


A diverse range of consumer-oriented devices, such as appliances and car navigation systems, use speech to relay information to users. They are used to make announcements on trains and buses, and also for the lines spoken by characters in smartphone apps and video games. Until now, speakers have been recorded and their voices have been played back as audio on devices, but thanks to recent evolutions in speech synthesis technology, artificially created synthesized voices are increasingly being used. Toshiba has many years of experience with speech synthesis technologies. We have developed numerous fundamental technologies that create more natural, higher quality speech. In this three-part special feature, we will discuss societal trends related to speech synthesis, the features of Toshiba's technologies, the frontlines of product development, and the future outlook for the use of these technologies throughout the world.
First, let's look at where speech synthesis is being used, representative speech synthesis technologies, and the features of Toshiba's technologies.
Speech synthesis is being used in increasingly diverse applications and scenarios
Speech conveys the content of the actual words that are spoken, but at the same time it also communicates nonverbal information, such as emotion. It shares information effectively even when the listener cannot see the speaker, whether it is because they are too far away or because of the respective positions of the listener and the speaker. It also enables communication when the listener is not concentrating, such as when they are doing something else. That makes speech a natural and exceptionally timely form of communication.
Speech synthesis technology is used to create human voice from text prepared by the user. It can also be made to sound like a certain speaker by using recordings of that speaker to model the features (speaking style, tone of voice, etc.) of the speech that is generated. Speech synthesis technologies are widely used in various everyday situations and applications because they make it easy to utilize the features of speech (Fig. 1).

A typical example of speech synthesis usage is the functional components (speech generation systems) that are used to form interfaces between devices and people. These components are being used in various consumer products, business systems, and services, such as car navigation systems. Car navigation systems use speech to relay information about routes, traffic conditions, weather, and more. They make it possible for users to absorb this information and use it to arrive at their destination, all without taking their eyes off the road. By using speech, these systems can provide information tailored to current conditions in a timely manner. Combining speech output with visually displayed information, such as maps, conveys the information more effectively and efficiently. Furthermore, since information is conveyed using speech, the screen can be made more compact, reducing costs for product suppliers.
Next, if synthesized speech is made to sound more natural (more human, easier to understand, etc.) it can be used in place of human speakers in operations and services that were previously handled by people. In the past, human speech was recorded for use in making fixed announcements and providing guidance information, and live human speakers handled the announcing of information and the providing of explanations based on changing current conditions. Speech synthesis technologies are now being widely used in this area, as well. Text data is being entered as needed, converted to speech, and played back. Examples of this include narration by docents in museums, speech guidance for educational materials, and public transportation announcements in stations, vehicles, and the like. Speech synthesis technologies can be used to keep down costs for those that want to provide detailed information updated in a timely fashion.
These technologies have become even more expressive and better at replicating the distinctive character of speakers who provide speech samples to be used as models—their way of speaking and their tone of voice. Synthesized voice is therefore increasingly being used not only to relay information, but also to mimic speakers with appealing voices, like voice actors and narrators*. One example of this is the creation of speech for characters in anime and games. This enables creators to supply richer content and provides users with better experiences.
As these speech synthesis technologies evolve further and gain greater recognition in society, they have the potential to be used in an even more diverse array of applications and scenarios.
* In Part 3, we will discuss trends related to voice rights, the management of recorded audio, and the like.
Fundamental speech synthesis technologies
Generating (synthesizing) natural, high quality voice from user-defined text data requires the creation of speech waveforms that are easy for people to understand and that have natural-sounding accents, intonation, rhythm, and the like for each language and region. Furthermore, to create synthesized voice that conveys information in a natural-feeling way and sounds more like the voice of a particular speaker whose voice was recorded as the synthesized voice's model, the speaker's way of speaking and distinct vocal characteristics must be extracted from the recorded voice with a high level of precision. The voice synthesis system must then be able to reproduce that speaker's voice in the speech waveform generated for the user-defined text.
This involves the use of various different technologies. In our explanation of basic speech synthesis technologies, we will divide the technologies into the two basic processes involved: the generation process, in which speech is generated from text, and the learning process, which is used to derive parameter values for the speech synthesis inference model.
• The generation process
Synthesized speech is generated through the use of three operations: text analysis, rhythm generation, and speech signal generation (Fig. 2).
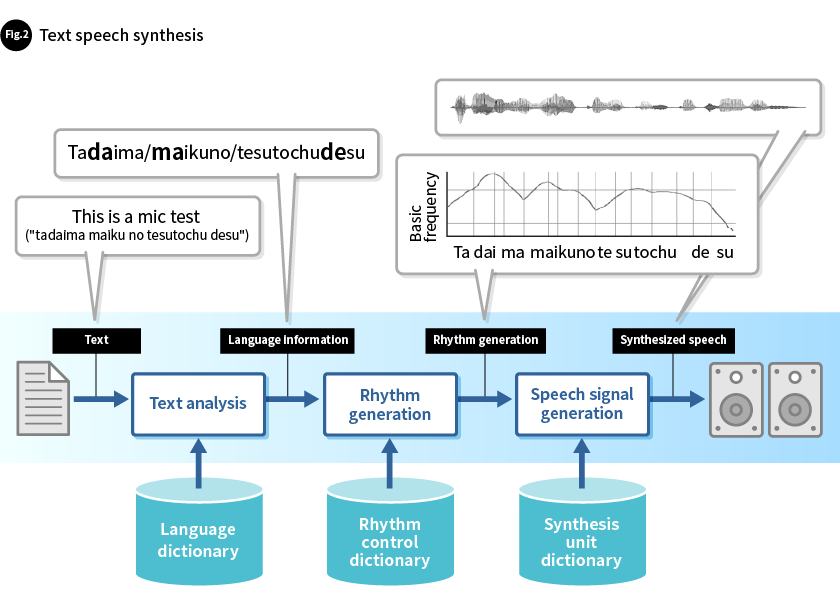
In the first operation, text analysis, user-defined input text is analyzed using a language model (rules and a language dictionary) and standard language information for the desired language is output. Language information consists of divisions between words and morphemes (the smallest units of language with meaning), parts of speech, and other language attributes, and also readings (strings of symbols that express the types of sounds necessary to express linguistic meaning), tone unit divisions for accents, intonation, and the like, along with the positions of change points that serve as the cores of individual tone units and the degrees of change at these points.
Next, in the rhythm generation operation, an inference model with a rhythm control dictionary is used to generate phonetic and rhythm information—change patterns for physical quantities such as voice (sound) pitch and length—based on parts of speech, readings, accent positions, and other qualitative variable language information that is output by the text analysis process. Phonetic and rhythm information includes patterns of change over time for basic frequencies (the pitch of the voice) (referred to hereafter as "basic frequency patterns") and information about how long each phoneme should be held for (its length). These are used to describe the accents, intonation, rhythm, etc. of the synthesized speech. Of all these elements, basic frequency patterns have the biggest impact on how natural the voice sounds and the unique characteristics of the generated voice.
The last operation is speech signal generation. Here, fundamental speech fragments used in speech synthesis and synthesis units are selected and connected based on the phonetic and rhythm information to generate the speech waveform. The methods used to select and connect individual synthesis units affect how natural the voice sounds and how well the speaker's vocal qualities are reproduced.
• Learning
Each processing component in the generation process uses various inference methods and models, and the values used as the parameters for each model (model parameters) are obtained by learning. To improve the quality of synthesized speech, Toshiba is continually coming up with new models and methods for learning parameters and developing speech synthesis systems that use them. In the next section, we will introduce typical examples of these technologies.
Furthermore, to improve the quality of synthesized speech, it is important not only to come up with new inference and learning methods, but also to think about parameters such as feature quantities and the characteristics of processing inputs and outputs, methods for deriving their values, and methods for collecting a speech corpus (a large amount of speech data with information for use in learning) so that highly accurate inferences can be made and highly efficient learning can be performed. The method used to gather data and create the corpus covers questions like "What data should be collected?" "What should be included in order to efficiently create a corpus?" "What direction should be provided to speakers so that the desired audio can be recorded?" This expertise regarding speech corpus design is vital for the practical application of speech synthesis. This is because no matter how good the audio quality of a speech synthesis method may be, haphazardly increasing the range or amount of recorded speech or the computing resources used in feature quantity extraction, machine learning, or inference processing will negatively impact the speech synthesis method's practical utility as an industrial product.
In speech synthesis, various technologies are interrelated in complex ways.
The features of Toshiba’s speech synthesis and the unique technologies that support them
Our speech synthesis technologies generate smooth, natural synthesized speech from user-defined text, and they do so using little memory and with little computational overhead. These features are made possible by the following unique technologies used in the processing components responsible for rhythm generation and speech signal generation.
• Closed loop learning
The essence of closed loop rhythm and synthesis unit learning, a basic method Toshiba developed roughly three decades ago, lies in formulating the differences between recorded speech and synthesized speech and then using recorded speech to automatically learn the synthesis units that can minimize those differences. It eschews the ad-hoc development methods that were previously used, in which engineers would make individual adjustments and improvements whenever they found unnatural-sounding parts in synthesized speech. With the creation of this closed loop learning method, computation is used to acquire optimal synthesis units from the entire corpus of the recorded speech used for learning. Learned models and synthesis units are used when generating synthesized speech from text. This revolutionary method can perform speech synthesis with little computation and while using little memory, without the need to search for rhythm information or synthesis units from massive databases.
• Representative pattern codebook method
The method we developed, which uses closed loop learning to learn rhythm patterns, is called the representative pattern codebook method. Basic frequency patterns extracted from recorded audio are used as model examples, and learning is performed using collections of typical basic frequency patterns in units of phrases (accent phrases), called representative pattern codebooks, together with rules for selecting and controlling them. The forms of representative pattern codebooks vary from speaker to speaker, and the rules are dependent on the recorded speech. This makes it possible to generate basic frequency patterns that capture the distinctive features of individual speakers.
• Plural unit selection and fusion method
When all of the synthesis unit options available to the speech signal generation component are far separated from the target context (basic frequency, duration time, preceding and following phonological units, etc.) (or when there are no options), the sound quality will momentarily decline.
Toshiba has developed a method for dealing with this. Multiple synthesis units whose context is partially close to individual synthesis units such as phonemes or syllables are selected from the recorded speech and fused to generate a new synthesis unit. These fused synthesis units can then be connected in accordance with the rhythm information to generate stable, uniform speech that doesn't sound nasal, muffled, or low resolution.
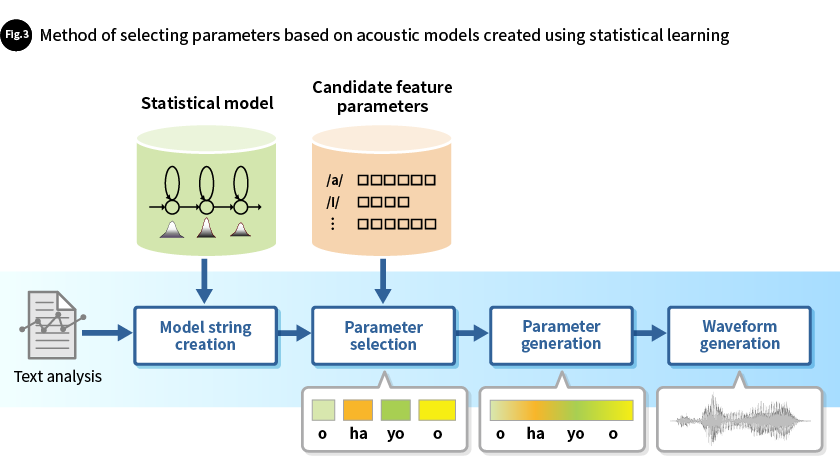
• Method of selecting parameters based on acoustic models created using statistical learning
We have developed a speech synthesis method that uses a statistical model known as a hidden Markov model (HMM). This model is highly compatible with technologies that are effective in improving the diversity of synthesized speech, such as technologies for controlling adaptation to individual speakers or for controlling the emotions expressed in speech. Initially, this method had a problem: when the feature parameters of speech were modeled with a feature quantity distribution model, it caused excessive smoothing, which reduced the reproducibility of speech. To solve this problem, we made improvements to the method. Instead of using values derived from a modeled distribution, we introduced statistical methods for selecting from the original training data that had been used to create the distribution. Feature parameter values selected from the recorded speech using these statistical methods (feature values which had not been smoothed) were then smoothly changed to generate clear feature parameter strings with a minimal sense of discontinuity. Furthermore, by introducing new feature parameters that consist not only of power spectra (the intensity of the energy for each frequency component) but also phase information that expresses speech waveforms (the position along the time axis of each frequency component), this method made it possible to precisely reproduce speech. This eliminated the problem of excessive smoothing and increased the expressive capabilities of the generated speech, resulting in both greater diversity and improved sound quality. Furthermore, it also improved the reproducibility of the speech by the speakers used as model examples (Fig. 3).
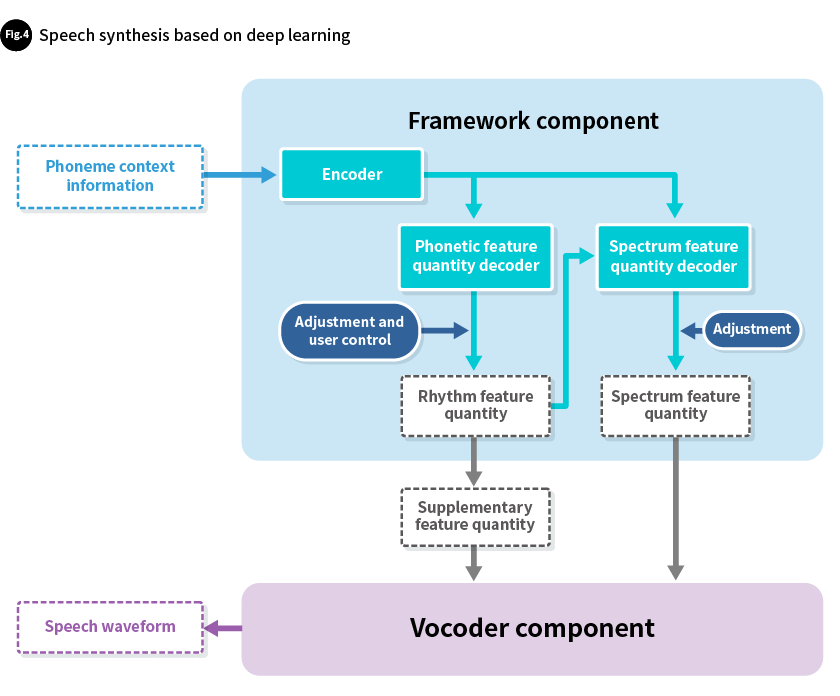
• Speech synthesis based on deep learning
In recent years, with the introduction of deep learning, the quality of synthesized speech has improved significantly. While maintaining the functionality of our existing speech synthesis products, we have also developed a speech synthesis method that leverages deep learning in order to achieve even better speech quality. This method separates the decoder that determines feature quantities into two separate decoders—one for rhythm feature quantities and another for spectrum feature quantities. This makes it possible to adjust each feature quantity as necessary. The generation of spectrum feature quantities and the processing of the vocoder that generates speech waveforms from spectrum feature quantities, supplementary rhythm feature quantities, and the like are used in sequential steps. This shortens the response time from when phoneme context information is first input to when speech waveforms start to be output. What's more, thanks to Toshiba's proprietary DNN (deep neural network) compaction technology, this method uses less memory than conventional methods (Fig. 4).
We are continually coming up with new fundamental methods, developing new functions, and making quality improvements while developing speech synthesis technologies that use fewer resources, so they can be embedded in various devices. In this issue, we have explained modern speech synthesis trends and the features of Toshiba's technologies. In the next issue, we will introduce technologies for creating various types of speech, focusing on Toshiba's "ToSpeak" speech synthesis middleware, which is in use in a large number of companies. Don't miss it.

NISHIYAMA Osamu
Expert
RECAIUS Business Dept., Digital Engineering Center
Toshiba Digital Solutions Corporation
Since joining Toshiba, NISHIYAMA Osamu has been involved in the research and development of speech synthesis technologies. He has been working to expand sales of products and services that utilize speech recognition and speech synthesis technologies since 2012. He is now also engaged in speech technology product planning.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of March 2025.
- ToSpeak is a registered trademark or trademark of Toshiba Digital Solutions Corporation in Japan.
- All other company names or product names mentioned in this article may be trademarks or registered trademarks of their respective companies.


