


The release of ChatGPT by OpenAI shook the world. In just two days from its release, ChatGPT was being used by one million people. In two months, that number rose to 100 million. The use of ChatGPT is spreading at a rate unprecedented in history. Everyone -- not only AI researchers and specialists, but also companies, politicians, experts, and members of the general public -- is surprised and fascinated by generative AI such as ChatGPT and is watching closely to see what impact it will have on society. How will generative AI change the IT industry? How will it affect businesses and social systems? And how will our own lives be changed by generative AI? In this running feature, we will focus on large language models (LLMs), the foundation of generative AI. We will learn about their key technical points, how they can be used in business, and their future prospects.
In part one, we presented the nature and position of generative AI with respect to AI technology as a whole. In part two, we looked at Toshiba Digital Solutions’ own efforts from the perspective of using generative AI in actual business operations. In part three, the final part of this series, we will envision the society of the future—a society in which generative AI is part of our everyday lives. In the first half of this issue, we will focus on initiatives for applying AI to multimodal application and to improving design and development operation efficiency, two fields where we are currently carrying out verification testing. In the second half of the issue we will explain the ideal evolutionary path for AI and how it connects to people, as envisioned by Toshiba Digital Solutions.
Skip to the second half of the issue.
The two major potentials for generative AI, as indicated by research papers on scaling laws
Generative AI is AI that produces new results in a form that is easy for humans to understand. It is fundamentally different from conventional discriminative AI, which excels at tasks such as image identification and product defect detection, both in how it operates and in the roles that it fulfills. One of the ways used to implement large language models (LLMs) is the transformer[1] method, which has contributed significantly to the advancement of modern generative AI. Transformers were originally language data processing models developed for the machine translation of English, German, and French. The appearance of the transformer model led to more in-depth research regarding the extent to which LLMs understood and could freely operate on language. This research found that generative AI can not only process language and document data, but can also process various other types of data using the same framework with high accuracy.
Humans use “language” to communicate. When we speak, first we think of the concept we wish to communicate. We then communicate this concept by arranging words into sentences and arranging multiple sentences in sequences. In other words, we form sentences by assembling symbols (words) and then we assemble datasets of these sentences. We relay these datasets to listeners, who then interpret (understand) the meaning being conveyed. This data processing is performed in the brains of both the speaker and the listener. To be able to perform this sequence of processes, we must understand all kinds of combinations of words, sentences, and meanings. This is the state of understand “language.”
Then, how many combinations of words and sentences would a machine (AI) need to understand to engage in human-like communication through the medium of language? The results of research and verification of this question are represented in two OpenAI papers[2][3] on scaling laws*. They point out two startling potentials of generative AI. The first is that the more one expands three variables that affect AI learning computation, the more the AI’s language comprehension capabilities grow, following a scaling law. To verify this prediction, over 70 million high-quality documents were fed into an AI. Vector computation of a tremendous scale, with 175 billion parameters and 12,288 dimensions, was performed in a research experiment that cost tens of millions of USD per month in computational resources (including data center power costs) (Fig. 1). The result of this work was the GPT-3 model, released by OpenAI in 2022, and the ChatGPT service that uses this model. The capabilities of ChatGPT and the GPT-3 model are now well-known.
* Scaling laws for natural language processing are laws which determine model capabilities based on just three variables: the model size (number of parameters), the size of the dataset being trained on, and the computation volume used in training.
![Fig. 1 Scaling law for three variables in paper[2] (computation volume (C), dataset size (D), and no. of parameters (N))](/content/toshiba/ww/company/digitalsolution/articles/tsoul/tech/t0703-1/_jcr_content/root/contentsArea/mainarea/layoutcontainer/layoutcontainer/image_208283237_copy_550555433.coreimg.png/1720508457992/et0703-zu-01.png)
Another predicted potential of generative AI is that scaling laws would apply even if the information fed into the transformer was not language data but instead various other forms of data, such as images, audio, and sensor values. This is known as multimodal data. Experimentation showed that for all kinds of datasets, as long as it was possible to recognize that the content of the data was meaningful for people, the transformer could grasp the structure of the dataset and understand its meaning (Fig. 2).
![Fig. 2 Scaling law for multimodal data in paper[3]](/content/toshiba/ww/company/digitalsolution/articles/tsoul/tech/t0703-1/_jcr_content/root/contentsArea/mainarea/layoutcontainer/layoutcontainer/image_208283237_copy.coreimg.png/1720508468832/et0703-zu-02.png)
For example, an image is expressed by the dataset “a horizontal and vertical spatial arrangement of the three primary colors of light.” A human understands the meaning of the image (what is expressed) from it. In the same way, the transformer can understand the meaning of image from the dataset that makes it up, and vice versa. The DALL-E[4] image generative AI developed by OpenAI is testament to this.
Using generative AI on multimodal data to help solve the problems faced by manufacturing sites
The ChatGPT service has drawn a great deal of attention for how overwhelmingly skilled it is in answering questions using natural language. The application of generative AI to document processing has accelerated rapidly. On the other hand, as the papers[3] show, generative AI has the potential for application to a wide range of datasets, not just language (documents). That is why, in addition to using generative AI for document processing, Toshiba Digital Solutions is focusing on promoting the development of advanced technologies that enable generative AI to handle diverse multimodal data. This includes sensor data and inspection data from manufacturing equipment in the industrial and manufacturing fields, images and video, work activity logs, daily reports, and communications (conversations) between workers.
Manufacturing factories assess the quality of their products and manage their production equipment. They accumulate huge amounts of field data, extract the information they need from these datasets, process it, and compare data to make judgments. This requires personnel who are highly skilled at determining things, such as what data needs to be extracted, what analysis methods should be applied, and how the data should be presented. Even when personnel with these abilities are assigned, preparing data just when it is needed is still not an easy task. This is because conditions in factories are constantly changing, so personnel need to organize data flexibly and rapidly based on current conditions. In many cases, there is just not enough time to prepare data.
What manufacturing sites truly want to focus on is looking at and compare data from many different angles and determining potential solutions to their problems. They do not want to set aside large amounts of time for tasks such as data extraction and processing. These worksites, which wish to delve deeply into issues and resolve them, want to be able to compare and investigate data from various perspectives when they need to and to use their findings in discussions and suggestions that help them solve the problems they face.
Integrated management tools, business intelligence (BI) tools, and other general tools have functions for extracting data, creating graphs that explore it from various angles, comparing it, and changing how the data is shown. All of these can be accomplished with existing tools. The difficulty lies in using these tools effectively, as desired, in a way that matches worksite expectations. Until now, the “translation” portion of the process involved in determining worksite expectations and operating tools was taken care of by personnel skilled at using analysis tools. This information translation is one of the areas at which generative AI excels.
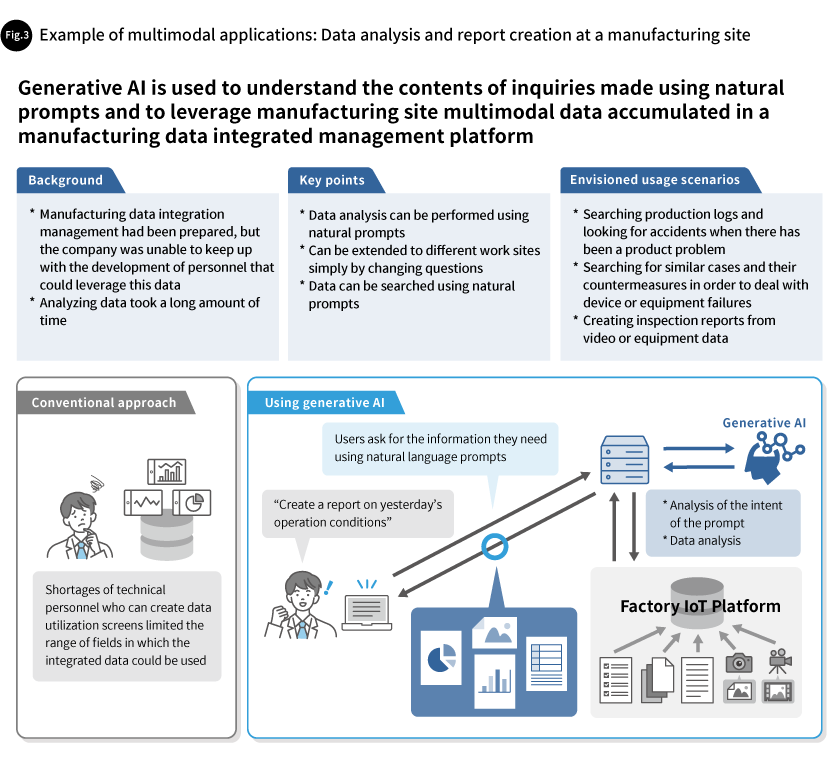
We have developed systems in which generative AI is used as intermediaries between manufacturing data integrated management platforms and site workers and are experimentally verifying these. In these systems, the generative AI is responsible for visualizing and analyzing manufacturing data and for generating reports. Specifically, we are developing systems in which the data viewing requirements (expectations) worksites needed are provided to generative AI using natural language. The generative AI then performs data processing, including interpreting the intent of the natural language prompts, extracting appropriate data that fits the intent, processing and analyzing the data, determining how to present the results, such as through graphs or tables, and presenting the data in forms that meet the expectations of worksites (Fig. 3). If, for example, there is a device or equipment failure, this makes it easy to ask the system, using natural language prompts, about similar cases and the measures that were used to deal with them, as well as recent operating conditions. The system can answer these inquiries in a way that makes it easy to perform comparisons and carry out investigations.
Applying generative AI to software design and development operations to interpret legacy programs
Around the world, various initiatives are being carried out to use generative AI to automatically generate program code[5]. There is a great deal of sample code, such as web sites, user interfaces, and general-purpose data processing modules on various internet sites, so existing generative AI is being trained on this data. Therefore, program code with similar objectives can be generated with a high level of accuracy.
Because of this, expectations have been high for generative AI to be used in the same way to generate program code for industry and commercial applications. However, there is very little existing publicly available program code for industrial or commercial applications, so not enough sample code can be collected for training. In particular, for industrial applications, industry- and job-specific data processing is essential. Due to factors such as this, existing generative AI cannot be trained on industrial or commercial program code, or on the program code used in them for proprietary data processing. Furthermore, the design documents, external specifications, test specifications, and other documents created in these fields contain many terms, passages, and notations that existing generative AI have not been trained on. For example, if someone who knows nothing about violins were to try to explain one, they would not be able to accurately describe its shape or tone. In the same way, a generative AI that has not been trained on the program code and design document notation and terminology used in a specific field will not be able to accurately generate code to be used in that field.
Conventional generative AI is known to struggle when generating program code in the industrial and commercial fields. However, we believe that it has the potential to improve operational efficiency by solving other issues related to software design and development operations. We have been carrying out verification testing of this hypothesis.
There are three major issues encountered when designing and developing software for use in the industrial or commercial fields. The first is that systems still use program code written in old programming languages (legacy programs). Very few people still understand these old programming languages, and maintenance for legacy programs is slow-going. Migration—replacing large swaths of legacy programs in old systems with code written in new programming languages—carries a high risk of causing problems in systems that, until now, have been functioning without problem, so little progress is being made with migration. This continued use of old systems is developing into a societal problem.
The second major issue is that, in addition to general code-writing ability, creating program code for industrial applications requires design techniques, specification creation techniques, and program development techniques that are specific to the corresponding industry or business. It takes novices or beginners of particular fields a long time to learn these techniques. The shrinking labor force is causing personnel shortages in every industry, so companies and organizations are stretched too tight to set aside more time for passing on these techniques and developing personnel. This is becoming a serious societal problem.
The third major issue is that guaranteeing the quality of developed program code requires the creation of complete and comprehensive test specifications and the conducting of extensive testing. This takes many person-hours and is reliant on the expertise of veteran personnel, so it tends to become highly dependent on individual people. This is often due to implicit knowledge, in the form of the knowledge and know-how specific to individual industries, businesses, and companies. This implicit knowledge is often the domain of individuals within these organizations, and it is difficult to pass this knowledge on to others. In quality assurance operations, when using documents and program code written by others to design new tests, it is often necessary to read between the lines. This is one of the fundamental problems that makes it difficult to eliminate reliance on individual personnel and to improve quality and productivity.
Generative AI is capable of using combinations of massive datasets to determine the meanings of information in datasets within their learning models. When it is applied to industry and business-specific designs and development, generative AI can assess the features of design documents and test documents created for specific industries or organizations and understand implicit knowledge that has not been passed on to others. This means it has the potential to create new program code and design documents.
In the industrial and commercial fields, it is not uncommon for there to be massive amounts of old systems using legacy programs that continue to operate stably. However, these legacy programs often use old programming languages like COBOL, which are seldom used today. Documentation can be sparse or missing entirely. The meanings of designs can be unclear.
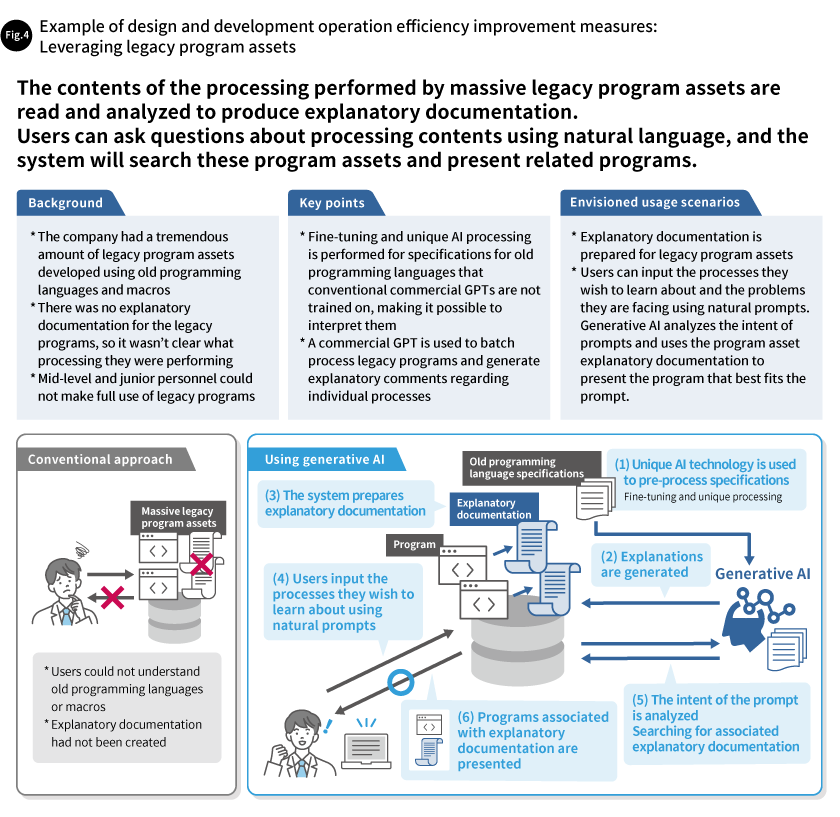
That is why we are carrying out verification testing in which we use generative AI to interpret program code written in old programming languages and to generate documents (explanatory documentation) that explains how the programs operate. This would make legacy programs easier to understand for personnel who cannot interpret the program code directly. Using the generative AI technique called “fine-tuning,” in the future it may be possible for generative AI to express implicit knowledge that is hard to pass on, such as the intentions behind designs and points of note in test specifications, thereby assisting in reading and interpreting design documentation (Fig. 4).
We will explain our vision of the ideals of AI’s evolution and the new shape of relationships with AI in the second half of this issue.
Reference materials
[1] "Attention Is All You Need" Ashish Vaswani, Noam Shazeer et al., 12 Jun 2017
[2] "Scaling Laws for Neural Language Models" Jared Kaplan, Sam McCandlish et al., 23 Jan 2020
[3] "Scaling Laws for Autoregressive Generative Modeling" Tom Henighan, Jared Kaplan, Mor Katz et al., 28 Oct 2020
[4] Automated image generation by DALL-E: "an armchair in the shape of an avocado" https://openai.com/blog/dall-e/
[5] For example: GitHub Copilot, https://github.com/features/copilot/

KOYAMA Noriaki
Senior Fellow
ICT Solutions Division
Toshiba Digital Solutions Corporation
KOYAMA Noriaki had researched software design optimization and real-time distributed processing in Corporate Research & Development Center of Toshiba. At iValue Creation Company, he had been engaged in new business development for cloud services, knowledge AI, and networked appliance services. At Toshiba Digital Solutions, he has led business, technology, and product development for the RECAIUS communication AI, and currently directs several projects related to generative AI, product management, and cloud delivery platforms.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of March 2024.
- All other company names, product names, and function names mentioned in this article may be trademarks or registered trademarks of their respective companies.



