


Speech technologies are used to create human interfaces that provide users with greater convenience and comfort in a wide range of applications and situations. Speech technology research and development has been conducted for years, but in recent years there have been particularly significant strides in their practical performance. Devices that have previously needed to be controlled by hand are increasingly being operated by voice, and in a growing number of cases, devices are also providing information to users in the form of speech. At the same time, however, actual use of speech technologies involves various challenges, such as the time it takes for systems to respond, the degree to which speech can be accurately detected in real-world environments, speech synthesis performance, and the memory size and computation demands placed on devices in which the technologies are embedded. Toshiba supplies high-performance, compact speech recognition and speech synthesis technologies developed through its long years of research and development. These technologies take the form of RECAIUS speech middleware, a functional component that can be embedded in all kinds of devices and services. Let's look at the features of RECAIUS speech middleware and its use in the vehicle on-board device field.
Eyes are turning to speech technologies for their ability to provide greater accessibility
In recent years, devices and services that use speech are becoming increasingly common in people's lives. Smart speakers, which have become more familiar over the past few years, can perform various voice-based operations triggered by the detection of a specific phrase, known as the " wake-up word(s)/phrase." Specifically, the contents of the voice command that follows the wake phrase can be used to play music, look up information online, and even turn on or off the lights in one's home. Car navigation systems and smartphone voice control functions have also become frequently used features thanks to how convenient they are to use. Portable translation devices use voice recognition to detect what people are saying, translate it, and play the translations using speech synthesis. Speech recognition and speech synthesis technologies are being used to create human interfaces in all kinds of devices and services around the globe.
Attention is also being turned to speech for its accessibility benefits. For example, in situations in which users do not have their hands free, such as when they are driving an automobile, users still require accessibility, such as the ability to control devices using their voice or to obtain information about their situation through speech. This kind of speech support doesn't just improve usability, but also helps provide services to people with visual impairments.
Many devices, such as smart speakers, utilize a speech recognition system in which the majority of processing is performed in the cloud and which accepts spoken words other than predetermined word sequence so that they respond to the words spoken freely and naturally by the users. These systems are designed with the assumption that audio data captured by the device's microphone can be transferred to the cloud and be received the recognition results from the cloud via the internet. Because of this architecture, if internet connectivity is poor, systems can be slow to respond to user commands, and system functionality can be limited. Response delays and functional limitations can not only frustrate users, but also, depending on how devices are used, can even have safety repercussions, so these kinds of situations must be avoided whenever possible.
Toshiba supplies RECAIUS speech recognition and speech synthesis middleware that are embedded in and works on local devices nearby the users. Both don’t need cloud connectivity, even in offline environments, so that users can enjoy convenient, stress-free speech interaction with a variety of applications.
Highly user-friendly speech middleware achieved thanks to Toshiba's longtime AI technology expertise
Speech recognition and speech synthesis functions are often used in user interfaces, so they provide a great deal of value to users by having rapid, smooth response. Quick response is also one of the key features of our speech recognition and speech synthesis middleware. They respond far faster than speech recognition and speech synthesis systems using the cloud because our two middleware works on local devices and don’t need to wait time for transferring input data and receiving their processing result via the internet.
Small calculation cost and small memory footprint are also the major key features of our speech recognition and speech synthesis middleware. Our two middleware needs less memory to store data such as dictionaries and acoustic models. Such features are achieved by Toshiba's long years of research and development in the speech AI field.
The reduced computational cost means that the speech middleware can run on general-purpose processors, so the speech recognition and speech synthesis functions can be deployed using the hardware resources already available in devices*. This reduces development costs and the time taken to replace with high performance hardware.
* Devices running speech middleware must have the sufficient processing power to execute software functions that run on general-purpose processors.
Our two speech middleware uses fewer resources and thus stands out for its ability to operate independently on local devices without relying on the cloud for its primary speech recognition and speech synthesis processes. What's more, it can be used as a speech recognition and speech synthesis application programming interface (API).
Almost 30 languages* are supported, making it reliable and easy to use speech middleware for companies in Japan that are developing products for overseas markets, thanks to Toshiba's many years of experience with developing speech technology for the Japanese language, which is linguistically quite different from European languages, both in terms of vocabulary and grammar.
* The number of supported languages varies depending on the product version.
In addition to providing functions like these, we also provide technical support to customers who feel uneasy about their ability to fully utilize the middleware. In general, speech recognition performance is significantly affected by the acoustic environment, including ambient sound in the space where the speech recognition is used. Toshiba is able to inform the ways to tune parameters or to select keywords for better performance. Also, when using speech synthesis to convert text into speech, Toshiba is able to advise to tune the text. Even simple adjusting the way words are read or paused can be effective for the ease of listening. We have an extensive track record of speech middleware deployment, and this has provided us with a great deal of knowledge and expertise regarding speech middleware in embedded systems.
We supply two types of speech middleware that have these features, dedicated respectively to speech recognition and speech synthesis functions.
VoiceTrigger RECAIUS speech recognition middleware ("VoiceTrigger") provides a function for analyzing waveform data captured by a microphone, including ambient sounds, to identify speech containing pre-defined keywords ("spoken keywords"). ToSpeak RECAIUS speech synthesis middleware ("ToSpeak") converts text data into synthesized speech.
VoiceTrigger and ToSpeak, suitable for embedding in devices
VoiceTrigger, which detects spoken keywords in user speech, uses deep learning technology for advanced detection performance and resource demand minimization (with both low computing overhead and small memory size), and it offers rapid response. Responses feel immediate, and spoken keywords are detected as soon as they are spoken.
Multiple keywords can also be configured for VoiceTrigger. For example, using words each of which means operation commands as keywords and customer’s application system are designed to operate each command when VoiceTrigger detects the keywords, users can perform actions simply by saying the corresponding keywords. Even if the keyword appears in continuous speech, VoiceTrigger will detect the spoken keyword, making it easier and more convenient for users (Fig. 1).
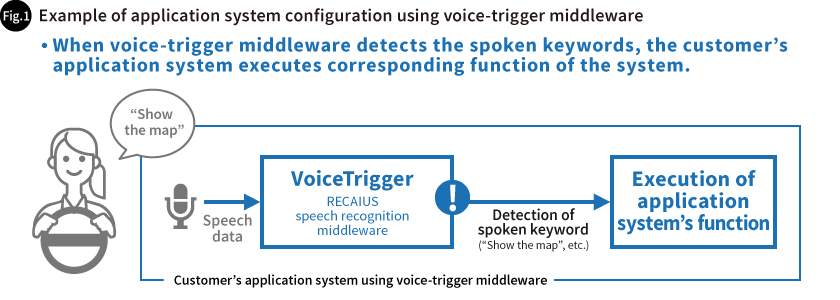
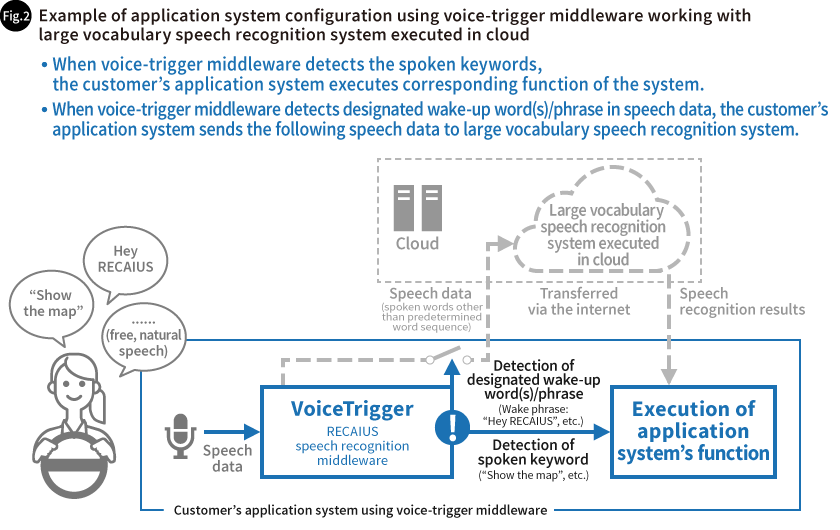
VoiceTrigger’s spoken keyword detection is also used for switching speech recognition processing from VoiceTrigger to the cloud service (the keywords are used as a wake-up word(s)), so that spoken words other than predetermined word and predetermined word sequence are dealt by the cloud service.
For example, if VoiceTrigger detected that the user had said "Hey, RECAIUS," the cloud service could use the natural speech that followed to search for information. This would make it possible to meet customer needs without reducing usability (Fig. 2).
VoiceTrigger comes in two varieties: an existing standard product with basic functions for use in typical operating environments such as computers or smartphones, and a built-to-order product with basic functions intended for use in vehicle on-board devices and other functions developed specifically for vehicle cabins. The on-board version has functions for suppressing accidental operation in response to overlapping voices, such as comments by vehicle passengers or the sound of the radio playing from the car's speakers. We have also developed an acoustic model focused on providing better speech recognition performance in environments with an extremely high level of noise, such as the background noise inside a vehicle that is in motion.
* The contents of the acoustic model will vary depending on the product version and language.
The use of a dedicated VoiceTrigger makes it possible to achieve excellent performance even in environments with high noise levels. VoiceTrigger for vehicle on-board devices has also been used in mass-produced car navigation systems.
ToSpeak, which provides speech synthesis functions, has a track record of over 20 years of use in on-board devices such as car navigation systems. Recently, it has been applied in the entertainment field in applications such as games, and is increasingly being used together with custom voices such as voice actors' voices. It's also used in smartphones with car navigation functions and in portable translation devices, so you've probably already heard ToSpeak synthesized voice in your own life.
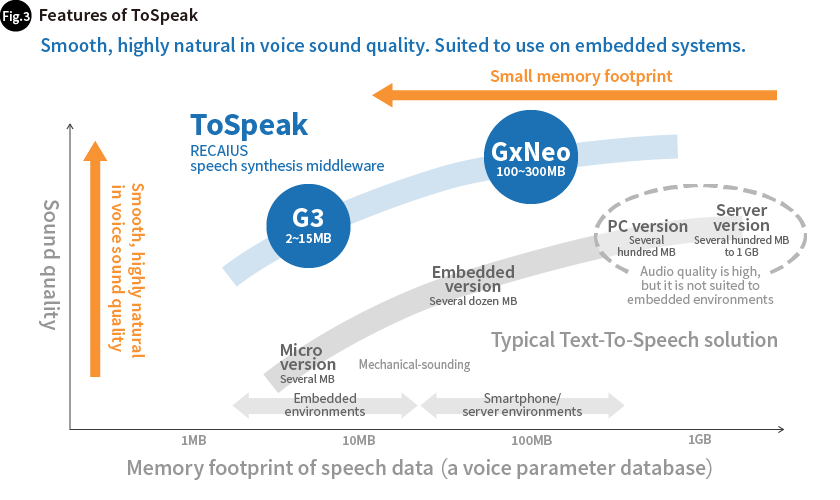
Usually, the major part of the memory footprint of speech synthesis (text to speech) is speech data (a voice parameter database), which is used to convey the features of different people's voices, such as their tone of voice, rhythm, and intonation. ToSpeak has a compact voice parameter database yet produces extremely smooth, high-quality audio, two features that complement each other.
There are two types of ToSpeak, so users can select the one that best fits their needs. ToSpeakG3 offers stable sound quality with a small memory footprint and is suitable for embedding in devices. ToSpeakGx Neo provides a more speaker-like and natural-sounding synthetic voice (Fig. 3).
The keys to automobile on-board use are immediate response and autonomy
In the automobile industry, technical development aimed at autonomous driving is advancing at a rapid clip. Automobiles are outfitted with numerous sensors, and these sensors are being used to detect automobile status changes, weather conditions, road conditions, and other nearby conditions. This data is increasingly being used to make holistic evaluations and to provide this information and related suggestions to the driver in a timely fashion.
Voice-based interaction with the vehicle provides drivers with greater safety and security. When vehicles ask their drivers for instructions, and when they receive instructions from their drivers, it is extremely important that their speech interfaces respond immediately and that the vehicles can operate independently, without relying on the internet connection environment. For example, if the vehicle response lags, the vehicle will continue to move forward while it is processing a command, which will make the driver feel uneasy. If the range of available functions depends on whether the vehicle has an internet connection, it will reduce the amount of attention the driver can pay to their driving.
Speech recognition has the potential to be highly effective for using shortcuts that enable drivers to easily call on the vehicle functions they often use. As vehicles make progress toward autonomous driving, the number and range of functions they offer will continue to increase, going beyond just basic vehicle functions.
Using voice-initiated shortcuts (keywords) using VoiceTrigger is a much more convenient way to call up frequently used functions than selecting them from an on-screen menu. For audio played by the vehicle, such as announcements from the vehicle to the driver or responses to driver announcements, instead of simply playing back synthesized readings of text, greater effectiveness can be achieved by modulating the tone of the synthesized voice based on the situation. We believe that as the amount of driver-vehicle interaction increases, these elements will become even more important, which is why we are further refining ToSpeak to provide even more natural and pleasant synthesized speech.
The number of devices and applications that use speech will continue to rise in a wide range of industries. Toshiba will meet the changing needs of the times, contributing to companies and societies through the solutions that it is developing by leveraging the speech technology expertise and insights it has accrued through the years.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of September 2022.
- RECAIUS is a registered trademark of Toshiba Digital Solutions Corporation in Japan.
- ToSpeak is a registered trademark of Toshiba Digital Solutions Corporation in Japan.
- RECAIUS speech middleware, RECAIUS speech recognition middleware, RECAIUS speech synthesis middleware, VoiceTrigger RECAIUS speech recognition middleware, ToSpeak RECAIUS speech synthesis middleware, ToSpeakG3, ToSpeakGx Neo, and our other products mentioned in this article are not currently available for direct purchase from outside Japan.


