
- Media recognition
- Media data analysis
- Speech dialogue
Speech recognition technology for domain-specific terms
We improve speech recognition performance in environments with many domain-specific terms and proper nouns, without requiring additional training.
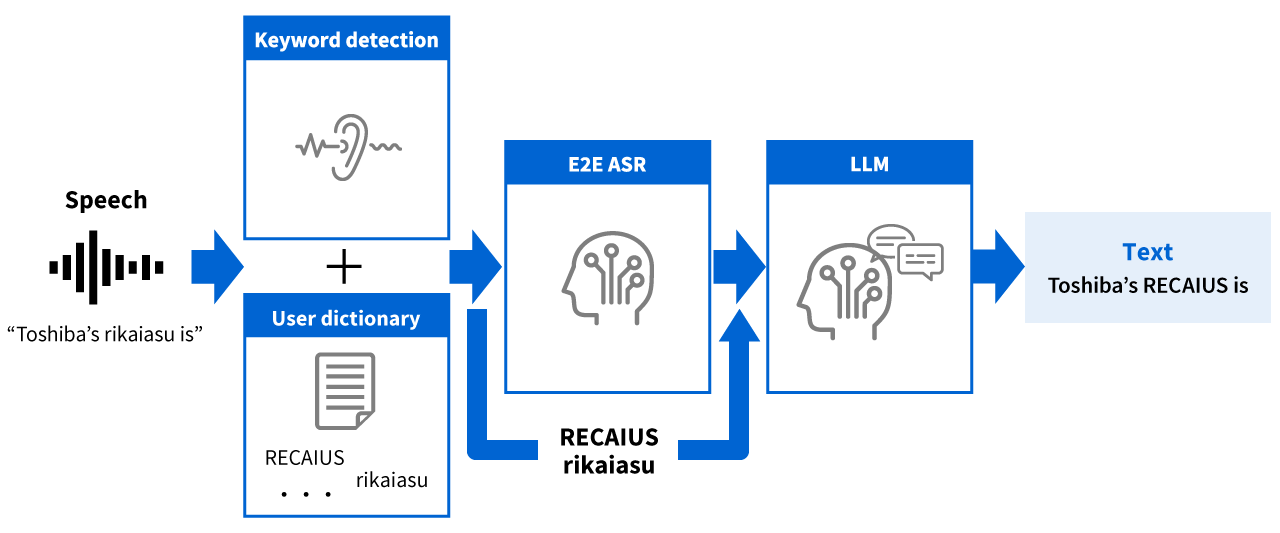
- We achieve highly accurate speech recognition using end-to-end speech recognition technology based on deep learning.
- By simply preparing a user dictionary containing the spelling and pronunciation of technical terms and proper nouns, our system can handle domain-specific vocabulary without time-consuming additional training.
- We improve speech recognition accuracy by detecting keywords such as technical terms and proper nouns, and applying post-processing correction using large language models (LLM).
Applications
- Speech Dialogue System
- Speech-to-Text Captioning System
- Broadcasting System
Benchmarks, strengths, and track record
- We evaluated our system using speech data from eight internal seminars containing many technical terms. Compared to conventional methods, our approach maintained the character error rate while improving the F-score for user-defined terms by an average of 3.05 points, with a maximum gain of 8.08 points.
Inquiries
Inquiries to Toshiba Corporate Laboratory (Komukai region)
Please include the title “Toshiba AI Technology Catalog: Speech recognition technology for domain-specific terms” or the URL in the inquiry text.
Please note that because this technology is currently the subject of R&D activities, immediate responses to inquiries may not be possible.
