


世界中に衝撃が走った、OpenAIによるChatGPTの登場。その利用者数は、公開からわずか2日間で100万人に、2か月間で1億人に達するなど、歴史的にも類を見ないスピードで拡大を続けています。ChatGPTをはじめとする生成AI(Generative AI)が社会にもたらすインパクトの大きさを、AIの研究者や専門家だけでなく、世界中の企業や政治家、有識者たち、さらには一般の人々も含めて、驚きと関心を持って注視しています。生成AIによって、IT業界で何が起き、ビジネスや社会システムにどのような影響が出ているのか。そして、私たちの生活は生成AIによってどのように変わっていくのか。ここでは、生成AIの基盤である大規模言語モデル(LLM:Large Language Model)にフォーカスし、技術的なポイント、ビジネスへの活用、未来に向けた展望を3回にわたって解説します。
第1回では、AI技術全般から俯瞰(ふかん)した生成AIの性質と位置づけ、技術実装について説明します。
第3次AIブームで進化が加速したAI技術
インターネットやAIなどは、エクスポネンシャルテクノロジーと呼ばれる、指数関数的に急成長している技術の一つです。初めてAI(人工知能)という言葉が使われたのは、1956年に米国で開催されたダートマス会議という学術会議だといわれています。当時のAIは、学習などの人間の知的活動を機械が実行できるようにすることを目的としており、それは基本的に現在も変わっていません。
AIの技術的な進化とその実社会での利活用は、2010年代の初頭から急激に立ち上がり、2030年に向けて爆発的な発展を続けています(図1)。この急成長するAI技術を、企業は乗り遅れることなく、ビジネスに取り入れていくことが不可欠です。
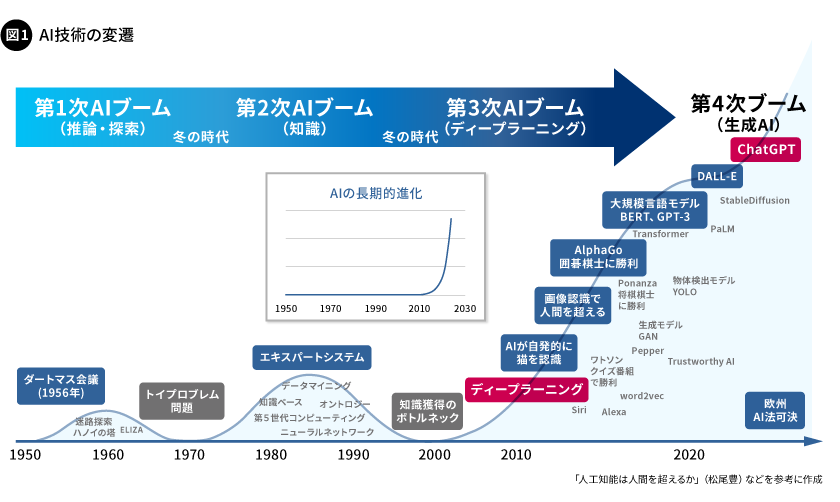
AI技術には、これまでに1960年代の第1次ブーム、1980年代の第2次ブーム、そして2010年代初頭からの第3次ブームという3度の盛り上がりがあります。第1次と第2次のブームでは、技術の未成熟さや計算能力の不足などからブームが下火になり、いわゆる「冬の時代」を迎えました。しかしその後の第3次ブームでは、ディープラーニング技術の登場とGPU(Graphics Processing Unit)による計算能力の飛躍的な向上により、大量のデータによる大規模なAIモデルの学習が可能となりました。これにより、人間の能力をはるかに超える推論(分類や回帰)能力を獲得したAIは、驚異的な性能の向上を遂げ、実用化へ向けた動きが加速しています。
ディープラーニングによる画像データや時系列データなどを対象としたAIの技術進化が落ち着きを見せ始めた2010年代の後半に、言語モデルの技術が急成長します。この成長の中で飛躍的に進歩したのが、2022年に登場したChatGPTで一躍に話題となった大規模言語モデル(LLM:Large Language Model)技術です。LLMには、「スケーリング則」と呼ばれる経験則があり、計算量とAIモデルのパラメーター数、学習データの量という3つの要素のべき乗で、予測精度が支配されるといわれています。これは、計算速度やメモリ量、データ数を増やせば増やすほど、性能が高まることを意味します。生成AI(Generative AI)の登場により、第4次AIブームに入ったともいわれ始めています。
このように、AI技術は、長期的に見ると指数関数的な成長を続けているのです。
拡散モデルによる画像生成とLLMによる文章・プログラム生成の原理
従来のAIが持つ主な機能は、「分類」と「回帰」の2つに大別されます。分類とは、入力された画像を、犬や猫、良品や不良品といったカテゴリーに分けたりするものです。また回帰は、過去のデータを基に未来を予測するもので、株価の予測や故障の予兆検知などに活用されています。第3次AIブーム以降、これらの機能は、ニューラルネットワークを多層に接続し、その接続の重みを学習して求めることで作成された、特定の目的に特化したAIモデルの活用によって実現されるようになりました。
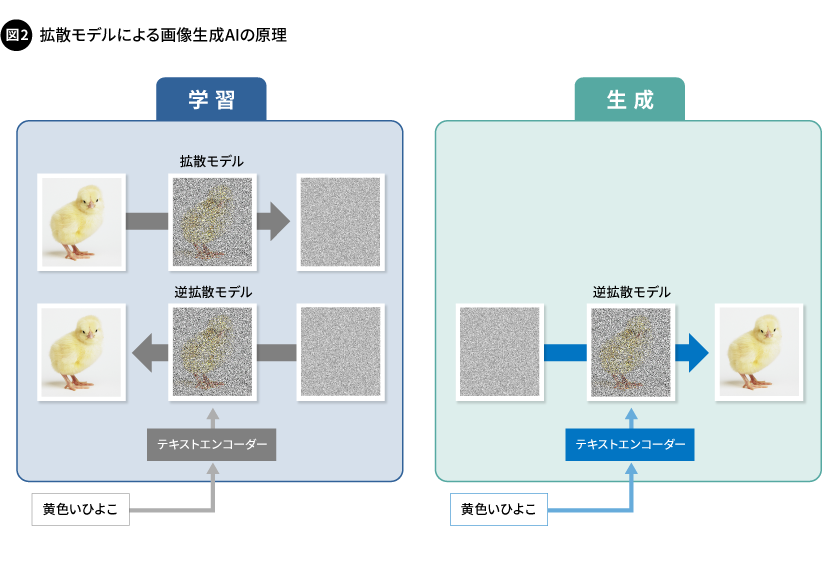
一方のChatGPTなどで用いられている生成AIは、画像や文章、プログラムなどのさまざまな情報を「生成」あるいは「分析」することができるもので、多岐にわたる用途に活用できます。このような多様な機能を実現するAIは、基盤モデル(Foundation model)とも呼ばれます。また、画像生成AIでは、拡散モデル(Diffusion Model)という手法が主流で、これはテキストによる指示に従い画像を自動生成するものです。学習時は、まず拡散モデルを用いて入力画像をノイズに変換し、次に、変換したノイズからテキストの指示に応じて元の画像を再構成していきます。この一連の流れを通じて作成した学習済みのモデル(逆拡散モデル)を用いることで、テキストに沿った画像をノイズから生成できるようになります(図2)。このモデルにより生成される画像の品質は、既に写真と区別がつかないレベルにまで向上しています。
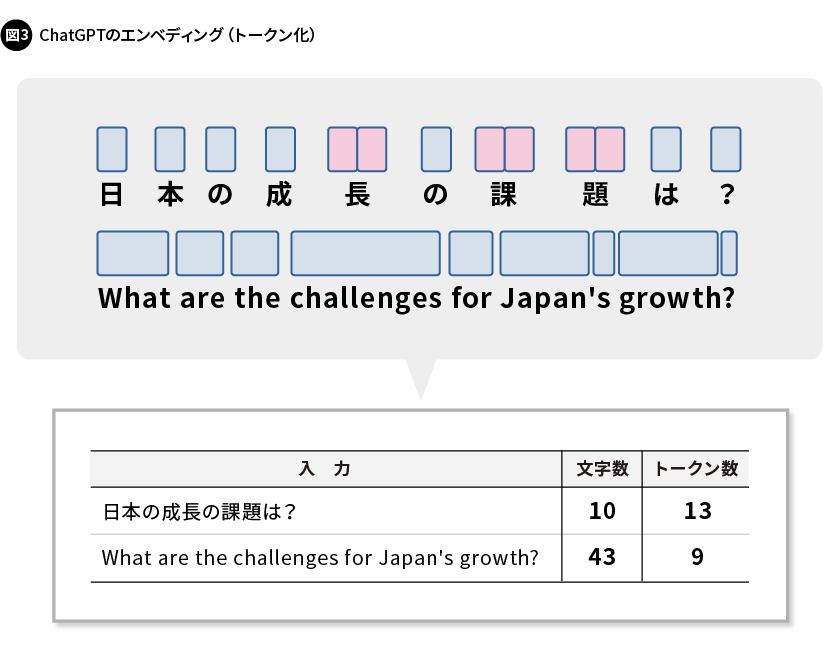
また、文章やプログラムの生成に用いられるLLMでは、2017年にGoogleとトロント大学により開発された「Transformer」という技術が用いられています。Transformerは、大量の学習データから次に出現する単語を予測したり、穴埋め問題を解いたりすることで、言語や知識を習得します。利用時には、入力された文字列に対し、回答として最も確率が高い文字列を自動生成します。LLMでは、入力された文字列を意味のある最小の単位に自動変換し、それをAIに入力します。この単位は「トークン」と呼ばれ、トークンに分割された入力文字列は、数値情報(ベクトル)に変換されます。これらの処理は「エンベディング」といいます。
ChatGPTにおける日本語と英語のエンベディングについて、例を使って説明します。英語では、単語の単位でトークン化され、入力された文字数より少ないトークンが生成されます。一方、日本語では、1文字が1つのトークンまたは複数のトークンで構成され、入力された文字数より多いトークンが生成されます(図3)。ChatGPTは、インターネット上のデータで学習しているため、学習データの量は英語によるものが圧倒的に多いといわれています。ChatGPTは、英語と日本語のどちらでのやりとりが得意なのかという議論もありますが、ケースバイケースのため結論は出ていないようです。なお、入力したテキストが、ChatGPTでどのようなトークンに変換されたのかは、OpenAIが提供するTokenizer[1]で確認することができます。
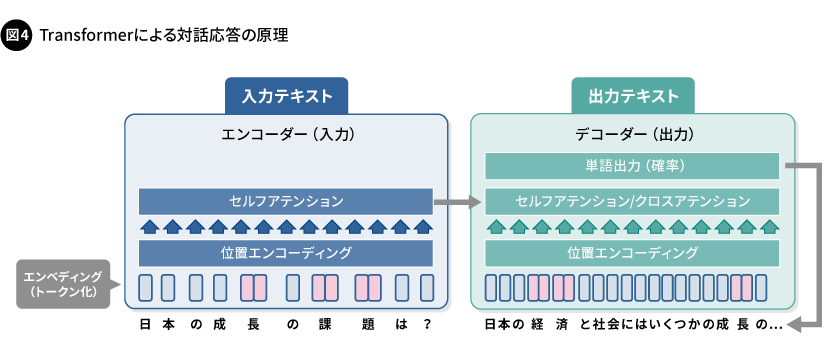
ChatGPTなどで、Transformerを用いて行われる対話応答の原理を説明します。エンコーダー(入力)部では、入力されたテキスト(文章)のトークン化と、位置エンコーディングと呼ばれる各トークンへの語彙の順序情報の付加、そしてトークン間における相関の強さの分析が行われます。トークン間の分析では「セルフアテンション」と呼ばれる手法が用いられ、入力された文章の文脈が分析されます。セルフアテンションには、入力された文章を逐次的ではなく全体をまとめて分析するという、従来の言語処理AIには見られないTransformerならではの特徴的な機能があります。
エンコーダー部で分析された入力文章の情報は、デコーダー部に送られます。そこでは回答を生成するための計算が行われ、回答として確率が最も高い単語が出力されます。出力された単語は回答文としてデコーダーに再入力され、デコーダーのセルフアテンションではそれまでに生成した回答文の文脈が分析され、またクロスアテンションでは回答文と入力文章との関係性が分析されます。これらの分析の結果、回答文の次の単語として最も確率の高い単語が出力され、この新たに出力された単語は、順次デコーダーに再入力されます。このように、回答文が逐次的に生成されていく仕組みです(図4)。
有効的・継続的な生成AIの活用に欠かせない周辺技術
生成AIを効果的に活用するためには、さまざまな周辺技術によってLLMの欠点を補うことが重要です(図5)。
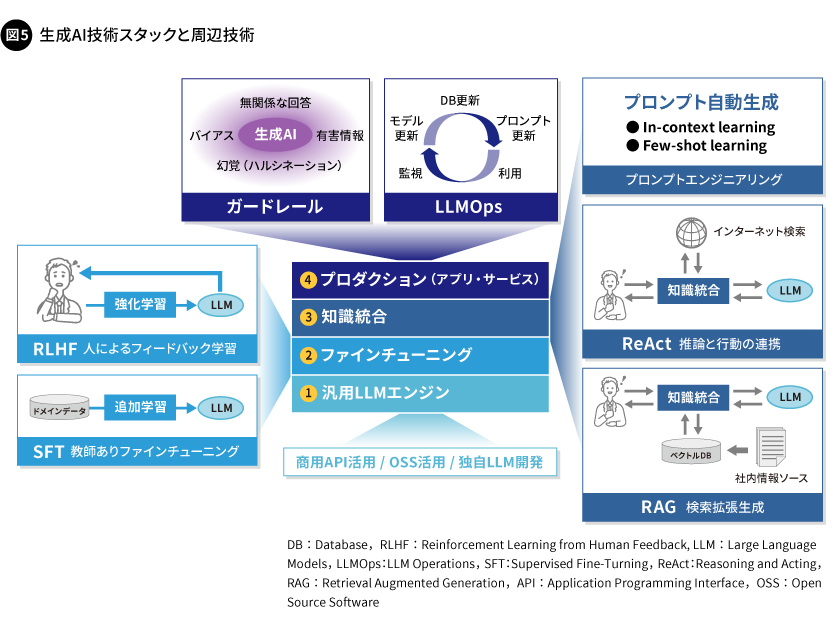
LLMは、学習時に使用したデータに含まれている知識しか持っていないため、学習したデータに含まれていない内容については回答できません。知識を拡張する方法の一つに、新しいデータを追加で学習する手法(ファインチューニング)がありますが、LLMのAIモデルは巨大なため、これを行うには膨大な計算パワーを必要とします。そこで現在は、データベースの検索と組み合わせた「検索拡張生成(RAG:Retrieval Augmented Generation)」という手法による回答の生成が主流です。また、LLMによる推論と、自動化したインターネット検索などのアクションで得た最新の情報から回答を生成する「ReAct(Reasoning and Acting)」という手法も、大変有効です。これらの技術により、追加学習をしなくても、学習していない内容に対して適切な回答ができるようになります。
LLMは、入力された文字列に対して確率的に回答を生成するため、回答が必ずしも正しいとは限りません。誤った内容をあたかも正しそうに回答し、ハルシネーション(幻覚)を起こしたといわれることがあります。またLLMは、倫理的に不適切な、あるいは有害な回答をすることもあります。これらのことから、回答の誤りや不適切な回答を抑制することが重要です。例えば、人によるフィードバックを基に学習してモデルを修正する「RLHF(Reinforcement Learning from Human Feedback)」や、生成AIの回答を制御する「ガードレール技術」の導入により対処します。
また、生成AIは、入力するプロンプトの工夫次第で、適切な回答に素早く近づけるようになります。プロンプトを用いてLLMに一時的に学習させることを「in-context learning」といい、これにはいくつかの回答例を与える「few-shot learning」などがあります(LLM自体は更新されません)。プロンプトエンジニアリングと呼ばれるこれらの技術の習得には時間と手間がかかるため、プロンプト生成の一部をソフトウェア内部で自動化することが有効です。また、生成AIを長く使い続けるためには、最新モデルへの更新や、関連するデータベースの更新、プロンプトの自動生成の改良などが欠かせません。これらの継続的な改善には、「LLMOps(LLM Operations)」の仕組みも重要となります。
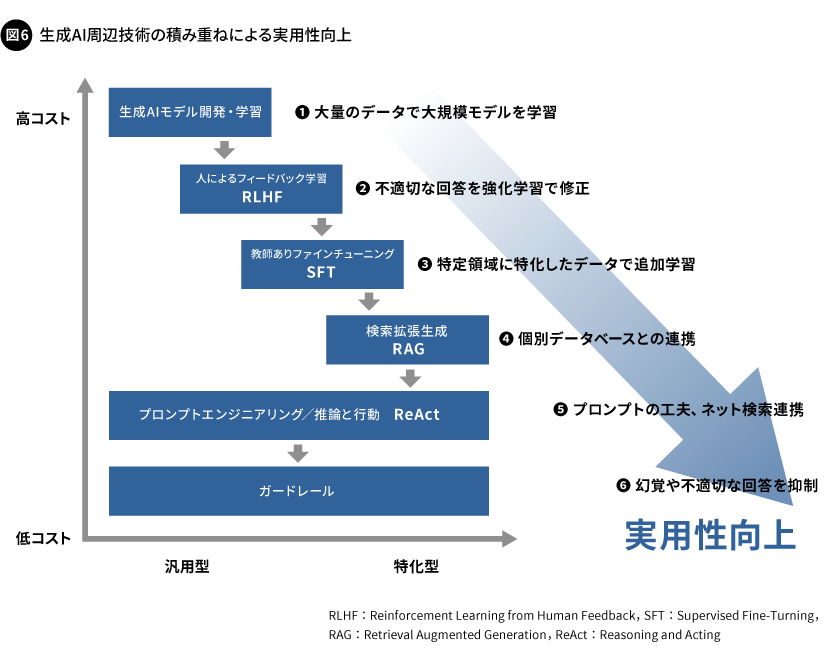
このように、生成AIの有効な活用にあたっては、LLMそのものの性能だけではなく、周辺の技術を組み合わせて実用性を高めることがポイントです(図6)。
生成AIがもたらす社会の変化~業務の効率化、品質の向上、価値創造も
第3次AIブーム以降、米国ではAIのビジネス活用が広がりをみせ、投資対効果が着実に出ているといわれています[2]。一方、日本では、これまでAIを活用したPoC(Proof of Concept)が行われてはいますが、実際の環境への適用は限定的なものが多く、普及が遅れている状況です。このような中、ChatGPTの利用者数は、トップの米国、2位のインドに続き、日本は世界の第3位につけています[3]。人口の規模を考慮すると、日本人の生成AIに対する期待の高さがうかがえます。
生成AIは、その性能の高さと回答の不確実性から「諸刃の剣」でもあることから、世界各国で規制を強化する動きが見られます。例えば、欧州ではAIを規制する法案が採択され、米国では生成AIの開発を規制する大統領令が発令されました。一方、日本は、2023年に「広島AIプロセス」[4]を提案し、国際的なルール作りを主導しています。日本が議長国としてとりまとめた、「リスクを軽減しつつ、技術の利益を最大化する」という方向性が、G7の首脳声明に盛り込まれました。AIの活用をソフトロー※で推進していく傾向のある日本は、欧米とはやや異なるスタンスです。このような背景から、日本では現在、AIの開発や活用に対する機運が高まっており、生成AIの利用に前向きな企業が半数を超えています。
※ソフトロー:法的拘束力を持たないガイドラインや自主ルールなどの社会規範
また、生成AIを活用した業務の効率化や改善にも、大きな注目が集まっています。世界の中でも特に少子高齢化が進む日本では、労働力の不足や熟練した技術の継承者不足、長時間労働といった働き方に関わる課題の解決に向けて、生成AIの活用が期待されています。OpenAIの論文[5]では、LLMを活用することで、米国国内におけるすべての業務のうち、約15%が品質を保ったまま業務時間を短縮でき、さらにLLMを用いた業務ソフトウェアによって、その効果の範囲を全体の46~56%の業務に拡大できると予測されています。また、生成AIには、業務の効率化だけでなく、品質の向上や新しい価値の創造のような付加価値を生み出すことも期待されています。今、まさに私たちは、AIをうまく使いこなして飛躍するのか、取り残されてしまうのかを問われているのです。
生成AIの出現により、2029年ごろには人間と同等以上の知能を持つ汎用人工知能(AGI:Artificial General Intelligence)の出現が、さらに2045年にはシンギュラリティー※の到来が、現実味を帯びつつあります。AI技術がさらなる進化を続けていくなかにおいて、AIに使われるのではなく、AIを使いこなすことが極めて重要です。その一方で、AIの活用拡大に伴い、電力消費量の増大が懸念されています。今後は、AIを活用する技術と、カーボンニュートラルの実現に向けた技術をさらに進化させ、両輪での対応が求められていくと考えられます。
※シンギュラリティー:AIが自律的に高度なAIを生み出し、爆発的な進化によって人類をはるかにしのぐAIが生まれる技術的特異点。
東芝グループ全体と産学官の連携で生成AIの課題解決に取り組む
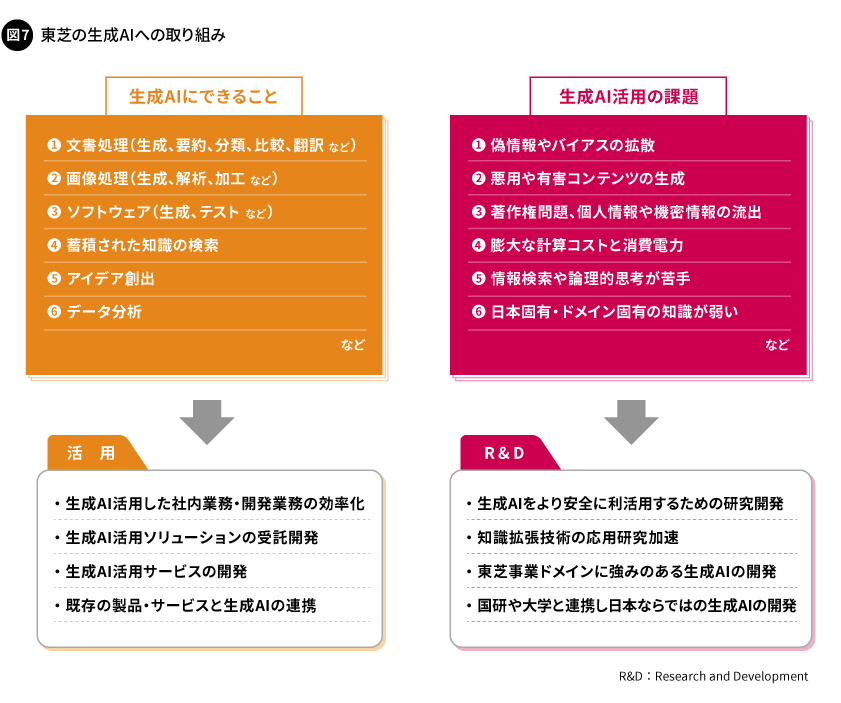
東芝では、生成AIの活用を推進するプロジェクトを立ち上げ、グループ全体における生産性の向上と新たな顧客サービスの創出を加速しています。社内に向けては各種業務や設計・開発の効率化などに活用し、エンタープライズ向けとしては既存の各種ソリューションに生成AIを適用すること、そして東芝グループが持つフィジカル領域の強みを生かせるエネルギーや社会インフラ、製造などの分野に対しても生成AIの活用を広げています。さらに、お客さまやパートナー企業、大学、国立研究開発法人との産学官連携の強化により、生成AIのビジネス活用を促進するとともに、生成AIに内在する技術的な課題の解決に向けた研究開発にも積極的に取り組んでいます(図7)。
今回は、連載の第1回として、AI技術全般から俯瞰した生成AIの性質と位置づけ、技術実装の概要を紹介しました。第2回では、実際のビジネスに生成AIがどのように関わっていくのかを、東芝の取り組みを例示しながら解説します。ご期待ください。
参考文献
[1] https://platform.openai.com/tokenizer
[2] https://www.pwc.com/jp/ja/knowledge/thoughtleadership/2023-ai-predictions.html
[3] https://www.nri.com/jp/knowledge/report/lst/2023/cc/0526_1
[4] https://www.mofa.go.jp/mofaj/ecm/ec/page5_000483.html
[5] https://browse.arxiv.org/pdf/2303.10130.pdf (PDF形式)

古藤 晋一郎 (KOTO Shinichiro)
株式会社 東芝
研究開発センター 知能化システム技術センター
ゼネラルマネジャー
入社以来、東芝の研究開発センターにて先進のデジタルメディア技術の実用化を推進。東芝デジタルソリューションズを兼務し、東芝アナリティクスAI「SATLYS」をはじめとする先進のAIを利活用する技術の開発と事業活用をリードしている。
- この記事に掲載の、社名、部署名、役職名などは、2024年1月現在のものです。
- この記事に記載されている社名および商品名、機能などの名称は、それぞれ各社が商標または登録商標として使用している場合があります。


