
- Back to the previous page
- AI Technology
Speaker Adaptation Technique for Text-to-Speech System
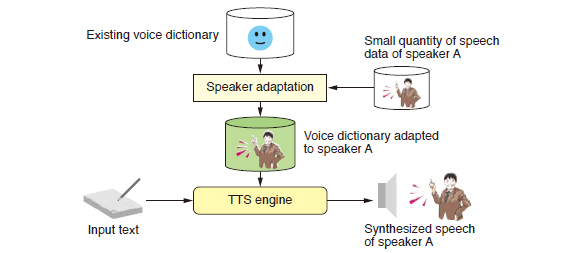
Toshiba has developed a speaker adaptation technique for text-to-speech (TTS) by which a TTS system can be customized to the voice characteristics and manner of speaking of a specific speaker in a short time and at low cost.
In conventional TTS systems, at least a few hours of speech data have been required to create a voice dictionary that represents a specific speaker’s voice characteristics, in order for the system to be able to synthesize any text. Our newly developed speaker adaptation technique converts an existing voice dictionary with sufficient phonetic/linguistic coverage into a dictionary having the voice characteristics and manner of speaking of a specific speaker, based on a small quantity of speech data of that speaker. This technique makes it possible to create a voice dictionary for a specific speaker with a practical level of voice quality from less than 10 minutes of speech data.
A method using statistical models of acoustic/prosodic feature parameters respectively representing voice characteristics and manner of speaking was newly adopted as an appropriate TTS technique for speaker adaptation. In speaker adaptation, such statistical models are converted to models for other speakers by identifying the best fit for the given small quantity of speech data.
First, the base TTS method was improved by introducing our original signal processing technologies to achieve top-level voice quality. During this work, it was found that the TTS method needs to use a specific acoustic feature parameter so as to realize high voice quality with a low computation cost for real-time processing, but that the existing speaker adaptation method was unable to handle this parameter stably. The problem was solved by introducing a stabilization process to the speaker adaptation and TTS processes, resulting in a new speaker adaptation technique that is applicable to practical TTS systems.
Speaker adaptation technique for TTS