
Overview
Toshiba Corporation (President and CEO: Satoshi Tsunakawa, hereinafter: Toshiba) and the Riken National Research and Development Institute (President: Hiroshi Matsumoto, hereinafter: Riken) have developed a scalable AI, namely, a learning method that allows deployment of a trained AI to various systems with varying computational requirements with as little degradation of performance as possible. When applying this technology to image classification task, even when reducing calculations to one-third the standard amount, the decrease in detection accuracy was only 2.1% (compared with 3.9% for a conventional scalable AI), thereby achieving world-class performance*1.
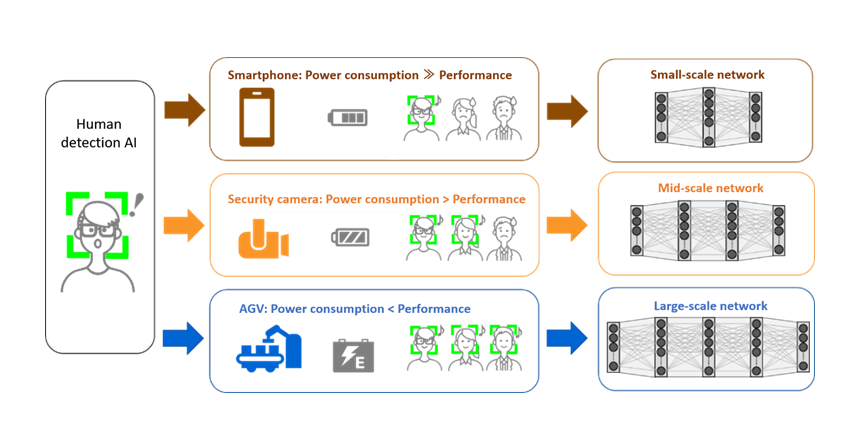
Normally, AI engines are designed and developed through trial and error while hand-tuning factors such as the AI model size, considering the computational complexity and performance requirements for each system or service to which the AI will be applied. By introducing the developed technology, once an AI is trained, for example, to perform large-scale high-performance human detection, fine-tuning through trial and error becomes unnecessary for deployment to different application environments such as smartphones, security cameras, and automatic guided vehicles (AGV). It also becomes possible to standardize the AI engine for different applications, which will reduce the lead time required for AI engine development and improve management efficiency. Furthermore, the trade-off between computational complexity and performance become clear when training large-scale AIs, facilitating the selection of which processors to use.
This technology was developed at the Riken AIP-Toshiba Collaboration Center, established in April 2017 to accelerate the practical application of results from research and development into basic technologies for innovative next-generation AI. Toshiba and Riken will present the details of this technology*2 at the 30th International Joint Conference on Artificial Intelligence (IJCAI 2021), to be held August 19–26.
Development background
AI is now being used in various applications, from voice recognition and machine translation to image recognition for autonomous driving. Even AI that has only one function can be applied to a wide variety of systems and services. For example, an AI that detects humans in camera images can be used not only in smartphones and stand-alone security cameras, but also in AGVs. Processor capabilities vary among systems, and some systems, such as those in AGVs, require highly accurate positioning to avoid collisions with nearby people. Currently, AI development and training is performed from scratch for each system while manually balancing computational complexity and accuracy requirements through trial and error. This lengthens development periods and increases costs because different AIs must be developed for each system. The added complexity also makes it difficult to realize economies of scale. Scalable AIs that can be deployed according to the computing power available in the target system have begun to be developed, but a remaining problem is that reducing the amount of computation will decrease the performance of the AI to below its original design.
Features of the technology
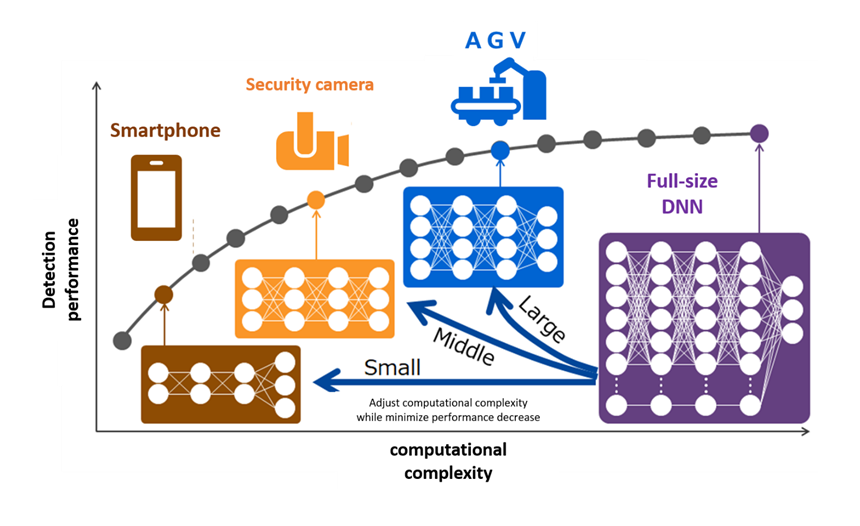
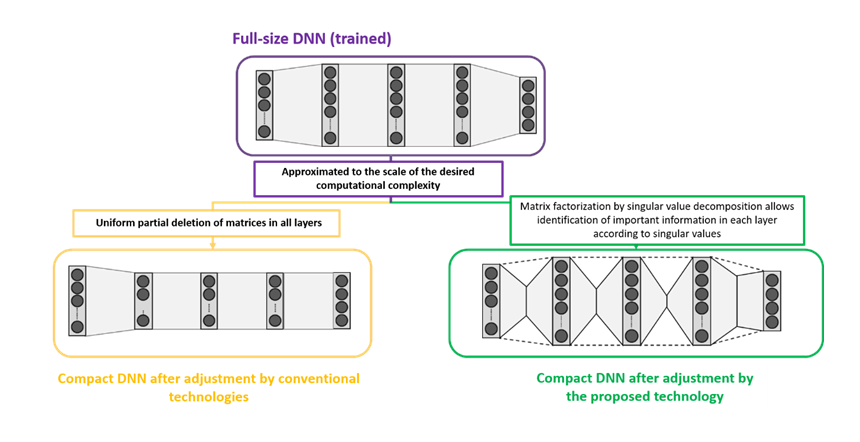
To address this problem, Toshiba and Riken have developed a scalable AI technology that can adjust computational complexity while suppressing performance degradation. With proprietary deep-learning technology, a trained AI can operate on processors with various processing capabilities while maintaining performance, and more efficient AI development can thus be expected for various systems with different uses. This technology uses a compact deep neural network (DNN)*3 that reduces calculation amounts by decomposing a matrix representing the weight of each layer into a smaller matrix that approximates the original full-size network with as little error as possible. When creating a compact DNN, conventional technologies*4 reduce computational complexity simply by uniformly deleting parts of matrices across all layers. By contrast, the new technology reduces approximation error by reducing computational complexity while retaining to the extent possible matrices for layers with a large amount of important information.
During training, weights for the full-size DNN are updated so as to minimize differences between correct answers and output values of the compact DNN and the full-size DNN at various size DNN. This is expected to result in well-balanced training for any size DNN. After training, the full-size DNN can be supplied by approximating the computational complexity required by individual applications. Furthermore, correspondences between computational complexity and performance can be visualized through training, and the computational performance required for target applications can be estimated, thus facilitating selection of system processors.
An internationally recognized public database*5 of general images was used to evaluate accuracy in the task of classifying data according to the image subject. When using the proposed technology to decrease computational complexity by one-half, one-third, and one-fourth compared with the trained full-size DNN, the detection performance was decreased by 1.1%, 2.1%, and 3.3%, respectively. The corresponding decreases in performance were 2.7%, 3.9%, and 5.0% with a conventional technology. These results show that the proposed technology achieves world-class performance compared with conventional scalable AI technologies.
Toshiba and Riken will continue optimizing this technology to hardware architectures for various application in embedded and edge devices, with the aim of practical application by 2023 following verification of effectiveness in real-world tasks.
*1: Performed using the ImageNet5 public dataset (January 2021)
*2: Atsushi Yaguchi et al. “#2263 Decomposable-Net: Scalable Low-Rank Compression for Neural Networks,” Proceedings of the 30th International Joint Conference on Artificial Intelligence (IJCAI-21). (Available online at https://doi.org/10.24963/ijcai.2021/447)
*3: A neural network is a computer-based mathematical model of the structures formed by human neurons. Those with many middle layers are called deep neural networks. This is one AI methodology.
*4: Jiahui Yu et al. “Universally Slimmable Networks and Improved Training Techniques,” Proceedings of the IEEE International Conference on Computer Vision, Vol. 1. pp. 1803–1811, 2019.
*5: Deng, Jia et al. “Imagenet: A Large-scale Hierarchical Image Database.” Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009. p. 248–255.