


The release of ChatGPT by OpenAI shook the world. In just two days from its release, ChatGPT was being used by one million people. In two months, that number rose to 100 million. The use of ChatGPT is spreading at a rate unprecedented in history. Everyone -- not only AI researchers and specialists, but also companies, politicians, experts, and members of the general public -- is surprised and fascinated by generative AI such as ChatGPT and is watching closely to see what impact it will have on society. How will generative AI change the IT industry? How will it affect businesses and social systems? And how will our own lives be changed by generative AI? In this running feature, we will focus on large language models (LLMs), the foundation of generative AI. We will learn about their key technical points, how they can be used in business, and their future prospects.
In the first issue, we will talk about the nature and position of generative AI with respect to AI technology as a whole and discuss its technical implementation.
The acceleration of AI technologies that began with the third AI boom
Technologies such as the internet and AI are known as “exponential technologies,” because they grow exponentially. The term artificial intelligence (AI) was first used in 1956, at an academic workshop in Dartmouth College. The goal of AI at the time was the replication of human intellectual activity, such as learning, by a machine. This goal has remained fundamentally unchanged.
The technological evolution of AI and its widespread use in actual society began accelerating rapidly starting in the early 2010, and it is continuing to develop explosively as we approach 2030 (Fig. 1). For companies, it is vital that they not be late in adopting rapidly growing AI technologies, but instead that they deploy them in their own business.
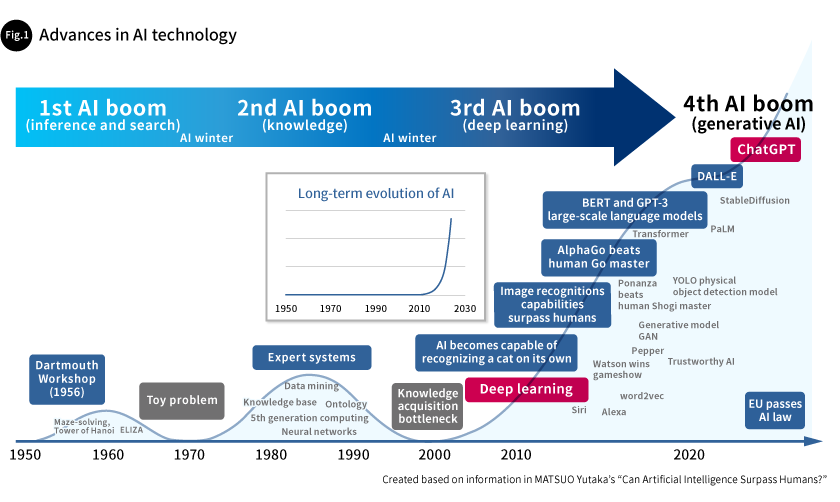
AI has undergone three major booms. The first AI boom took place in the 1960s, followed by the second boom in the 1980s, and then the third boom, which started in the early 2010s. The first and second AI booms each subsided due to a lack of technical refinement and computational capabilities, and they were followed by so-called “AI winters.” However, in the third AI boom, the appearance of deep learning technologies and the dramatic advances in computational capabilities enabled by graphics processing units (GPUs) made it possible to develop large AI models using massive amounts of data. These advances provided AI with inference abilities (classification and regression abilities) that far surpass those of humans, improving their capabilities by a startling degree and accelerating moves towards their practical application.
During the latter half of the 2010s, advances in deep learning-based AI technologies focused on image data and time-series data began to slow, but language model technologies began developing rapidly. The greatest leaps were made by large language model (LLM) technologies, which generated a great deal of excitement with the release of ChatGPT in 2022. LLMs have empirical rules called “scaling laws,” which says that their prediction accuracy is controlled by the exponential product of three factors: computation volume, the number of AI model parameters, and the amount of training data. This means that the faster the computation, the greater the amount of memory, and the greater the amount of data, the greater performance the AI will be able to achieve. Some say that with the appearance of generative AI, we have entered a fourth AI boom.
Over the long-term, AI technologies have been growing exponentially.
The principles of image generation using the diffusion model and text and program generation using LLMs
The main features of conventional AI have been broadly categorized as “classification” and “regression.” Classification refers to the ability to categorize input images, such as distinguishing between dogs and cats or between good products and defective products. Regression refers to the ability to make future predictions based on past data. This is used in predicting stock prices and detecting signs of potential failures. Starting with the third AI boom, these functions have been achieved by connecting multiple layers of neural networks, learning to determine the weighting parameters of these connections to create AI models specialized for specific purposes.
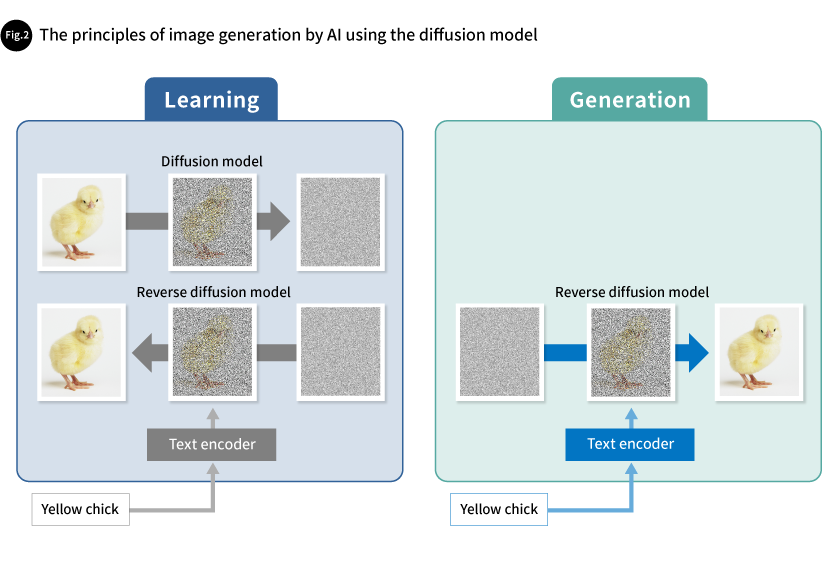
Generative AI like ChatGPT, on the other hand, can generate or analyze various information, such as images, text, and programs. Therefore, it can be used in a wide range of applications. AIs with diverse functions such as these are also called “foundation models.” Image generation AIs primarily use a method called the diffusion model method to automatically generate images based on text prompts. Learning is performed by first using a diffusion model to convert input images into noise. The converted noise is then used to reconstruct the original image based on the text prompt. This process creates a learned model (reverse diffusion model) that is used to generate images from noise based on text prompts (Fig. 2). The quality of the images generated with this model has already reached the level of being indistinguishable from actual photographs.
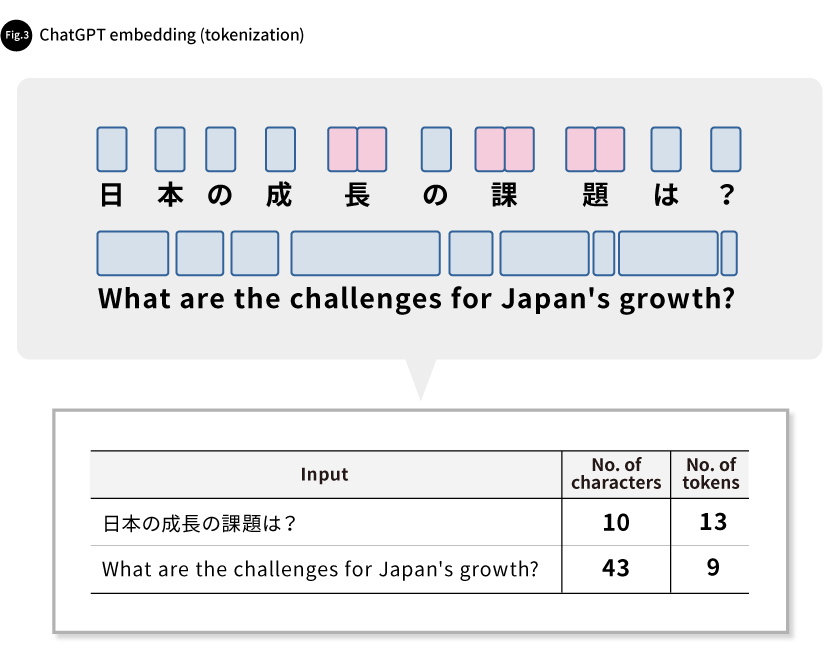
LLMs used to generate text or programs use the Transformer technology developed by Google and the University of Toronto in 2017. Transformer uses massive amounts of training data to predict the word that will appear next or to fill in blanks, thereby learning languages and acquiring knowledge. It works by automatically generating the character string with the highest probability of being the reply to an input character string. LLMs automatically convert input character strings into the smallest meaningful units and input them into the AI. These units are known as “tokens,” and an input character string broken up into tokens is converted into numerical information (vectors). This process is called embedding.
Let’s explain using an example of Japanese and English embedding by ChatGPT. The English is tokenized in units of words, and the number of tokens is smaller than the number of input characters. In the case of the Japanese, on the other hand, each character is made up of one token or even multiple tokens, resulting in a higher number of generated tokens compared to input characters (Fig. 3). ChatGPT is trained using data from the internet, so the vast majority of its training data is said to be in English. There have been discussions about whether ChatGPT is better when operating in English or Japanese, but no definitive conclusion has been reached as it varies on a case-by-case basis. The Tokenizer[1], provided by OpenAI, can be used to confirm what kinds of tokens ChatGPT has converted input text into.
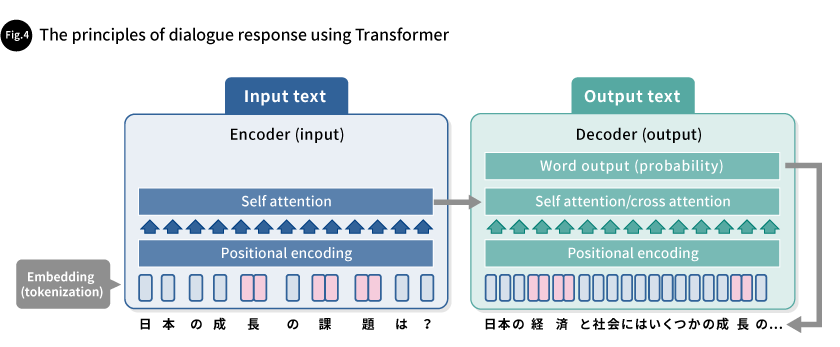
Let’s talk about the principles of the dialogue responses ChatGPT gives using Transformer. The encoder (input) section tokenizes the input text and adds word sequence information to each token in a process called positional encoding. The strength of the relationships between each token is then analyzed. The analysis of the token relationships uses a method called “self-attention” to analyze the context of the input text. Self-attention is a distinctive feature of Transformer, not seen in conventional language processing AI, that analyzes input strings as a whole rather than in sequential parts.
The information regarding the input text analyzed by the encoder is sent to the decoder. Calculations are then performed to generate potential outputs, and the word with the highest probability is output. The output words are then input into the decoder again, and the decoder’s self-attention layer analyzes the context of the generated output. The cross-attention layer analyzes the relationship between the generated output and the input text. Through this analysis, the word with the highest probability of being the next word is output, and this newly output word is sequentially inputted into the decoder again. In this way, the output sentence is sequentially generated (Fig. 4).
Peripheral technologies essential for effectively and continuously utilizing generative AI
To effectively utilize generative AI, it is important to use various peripheral technologies to make up for the LLM’s shortcomings (Fig. 5).
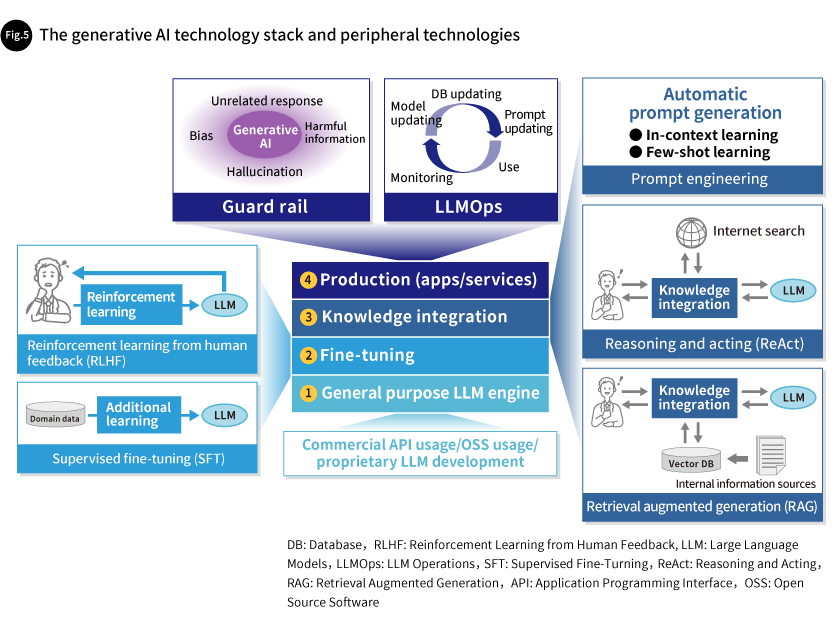
LLMs only have the knowledge in the data that was used to train them, so they cannot provide answers regarding content that is not in the data they have learned. One way of expanding their knowledge is fine-tuning, which trains them with additional new data. However, LLM AI models are massive, and fine-tuning requires enormous computing power. This is why the main method currently being used to generate output is retrieval augmented generation (RAG), which is combined with database searches. Another highly effective method is reasoning and acting (ReAct), which uses LLM for inference and then uses actions such as automated internet searches to obtain the latest information and generate output. With these technologies, AI can provide appropriate responses even regarding material they have not previously been taught, without the need for fine-tuning.
LLMs produce output that has the highest probability given the input character string, so the output they produce is not necessarily correct. They can confidently provide incorrect information in a phenomenon known as hallucination. LLMs can also provide unethical or harmful answers. That makes it important to prevent erroneous or inappropriate responses. For example, with reinforcement learning from human feedback (RLHF), models are revised by training them using human feedback. Guardrail technologies are used to control the responses generated by generative AI.
Generative AI can also rapidly approach appropriate responses depending on how the prompts provided to it are crafted. The use of prompts to temporarily train LLMs is called “in-context learning,” which includes “few-shot learning,” in which several responses are given (the LLM itself is not updated). Learning these technologies, known as “prompt engineering,” takes time and effort, so one effective method is to automate part of the prompt generation process itself within the software. Long-term use of generative AI requires models and related databases to be updated and automated prompt generation to be improved. LLM Operations, or LLMOps, are important for making these ongoing improvements.
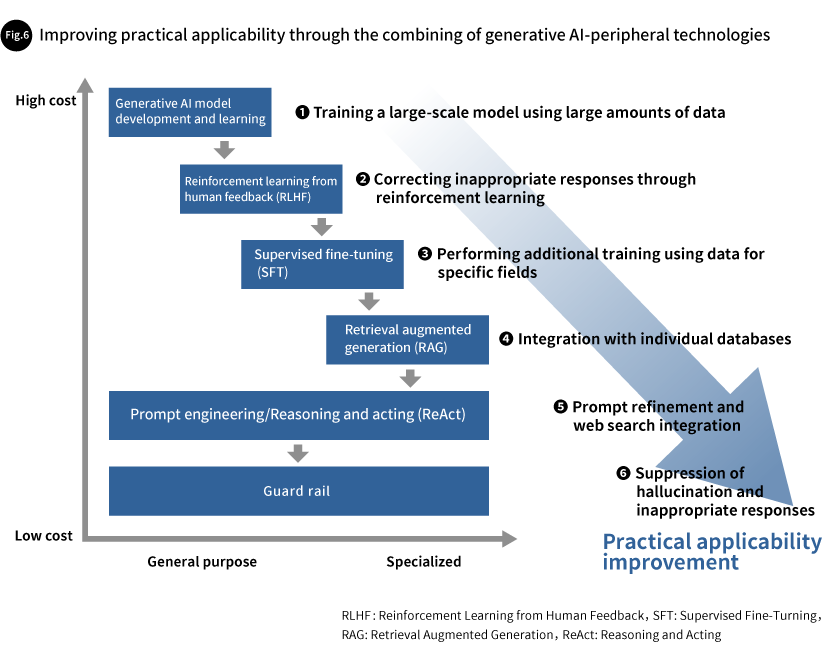
One of the keys to effectively using generative AI is to leverage not only the capabilities of LLMs themselves but also to use them in combination with peripheral technologies to achieve a higher level of practical applicability (Fig. 6).
The changes generative AI will bring about in society - Greater operational efficiency, higher quality, and value creation
Since the third AI boom began, the use of AI in business has been increasing in the US, and it has been reported that ROI is steadily increasing[2]. However, in Japan, while AI has been used in proof of concept (PoC) projects, its application in actual environments has usually been limited, and its diffusion has been slow. Under these situations, although the US has the highest number of ChatGPT users, followed by India, Japan comes in third[3]. Given the populations of these countries, the high expectations Japanese people have for generative AI is evident.
The exceptional capabilities of generative AI, paired with the unreliability of its answers, make it a double-edged sword, so various countries are moving to strengthen their AI regulations. For example, the EU has adopted a proposed AI act, and in the US the president has issued an Executive Order on the development of generative AI. In Japan, the Hiroshima AI Process[4] was proposed in 2023 and is leading international rule-making efforts. Its approach of maximizing the benefits of the technology while mitigating its risks was included in the G7 Leaders’ Statement issued at the G7 Summit presided over by Japan. Japan’s approach to promoting AI utilization through soft laws* differs somewhat from the stance being taken by the West. Due to this state of affairs, there is a rising AI development and utilization movement in Japan, and over half of the companies in Japan are interested in using generative AI.
* Soft laws: Guidelines, voluntary rules, and other social norms that are not legally binding
A great deal of attention is also being turned to the use of generative AI in raising work efficiency and improving operations. Japan has an especially low birth rate and an aging population, so it faces problems such as labor shortages, a lack of young personnel to whom more experienced personnel can pass on their skills, and work style issues such as long working hours. Hopes are high for the use of generative AI to help solve these problems. According to a paper by OpenAI[5], using LLM can shorten work hours while maintaining quality levels for roughly 15% of all work done within the US. Furthermore, work software that uses LLMs could expand this to between 46 and 56% of all work. There are also expectations that generative AI will not only improve work efficiency but also provide additional value, such as improving work quality and creating new value. The question we all face now is whether to use AI well and achieve success, or to be left behind.
The appearance of generative AI has resulted in the real possibility of artificial general intelligence (AGI), general-purpose artificial intelligence with intellectual abilities equivalent to or surpassing humans, being developed in roughly 2029 and the singularity* occurring in 2045. As AI technologies continue to evolve, it has become extremely important to use AI, not to be used by it. At the same time, the increased use of AI has also created concerns about increases in the amount of power consumed by AI. We believe that the evolution of AI-based technologies and the evolution of technologies that contribute to carbon neutrality must go hand-in-hand.
* The singularity: The technological turning point when AI develops more sophisticated AI on its own, resulting in an explosion of AI evolution that culminates in AI that far surpasses humans
The entire Toshiba Group is tackling the issues posed by generative AI through collaboration with industry, academia, and government
Toshiba has launched projects to promote the use of generative AI and is accelerating Group-wide efforts to improve productivity and create new customer services. We are expanding the use of generative AI in various fields. Internally, we are using it to improve efficiency for various operations, design, and development. For enterprises, it is being applied to various existing solutions. We are also using it in fields such as the energy, social infrastructure, and manufacturing fields, where the Toshiba Group can leverage its own real-world strengths. Furthermore, we are enhancing our collaborations with customers, partner companies, universities, and the National Research and Development Agency to promote the utilization of generative AI in business and to actively carry out research and development aimed at solving the technical problems inherent in generative AI (Fig. 7).

In this issue, we have talked about the nature and position of generative AI with respect to AI technology as a whole, and we have discussed its technical implementation. In the next part of this series, we will look at how generative AI is used in actual business, using examples of Toshiba’s own efforts. Don’t miss it.
Up next: (Part 2) The business impact of Generative AI
Reference materials
[1] https://platform.openai.com/tokenizer
[2] https://www.pwc.com/jp/ja/knowledge/thoughtleadership/2023-ai-predictions.html
[3] https://www.nri.com/jp/knowledge/report/lst/2023/cc/0526_1
[4] https://www.mofa.go.jp/mofaj/ecm/ec/page5_000483.html
[5] https://browse.arxiv.org/pdf/2303.10130.pdf (PDF)

KOTO Shinichiro
General Manager
Advanced Intelligent Systems Technology Center
Corporate Research & Development Center
Toshiba Corporation
Since joining Toshiba, KOTO Shinichiro has promoted the practical application of advanced digital media technologies in Toshiba’s Corporate Research & Development Center. He is also a member of Toshiba Digital Solutions and leads the development and business usage of technologies that leverage advanced AI such as Toshiba’s SATLYS analytics AI.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of January 2024.
- All other company names, product names, and function names mentioned in this article may be trademarks or registered trademarks of their respective companies.


