
Overview
Tokyo---Toshiba corporation has developed an image analysis AI that automatically generates training data from a small number of real images and can perform rapid, high-precision analysis. This AI is designed to work even with industry-specific images taken under special conditions or with special equipment, such as microscopic, infrared, and biological images (non-natural images), which often lack sufficient training data. The AI features a unique pre-training method, making it applicable to industrial fields where image analysis AI has been difficult to apply, thereby contributing to efficiency and labor reduction through automation of analysis processes.
Toshiba has confirmed the effectiveness of this AI by randomly selecting between 40 and 1,000 real images from each of five types of non-natural image datasets (*1) published online (infrared, microscopic, wafer, pathological, and fundus images). The AI was pre-trained with automatically generated tens to hundreds of times the number of original training images. It succeeded in identifying target images with higher accuracy than pre-training methods based on a commonly used large-scale natural image dataset with 1.3 million real images. Typically, high-precision image analysis requires tens of thousands of real images at least, but this AI rapidly achieves such analysis with as few as 40 real images.
Toshiba presented the details of this technology at the 17th Asian Conference on Computer Vision (ACCV2024) held in Vietnam from December 8 to 12, 2024.
Development background
With population decline in Japan leading to labor shortages and the need to increase efficiency in tasks previously performed manually, the application of image analysis AI is becoming widespread in industrial fields. For example, in quality inspections to evaluate types of defects in semiconductor products, associating defect types estimated by image analysis AI with the history of each manufacturing process can help identifying the causes of defects and enhancing productivity.
Typically, building high-accuracy image analysis AI requires training with tens of thousands of real images at least. However, in practical use, images captured under special conditions or with specialized equipment often involve significant time and cost, resulting in a smaller scale of available images. As such, it is challenging to collect a large set of image data, such as wafer images used in semiconductor development processes. The same is true for data like biological images, which cannot be used due to ethical and privacy concerns. Furthermore, there is demand to analyze small-scale image data to obtain rapid feedback to development during the launch of new inspections or temporary inspections in development processes to determine if detailed analysis is necessary.
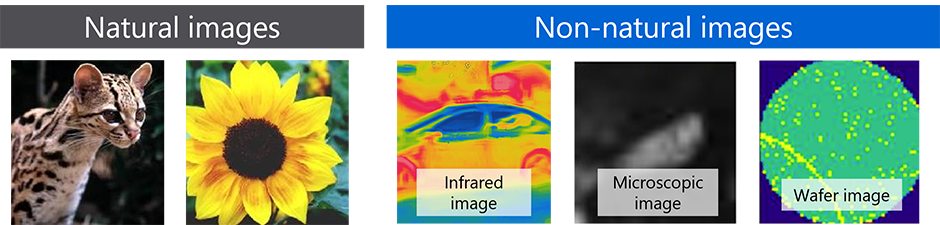
In AI development, “pre-training” using a large dataset composed of images similar in characteristics to those to be analyzed can enhance analytical accuracy when only a small amount of image data is available. Typically, pre-training involves using a large natural dataset consisting of images of animals, plants, or vehicles captured with conventional cameras (natural images). However, industrial images (non-natural images) taken with specialized equipment in manufacturing or medical fields have different features from natural images, presenting a challenge in achieving sufficient accuracy (Figure 1).
Features of the technology
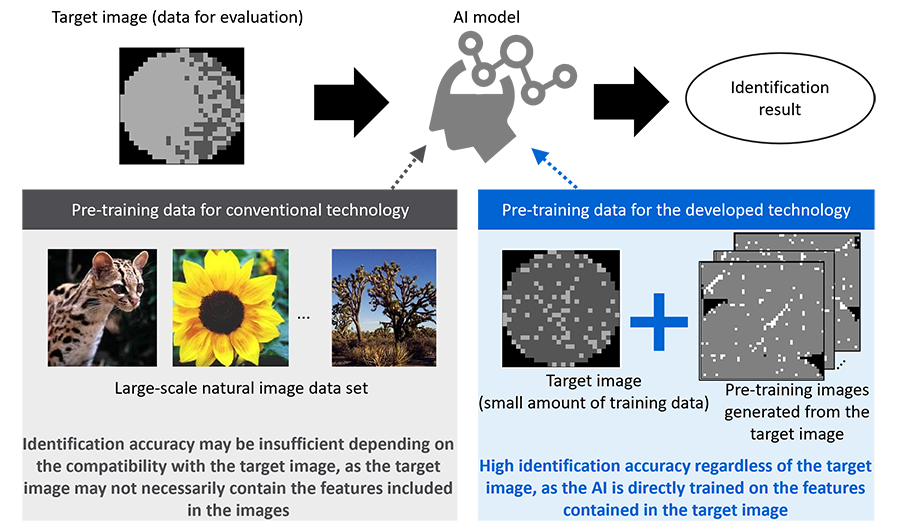
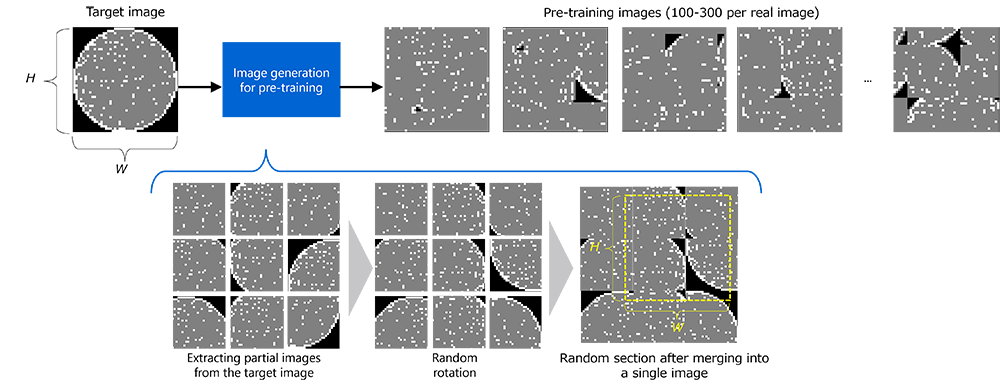
Given the situation described above, Toshiba has developed an image analysis AI that uses a unique pre-training technique to automatically generate training data from a small number of real images and analyze them quickly and accurately even for images for industrial applications, where training data for pre-training is insufficient. Rather than natural images taken with conventional cameras, the pre-training technology Toshiba devised uses non-natural images (target images), which are captured with specialized equipment for industrial purposes. This involves extracting partial images from target images, then randomly rotating and flipping them, finally concatenating those partial images into a single image (Figures 2 and 3). Unlike natural images, using these generated images for pre-training enables learning with images similar to the analysis target, thereby improving the accuracy of the image analysis AI. Typically, the preparation of training data for AI learning is time-consuming and costly, but this technology enables rapid, accurate image analysis with only a small amount of image data. The developed technology automatically generates large amounts of data for pre-training, which can be processed in just a few hours (*2). This contributes to higher efficiency and labor reductions through the automation of analysis across various industrial settings, and also meets the needs for quick decision-making on the necessity of analysis in product development and for rapid feedback to development.
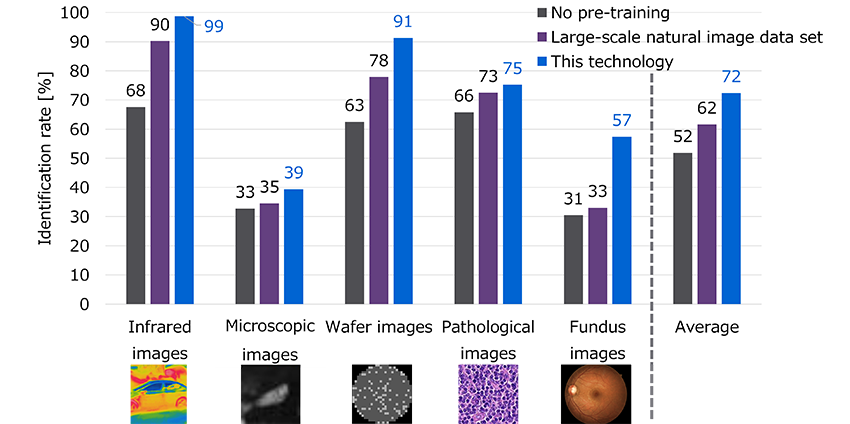
Toshiba evaluated the accuracy of this AI using five publicly available non-natural image datasets (infrared, microscopic, wafer, pathological, and fundus images). For each dataset, a small number of images, ranging from 40 to 1,000, were randomly selected to generate between 9,000 and 30,000 pre-training images for the image classification task. As a result of the evaluation, using this technology for pre-training achieved higher accuracy than pre-training using ImageNet, a typical large-scale natural image dataset that contains 1.3 million images (Figure 4).
Future developments
Using this AI enables the utilization of image analysis AI in various settings where the introduction of AI was previously abandoned due to the scarcity of target images. This technology is beneficial for factories that want to launch automatic inspection lines with a small number of images, medical professionals and medical device manufacturers who wish to diagnose diseases with a small number of biological images, and pharmaceutical and cosmetics manufacturers aiming to implement automatic identification features with a limited quantity of microscope images. Thus, this technology is expected to contribute to the development of various industrial fields.
Toshiba will continue to collaborate with Toshiba Digital Solutions Corporation to further demonstrate and enhance the accuracy of this technology, with the aim of early practical application.
- The sources of the images in this text are as follows:
Natural images: Li, F.-F., Andreeto, M., Ranzato, M., & Perona, P. Caltech 101 (1.0) [Data set]. CaltechDATA.
https://doi.org/10.22002/D1.20086 (2022)
Infrared images: Ashfaq, Q., Akram, U., Zafar, R.: Thermal image dataset for object classification.
https://data.mendeley.com/datasets/btmrycjpbj (2021)
Microscope images: Yang, J., Shi, R., Wei, D., Liu, Z., Zhao, L., Ke, B., Pfister, H., Ni, B.: Medmnist v2 - a large-scale lightweight benchmark for 2D and 3D biomedical image classification.
Scientific Data 10(1), 41 (2023)
Wafer images: Wu, M.J., Jang, J.S.R., Chen, J.L.: Wafer map failure pattern recognition and similarity ranking for large-scale data sets. IEEE Transactions on Semiconductor
Manufacturing 28(1), 1–12 (2015)
Pathological images: Veeling, B.S., Linmans, J., Winkens, J., Cohen, T., Welling, M.: Rotation equivariant CNNs for digital pathology. In: Medical Image Computing and Computer
Assisted Intervention - MICCAI 2018. pp. 210-218. Springer International Publishing
(2018)
Fundus images: Wang, Z., Yang, J.: Diabetic retinopathy detection via deep convolutional networks for discriminative localization and visual explanation. In: AAAI Workshop. pp. 514-521 (2018) - The time required for pre-training depends on the size and number of training images, as well as the specifications of the machine used for training. For example, in the case of microscope images, pre-training takes about 6 hours using a machine equipped with a high-performance GPU (NVIDIA A100 Tensor Core GPU) for 160 images of 28 × 28 pixels. Company names and product names mentioned may be trademarks or registered trademarks of their respective owners.