
Overview
TOKYO—Toshiba Corporation (TOKYO: 6502) has developed an AI that understands specialized technical documents of factories and plants in the infrastructure sector with high efficiency and accuracy: it understands accumulated sector-specialized documents (hereinafter, “specialized data”) including technical drawings, machine specifications, and inspection/incident reports, thereby enabling more effective inspection and maintenance. Whereas efficient learning of general terms from a large general-purpose language model (teacher model) is widely available, the developed AI learns sector-specific technical terms using a separate curriculum with a limited amount of specialized data. Such efficient learning of both general and technical terms enables generation of small-scale language models (student models), thereby allowing for accurate understanding of technical documents with limited computational resources.
Specialized data that accumulates experts’ experiences and knowledge were previously difficult for an AI to understand. However, specialized data can be utilized by the developed AI in actual infrastructure maintenance. It can extract phenomena in previous incidents as well as measures to solve them with high accuracy. This AI is expected to contribute to faster corrective maintenance and to the realization of condition-based maintenance.
Toshiba will present this AI at the 29th Annual Meeting of the Association for Natural Language Processing (NLP2023, Okinawa, March 13-17, 2023), which will be held in a hybrid format.
Toshiba aims to achieve “proactive maintenance” including condition based maintenance with utilization of experts’ knowledge in future.
Development background
Aging of many facilities in factories, plants, and buildings and a chronic shortage of labor for their maintenance have been problems. Thus, there is demand for services that require less labor (such as remote maintenance), with a forecast domestic market size of 2.935 trillion yen in 2025 (*1).
To maintain and inspect aging facilities at high accuracy, good knowledge of those facilities with understanding of their history of maintenance and inspection are crucial. However, a problem at present is that specialized data such as maintenance and inspection reports, in which experts’ experiences and knowledge were accumulated, are not fully organized for utilization.
Large general-purpose language models are known as a fundamental technology for understanding documents with high accuracy. Those models are trained using a vast amount of document database (*2) comprising general documents in order for them to understand the context of sentences by unsupervised learning, and they are attracting attention as a versatile technology applicable to various services, such as Q&A and machine translation. However, the computational scale of general-purpose language models is large, and ensuring adequate computational resources is difficult in actual infrastructure maintenance, creating a challenge. Also, when using general-purpose language models for specific business sectors, technical documents particular to the field need to be additionally learned. This means that large sets of sector-specific data are needed, requiring further computational resources.
If specialized data can be understood with high accuracy using limited computational resources, then it would be possible to greatly improve the efficiency of maintenance and inspection work, including automatic inspection of incomplete reports, rapid formulation of countermeasures by referring to similar past incidents, and replacement of machine components before failures occur based on the trends from failure analysis.
Features of the Technology
Considering the above, Toshiba developed a sector-specific AI that accurately understand documents using limited computational resources for learning of general terms and technical terms.
This AI generates a small, specialized language model (a student model) that learns general terms via distillation of knowledge from a teacher model (a large general-purpose language model). At the same time, it learns technical terms using a separate curriculum (Figure 1). More precisely, the same specialized data with several masked words are input into both the teacher model and the student model, and the student model is trained to output the same answers as those output by the teacher model when the masked words are general terms, and to output the same answers as the correct answers when the masked words are technical terms. In this way, the student model learns both general terms and technical terms simultaneously, enabling acquisition of technical terms without forgetting of general terms.
Toshiba evaluated the effectiveness of this AI by performing a language analysis test. Specifically, an information extraction task was performed that involved finding descriptions about incidents noted in maintenance and inspection reports from an electric power facility. The computational scale of the student model generated by this AI was half of that required for a large-scale general-purpose language model generated in the conventional way (learning from scratch), and the amount of documents used to train this AI was one-hundredth of that used to train the conventional model. Results showed that this AI successfully extracted areas where “phenomena (circumstances of machine trouble)” and “countermeasures (actions taken by maintenance workers)” were described in the documents, with a correct answer rate of 89% (Figure 2). This is very close to the standard required for actual use (90%). Further, the time required by this AI for learning was 5 hours, which was shortened by an approximately 97% compared to the conventional approach, which requires approximately one week for learning.
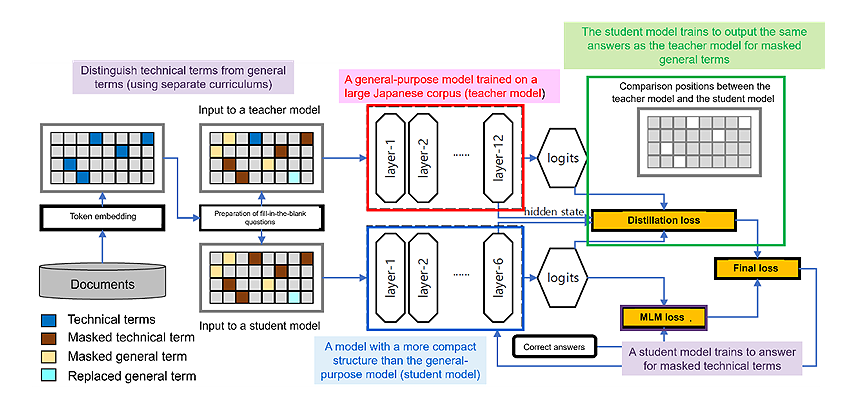
Figure 1: Summary of this technology
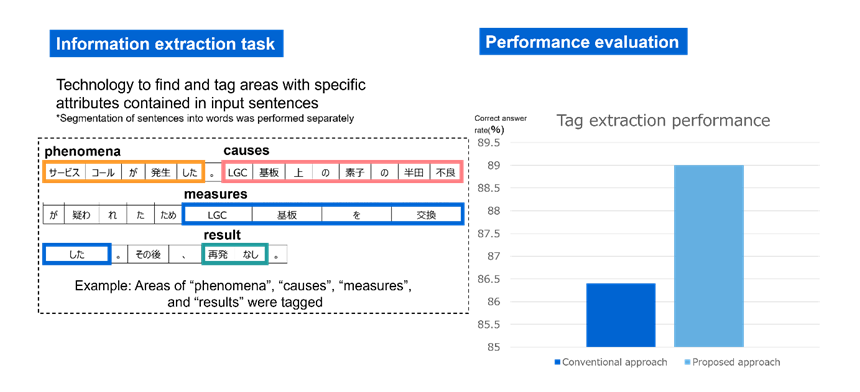
Figure 2: Performance evaluation of this technology
Future developments
Toshiba aims to start using this AI at actual business sites of Toshiba Group in 2024 in order to realize services for faster corrective maintenance by organizing and utilizing the experts’ knowledge recorded at the actual sites of maintenance and inspection. Toshiba is continuing research and development to achieve “proactive maintenance” by using this AI in condition-based maintenance of infrastructure facilities, both inside and outside the Toshiba Group (Figure 3).
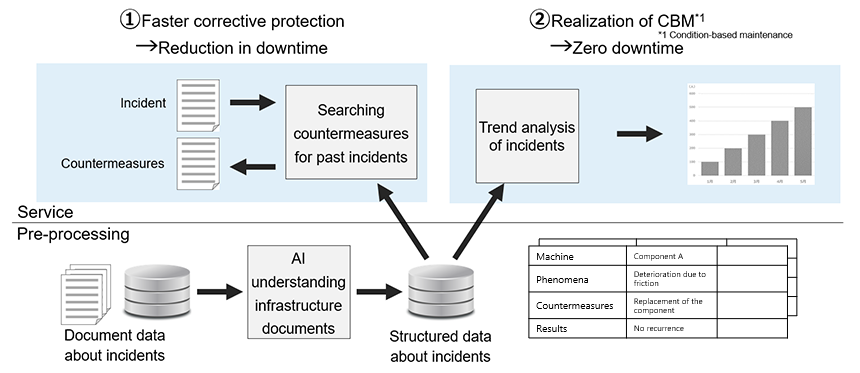
Figure 3: Future developments
*1: https://www.fuji-keizai.co.jp/report/detail.html?code=162012846 (in Japanese)
*2: Language materials in the form of a database comprising a large amount of text