
Overview
Tokyo---Toshiba Corporation has developed the proprietary Hybrid Action Recognition AI, which efficiently combines human skeletal motion and a single image to recognize various human actions with high accuracy while using minimal computational resources.
As digital transformation (DX) progresses at manufacturing sites, the adoption of Action Recognition AI for analyzing work efficiency and detecting and preventing work errors is advancing. Action Recognition AI technologies can be categorized into Skeleton Recognition AI, which converts and analyzes video of people to produce skeletal information, and Video Recognition AI, which analyzes videos directly. Although Skeleton Recognition AI has been increasingly adopted due to its low computational demand, its capability to recognize types of actions is limited because it cannot distinguish the objects the person is holding. In contrast, Video Recognition AI can recognize actions as well as the objects being held but requires high computational costs and incurs high operational costs for high-performance servers.
Toshiba's newly developed "Hybrid Action Recognition AI" uses a proprietary AI algorithm to extract the optimal image from the video for action recognition while referring to the person’s skeletal motion. This AI recognizes actions involving tools with minimal computational load by efficiently combining the skeletal motion and the extracted image. Toshiba has confirmed a significant improvement in recognition accuracy from 51.6% to 89.5% in an evaluation using open datasets, particularly in scenarios where the results are affected by the objects being held. This AI is expected to contribute to DX at manufacturing sites because it can analyze work content in more detail compared with Video Recognition AI and has lower computational demand compared with Skeleton Recognition AI.
Toshiba presented the details of this AI at 2024 IEEE International Conference on Image Processing (ICIP2024), a major international conference on computer vision held from October 27 to 30, 2024.
Development background
Action Recognition AI is utilized to analyze work efficiency and to detect and prevent work errors in manufacturing settings where digitalization is advancing. For instance, it can be used to analyze and visualize the time required for each task, which can assist with identifying bottlenecks and studying improvements. Additionally, when applied to detecting work errors, the AI can prevent backtracking and improve productivity by identifying the work content, detecting any omissions, and notifying the worker in real-time.
Action Recognition AI consists of two types: Skeleton Recognition AI and Video Recognition AI. Skeleton Recognition AI converts video images into skeletal information that represents human joint coordinates, allowing it to recognize motions with minimal computational resources, which has facilitated its adoption at manufacturing sites. However, visual information other than skeletal information is lost with Skelton Recognition AI, making it unable to distinguish between similar actions involving different objects, such as applying an inspection sticker to a product held in one hand versus operating a smartphone or tablet with both hands.
Video Recognition AI analyzes video directly from the camera, using visual information to recognize actions. However, video data consist of a sequence of images over time and require extensive computational resources for processing, depending on the duration and size of the images. Therefore, high-performance servers are needed for AI processing tasks, posing challenges in balancing cost-effective operations with efforts aimed at realizing DX at manufacturing sites.
To this end, it is necessary to distinguish and analyze in detail and in real time actions that have different meanings depending on the objects involved, which requires recognition technology that can accurately identify specific worker actions with minimal computational cost.
Features of the technology
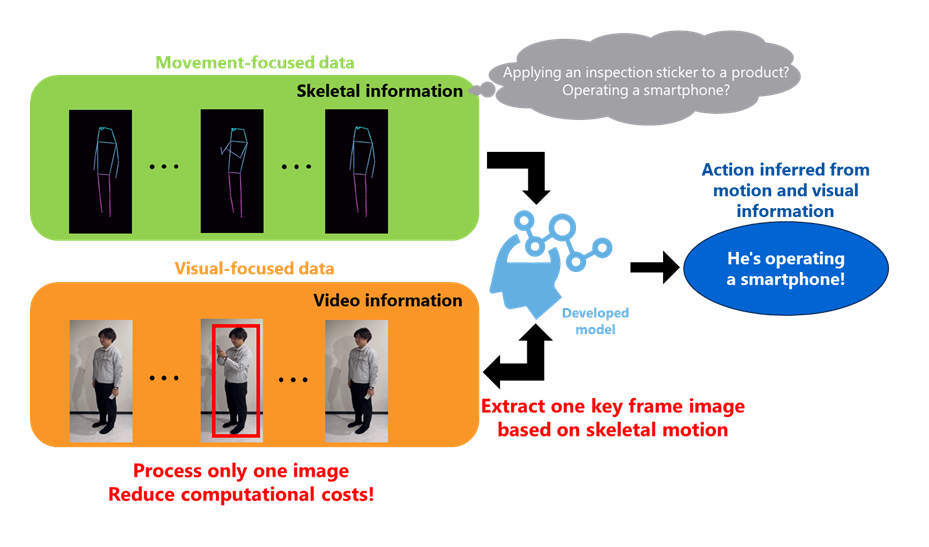
Against this background, Toshiba has developed the Hybrid Action Recognition AI, which efficiently combines human skeletal motion and a single image to recognize various human actions with minimal computational resources while also considering the object held by the person (Figure 1).
With reference to skeletal motion, this AI uses a proprietary algorithm to extract just one key frame from the video that is crucial for action recognition. Specifically, the AI quantifies the necessity for action recognition, using a metric known as "attention," and then selects the frame with the highest attention from the sequence. Using this mechanism, Hybrid Action Recognition AI overcomes the respective disadvantages of both Video Recognition AI and Skeleton Recognition AI.
By utilizing only the key frame image, this AI can process visual information, including tools and parts not included in skeletal data, with minimal computational cost. This allows for efficient computation of both skeletal and image data, enabling effective action recognition.
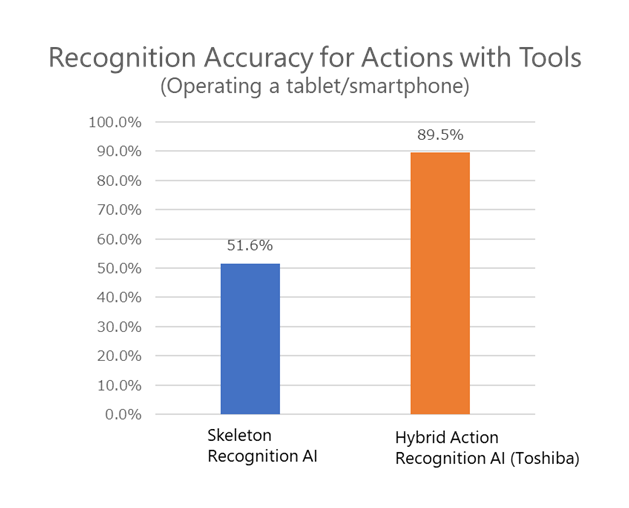
An evaluation of Toshiba's Hybrid Action Recognition AI using an open dataset showed that it significantly improves the accuracy of recognizing actions involving tools compared with methods that only use Skeleton Recognition AI. For instance, this AI improved the accuracy of recognizing the action of using a smartphone or tablet from 51.6% to 89.5% (Figure 2).
The Hybrid Action Recognition AI can distinguish actions that could not be recognized by only Skeleton Recognition AI, thereby enabling detailed analysis of work content and time requirements with practical accuracy.
Additionally, compared with Video Recognition AI, which processes all frames of a video, this AI can process data 4.6 times faster, enabling real-time processing comparable to the Skeleton Recognition AI currently being implemented at manufacturing sites*.
Future developments
Toshiba aims for early practical application, and will widely apply this AI across its group factories and toward image analysis solutions, using Toshiba Lighting & Technology Corporation’s camera-equipped LED lighting, "ViewLED."
- Estimation based on time required for action recognition when processing a video of approximately 8 s.