


A diverse range of consumer-oriented devices, such as appliances and car navigation systems, use speech to relay information to users. They are used to make announcements on trains and buses, and also for the lines spoken by characters in smartphone apps and video games. Until now, speakers have been recorded and their voices have been played back as audio on devices, but thanks to recent evolutions in speech synthesis technology, artificially created synthesized voices are increasingly being used. Toshiba has many years of experience with speech synthesis technologies. We have developed numerous fundamental technologies that create more natural, higher quality speech. In this three-part special feature, we will discuss societal trends related to speech synthesis, the features of Toshiba's technologies, the frontlines of product development, and the future outlook for the use of these technologies throughout the world.
In Part 1, we explored various use cases for speech synthesis, introduced its fundamental technologies, and highlighted Toshiba’s proprietary innovations and their distinctive features. This second article introduces Toshiba’s speech synthesis SDKs, including the ToSpeak middleware, which enables voice interaction across various devices and services.
What are speech synthesis SDKs? — Their architecture and applications
As introduced in Part 1, Toshiba’s speech synthesis technology generates smooth, natural, human-like speech from user-defined text, while requiring minimal memory and computational resources. We offer our proprietary speech synthesis technology as software development kits (SDKs), making it easy to integrate voice capabilities into a wide variety of devices and services.
Users can access speech synthesis functions—such as generating speech from input plain text or converting input plain text into phonetic text—via an application programming interface (API) integrated into their own products or services. In this way, Toshiba’s speech synthesis technology can be used as middleware within application programs—in other words, as software components embedded in customers’ products and services (Fig. 1).
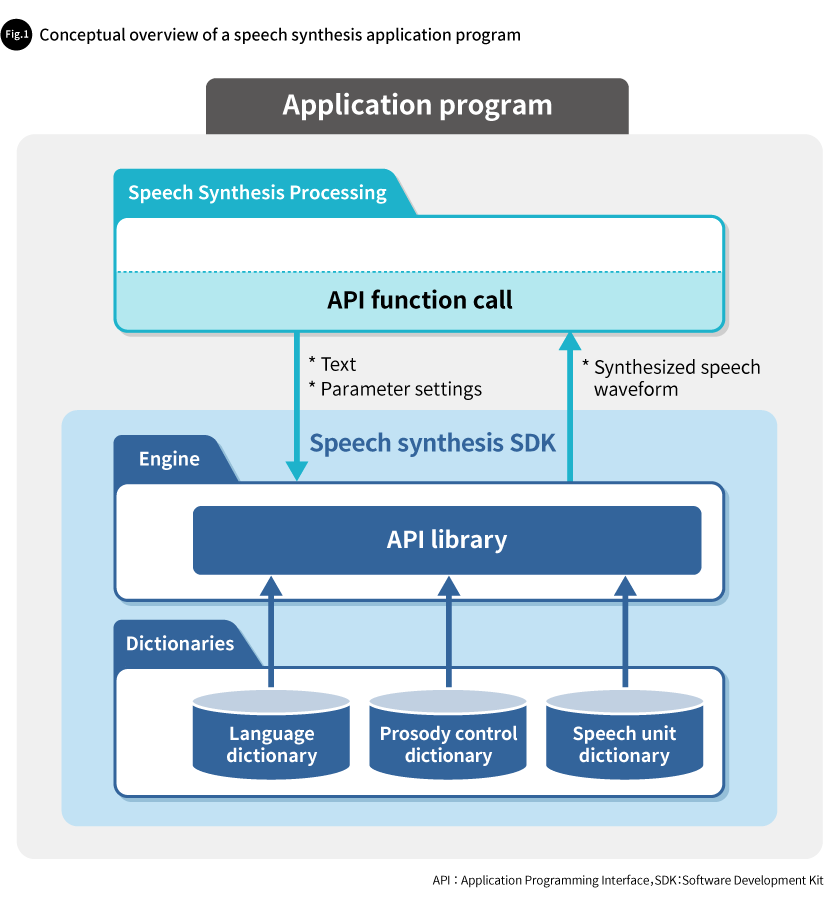
Each SDK product consists of a speech synthesis engine and a set of dictionaries. The engine is an API library that offers a range of functions for speech synthesis. The dictionaries include a language dictionary, which defines word pronunciations and phonological rules for each language. The set also includes a prosody control dictionary and a speech unit dictionary, which capture speaker-specific characteristics such as voice timbre, voice tone and speaking style.
Speech synthesis functions are accessed by invoking the appropriate methods from the API library. The SDK provides a variety of functions. Basic functions include generating speech data or phonetic text from user-defined text, and adjusting the speed or pitch of the synthesized speech. In addition, secondary extended functions allow for fine control over speech output—for example, determining whether to read individual symbols, or whether to interpret a string of numerals as a single number or as separate digits. Advanced extended functions include generating a voice that blends characteristics of two voices, and gradually transitioning from one voice to another (The specific functions available may vary depending on the SDK product).
The SDK allows users to specify the language of the input text by switching language dictionaries. It also supports customization of the synthesized speech—such as speaker, tone and speaking style—by selecting appropriate prosody control and speech unit dictionaries. By switching dictionaries, products and services with speech synthesis capabilities can provide voice responses with quality, tone, and speaking style suited to their specific applications.
Historical overview of Toshiba’s speech synthesis SDKs
Toshiba offers a range of SDK products that support different speech synthesis methods. Differences in synthesis methods result in varying resource requirements and target platforms for each SDK product. Each SDK product offers superior naturalness and clarity in synthesized speech, while maintaining lower resource requirements than typical solutions available at the time of release.
Speech synthesis is often integrated into consumer-facing products and services with voice interaction features. To ensure a responsive experience, it is important that speech begins with minimal delay. To achieve this, our system generates synthesized speech waveforms corresponding to the input text in sequential segments of a specified size. It begins with the speech data for the initial portion of the text, then continues generating data for the subsequent parts. Each segment is passed to the application program as soon as it is produced, enabling smooth and timely audio playback. This enables the application to start playback of synthesized speech without waiting for the entire input text to be processed.
The following section provides an overview of the SDK products that Toshiba has developed and released over the years (Fig. 2).
The speech synthesis methods discussed in this article were previously introduced in Part 1.

• Speech synthesis middleware using closed loop training (CLT)
This middleware uses Closed Loop Training (CLT) to model both prosody and speech units. By automating what was previously a manual tuning process, it eliminates the need for engineers to adjust unnatural prosody or unit selections. As a result, it delivers high-quality synthesized speech with minimal defects. The system operated efficiently even on resource-constrained devices of the late 1990s, significantly contributing to the practical adoption of speech synthesis technology. This product was primarily adopted in embedded systems, particularly in automotive applications.
• ToSpeakG1, ToSpeakG2
This product employs a unit selection and fusion method in its speech waveform generation module. It features clear synthesized speech and accurately reproduces the vocal characteristics of the target speaker. This method synthesizes speech by selecting units whose linguistic context closely matches the input text, from a preconstructed set of versatile speech segments created by fusing multiple base units. By reducing the number of speech units required for synthesis, the technology was successfully applied to a wide range of embedded devices. By achieving highly reproducible vocal quality, this product also played a key role in the early adoption of “sound-alike” voices modeled after well-known individuals with distinctive vocal characteristics.
• ToSpeakG3
This product employs a speech synthesis technique that utilizes a statistical framework called the Hidden Markov Model (HMM). It allows for flexible adjustment of prosody and voice quality through parameter tuning. This advancement enabled the generation of intermediate voices—those that blend vocal characteristics and speaking styles from multiple sources. It also facilitated stable and cost-effective adaptation to reference speakers, thereby enhancing the diversity of synthesized speech. Despite its low resource requirements, the product delivers stable voice quality and has been extended to support multiple languages. ToSpeakG3 is currently deployed across a wide range of embedded devices.
• ToSpeakGx Neo
This product employs a parameter selection approach based on acoustic models developed through statistical learning. While preserving ToSpeakG3’s strengths—stable voice quality, speaker similarity, and controllability—the product achieves a significant improvement in overall sound quality. As a result, in addition to its integration into conventional embedded devices, synthesized speech is increasingly being used to replace human voices in announcements and audio guidance. Today, it is increasingly used in applications that generate synthesized speech for creating voice files.
• ToSpeakHx, ToSpeakHx Pro
These products adopt a speech synthesis approach based on deep learning. The synthesized speech it generates is significantly more natural than that of previous products, and it accurately reproduces individual speakers’ voices, making it suitable for customers who require specific voice profiles. By applying Toshiba’s proprietary DNN compression technology, the ToSpeakHx series achieves reduced memory usage, enabling efficient integration into embedded devices. As with previous products, this system supports sequential generation of synthesized speech. As of 2025, this is Toshiba’s flagship SDK product.
Toshiba's SDK products are integrated into customer applications and services as software components that generate synthetic speech data. For example, in hardware-based products, our SDKs are utilized in automotive systems such as car navigation units, as well as in various home appliances. In software-based products, they are employed in applications like video games and smartphone apps. Over the past three decades, our SDK products have continuously evolved, incorporating a variety of speech synthesis techniques to adapt to the specific requirements of the environments in which they are deployed—including system constraints, available computational resources, and required performance levels.
Unlocking expressive speech synthesis through dictionary-based techniques
We will now explain one of the key components of our SDK products: the dictionary. There are three types of dictionaries used in our SDK. Language dictionaries help convert any input text into accurate pronunciation. Prosody control dictionaries and speech unit dictionaries are used to reproduce the voice characteristics of reference speakers, including their voice quality and speaking style.
Language dictionaries include system dictionaries and user dictionaries. System dictionaries provide standard pronunciations and rules for pronunciation changes according to various factors, including linguistic and phonetic contexts. User dictionaries are used to specify preferred readings for proper nouns and technical terms that are typical in certain regions or specialized fields but may not be found in general dictionaries.
Maintaining user dictionaries requires knowledge of the typical readings of individual words. For this reason, user dictionaries are typically maintained by SDK users using tools provided by Toshiba. However, for certain high-demand domains—such as place names and song titles—Toshiba provides ready-to-use dictionaries. Additionally, custom dictionary development services are available upon request.
Prosody control dictionaries use linguistic information from the input text to reproduce the accent, intonation, and rhythm patterns of a reference speaker. Accent, intonation, and rhythm serve not only to convey linguistic information—such as marking intonational phrase and accentual phrase boundaries and accent nucleus positions—but also to express the speaker’s emotion, intent, attitude, vocal habits, and other paralinguistic features.
Speech unit dictionaries are used to reproduce the voice timbre and tone of a reference speaker, based on phonological information from the input text and prosodic patterns generated by the prosody generation module. In addition to expressing linguistic distinctions—such as phonemes—through speech waveforms, vocal characteristics also reflect the speaker’s articulatory traits (i.e., individual voice timbre) and variations in tone influenced by emotional state or speaking style.
Advancements in speech synthesis technology have enabled more precise vocal expression and enhanced the ability to reproduce speaker-specific traits, such as articulatory characteristics and vocal mannerisms. However, even with these advancements, it remains difficult to estimate the intended emotion, intent, or attitude from a single sentence when generating synthesized speech. Prosody control dictionaries and speech unit dictionaries are developed for specific speakers and speaking styles—for example, a dictionary tailored to Speaker A’s reading-style speech. Therefore, customers are encouraged to consider the desired voice quality and speaking style appropriate for their intended purpose and application, and to select and apply dictionaries accordingly. Dictionaries can also be developed in response to specific customer requirements.
The prosody control and speech unit dictionaries used in each SDK product—collectively referred to as “speech dictionaries”—are available in three types: standard dictionaries, optional dictionaries, and custom dictionaries.
Standard speech dictionaries are designed for general use within the target applications of each SDK product. Each SDK product includes speech dictionaries for one male and one female speaker. To create a speech dictionary that captures not only the narrator’s voice but also their emotional tone, intent, attitude, and unique speaking style, we begin by selecting a narrator with a calm and pleasant vocal quality. The narrator reads a manuscript tailored to the intended application, and the recorded audio is then used to build a comprehensive dataset that reflects the narrator’s expressive characteristics.
Optional speech dictionaries are not general-purpose datasets. Instead, they are designed for specific use cases that require distinct tones or speaking styles to convey a particular impression. These dictionaries are developed by selecting narrators or voice actors whose vocal qualities suit specific applications. They are recorded reading a manuscript using a speaking style that is carefully adapted to the intended use of the synthesized speech. In SDK products, speech dictionaries are often developed to expand the range of voice characteristics available for targeted applications. When a more purpose-specific vocal quality or speaking style is desired, custom dictionaries are prepared to better match the intended use.
The final type of speech dictionary is the custom dictionary, which is developed in collaboration with customers. We work closely with customers to understand the kind of impression they wish to convey to listeners, and adjust the speaking style accordingly. The manuscript is modified to support the desired delivery, and a narrator—selected by the customer—is recorded reading the revised manuscript. This recording is then used to create the custom speech dictionary. By clarifying the intended use, selecting a narrator with an appropriate vocal tone, and aligning their speaking style with the application context, it becomes possible to generate synthesized speech that matches the feel of the customer’s product or service. However, when emotions, intent, or attitude need to be adjusted based on the listener's situation or the usage context of the customer's product—for example, when multiple settings require different vocal tones and speaking styles—speech is recorded for each scenario, and separate speech dictionaries are developed and used accordingly. This approach enables the generation of speech responses that convey the appropriate impression for the specific context in which they are used.
In this way, while the pure quality of synthesized speech—such as its naturalness and clarity—is not dependent on the individual speaker or usage scenario, speech dictionaries (including Prosody control dictionaries and speech unit dictionaries) play an important role in enabling the generation of speech that aligns with the specific characteristics of a customer's product or service. In addition, when developing these dictionaries, we consider factors such as their overall data size and the content and size of the data stored within them—including the number of bits allocated to each data item and the total number of items—since these directly impact the memory usage and processing load required at runtime.
Toshiba has been developing core speech synthesis technologies and new features for many years, while continuously improving the quality of the synthesized speech. We provide SDK products that can be embedded into a wide range of hardware and software platforms. In this article, we introduced the components of our SDK products, the current lineup of our speech synthesis middleware “ToSpeak,” and a brief overview of previous SDK offerings. In this way, Toshiba’s SDK products are designed to support both the quality and individuality of synthesized speech.
In the next article, we will explore rights related to speakers and sound sources—important considerations when using speech synthesis technologies. We will also examine global trends and future developments in this field. Stay tuned.

NISHIYAMA Osamu
Expert
RECAIUS Business Dept., Digital Engineering Center
Toshiba Digital Solutions Corporation
Since joining Toshiba, NISHIYAMA Osamu has been involved in the research and development of speech synthesis technologies. He has been working to expand sales of products and services that utilize speech recognition and speech synthesis technologies since 2012. He is now also engaged in speech technology product planning.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of August 2025.
- ToSpeak is a registered trademark or trademark of Toshiba Digital Solutions Corporation in Japan.
- All other company names or product names mentioned in this article may be trademarks or registered trademarks of their respective companies.


