習に必要なサンプルコードが集まりません。特に、産業用途では、業界や業種で固有のデータ処理が必要です。これらのことから既存の生成AIは、産業・商用用途のプログラムコード、そしてその中にある固有のデータ処理を行うプログラムコードは学習できません。また、これらの領域で作成される設計書や外部仕様書、テスト仕様書などには、既存の生成AIが学習していない単語や文章の表現、表記が多く含まれています。例えば、バイオリンを知らない人にバイオリンについて説明してもらっても、その形や音色を正確に説明できないのと同様に、特定の領域でしか使われていないプログラムコードや設計書の記述用語などを学習していない生成AIに、これらを正確に生成させることはできません。
このように、従来の生成AIには、産業・商用領域でのプログラムコードの生成が難しいことがわかっていますが、一方で、生成AIは、ソフトウェア設計・開発の業務が抱える課題を解決して業務の効率化を図れる可能性を秘めていると考え、当社では実証検討を進めています。
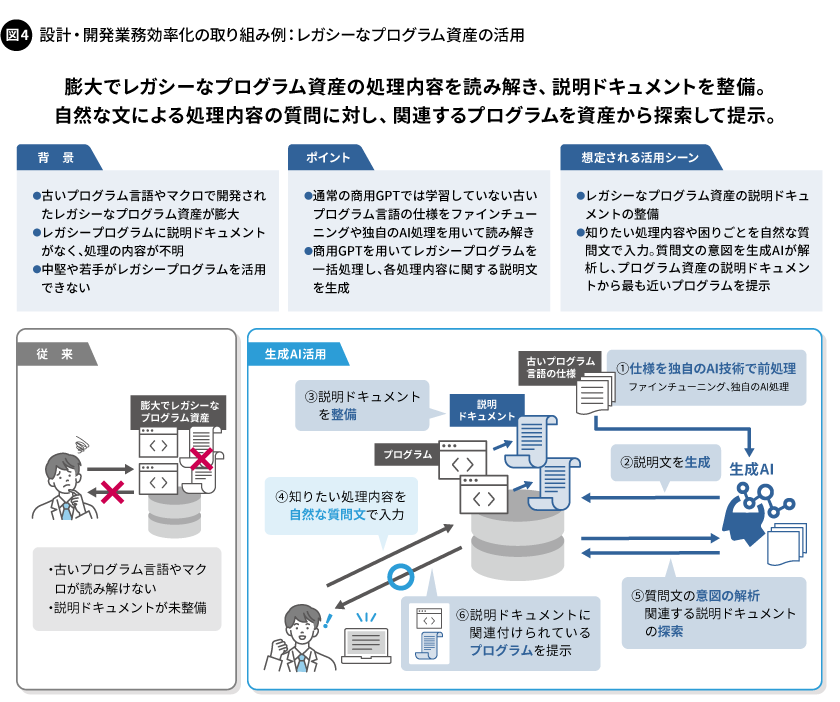
産業・商用領域のソフトウェア設計・開発には、3つの大きな課題があります。1つ目は、古いプログラム言語で制作されたプログラムコード(レガシープログラム)で開発されたシステムが、今でも稼働し続けていることです。古いプログラム言語を理解できる人材が極端に少なくなり、レガシープログラムのメンテナンスが進まなくなりました。また、マイグレーションという、古いシステムのレガシープログラムを新しいプログラム言語で大幅に置き換えることも、それによって正常に動作し続けているシステムにトラブルなどが発生するリスクが高まることから、なかなか進みません。このまま古いシステムが稼働し続ける課題は、社会問題化しつつあります。
2つ目は、産業用途では一般的なプログラムの記述力に加えて、対象の業界や業種で固有な設計技法や仕様書の作成技法、プログラムの開発技法を必要とされるため、若手や中堅の技術者にこれらを習得する時間が必要となる課題です。労働力人口の減少によりあらゆる業界の人材が不足している点、さらには技術の継承や人材の育成へ割ける時間的な余裕が少なくなっている点も、大きな社会問題となりつつあります。
3つ目は、開発したプログラムコードの品質を保証するにあたっては、抜け漏れのないテスト仕様の作成と膨大なテストを実行するための工数が必要な上、これらを行うには熟練した技術者のノウハウが欠かせないことから、属人化しているという課題です。その裏側には、業界や業種、あるいは企業で固有の知識やノウハウとして存在する「暗黙知」が起因していることも多く、また暗黙知は多くのケースで個人に蓄積され、継承されにくいのが実情です。品質保証を担う業務においては、ほかの技術者が記述した設計書やプログラムコードの「行間」から意図を読み解き、テストに落とし込む作業が多く発生しています。これらが、属人化の解消や、品質や生産性の向上を妨げる根本的な原因になっているのです。
生成AIには、膨大なデータセットの組み合わせから、データセットとその裏に結びついている意味を、学習モデルの内部で把握できる可能性があります。この仕組みを業界や業種で固有の設計や開発に応用することで、生成AIは、固有に作成され続けている設計書やテスト仕様書の特性を把握し、これまで暗黙知として伝えきれていなかった部分をも理解した上で、新たなプログラムコードや設計書を生成できる可能性があります。
産業・商用領域では、レガシープログラムで開発された安定して動作し続けている古いシステムが膨大に存在するケースが少なくありません。一方でレガシープログラムは、今はほとんど使われることがないCOBOLのような古いプログラム言語が使われていたり、設計書の記述内容や整備が疎かになっていたり、設計の意図が不明確になっていたりするケースなどがあります。
そこで当社では、生成AIを活用して古いプログラム言語で記述されたプログラムコードを読み解き、動作内容を説明する文書(説明ドキュメント)を生成することで、プログラムコードを直接読み解けない技術者が、対象のレガシープログラムを理解しやすくなる仕組みを実証検討しています。「ファインチューニング」と呼ばれる生成AIの技法を用いることで、暗黙知として継承されにくい設計の意図やテスト仕様での留意点を生成AIに語らせ、これら設計文書の読み解きを補助させるといった使い方も、将来的には可能だと考えています(図4)。
この後は、当社が考えるAIのあるべき進化と人とAIの新たな関わりを説明した後編に続きます。
参考文献
[1] "Attention Is All You Need" Ashish Vaswani, Noam Shazeer et al., 12 Jun 2017
[2] "Scaling Laws for Neural Language Models" Jared Kaplan, Sam McCandlish et al., 23 Jan 2020
[3] "Scaling Laws for Autoregressive Generative Modeling" Tom Henighan, Jared Kaplan, Mor Katz et al., 28 Oct 2020
[4] DALL-E による 「画像の自動生成」 "an armchair in the shape of an avocado" https://openai.com/blog/dall-e/
[5] 例えば GitHub Copilot, https://github.com/features/copilot/

小山 徳章 (KOYAMA Noriaki)
東芝デジタルソリューションズ株式会社
ICTソリューション事業部
技監
東芝の研究開発センターにてSW最適化設計、リアルタイム分散処理の研究に従事。iバリュー クリエーション社にてクラウドサービス、ナレッジAI、ネット家電サービスの新規事業開発を推進。東芝デジタルソリューションズにて、コミュニケーションAI・RECAIUSの事業・技術・商品開発を牽引し、現在は、生成AIの活用推進、プロダクト・マネージメント、クラウドデリバリー基盤に関する各プロジェクトを統轄している。
- この記事に掲載の、社名、部署名、役職名などは、2024年3月現在のものです。
- この記事に記載されている社名および商品名、機能などの名称は、それぞれ各社が商標または登録商標として使用している場合があります。



