


The use of sound as a means of communication has made great advances in society and in our daily lives. Thanks to these advances, we enjoy greater freedom and convenience in our handling of information. However, the audio information that surrounds us would cause some problems, such as sounds interfering with each other and listener’s fatigue caused by long-time listening. In the future, it will become an even more important viewpoint on how sounds should be heard to offer better use for the people. Toshiba has been developing technologies for use in our sound solution, Soundimension Sound with Controlled Distribution and Stereophony. Our concept is providing sound to people in desirable way. We have commercially released two Soundimension products: Soundimension for the Sound Images with controlled Stereophony and Soundimension for the Sound Field Control.* In this three-part serial article, we will show our concept, the expected applicability and the core technologies of our solution, sound images with controlled stereophony and sound field control for region separation.
In part one, we presented expected new ways of hearing sound and an overview of the sound technologies that will make them possible.
In part two, we introduced one of Toshiba’s core technologies, sound images with controlled stereophony. In part three, the final part of this series, we explain Toshiba’s other core sound technology, sound field control for region separation.
* This includes products scheduled for release in the fiscal year 2023
Toshiba’s sound field control technology
In part one, we explained sound field control for region separation technology. This Toshiba’s sound field control technology creates a spatial distribution of sound pressure for the sound output from speakers, producing places where sound is clearly audible and places where it isn’t. In addition, we introduced two concepts behind the development of this technology: One is using a simple system to enable users to enjoy the benefits of sound field control, and the other is realizing the change of sound pressure distributions at selected locations within a space without changing hardware configurations.
In introducing sound field control for region separation technology, the theme of this article, we explain the position of this technology within the various approaches to achieve sound field control.
Sound field control technologies can be broadly divided into two approaches: technologies that control the sound pressure of sound output through speakers within a space, and technologies that reduce the sound pressure of sounds generated in a location, not just sounds from speakers, within a space (this is known as active noise cancelling).
The former technologies change the sound pressure of sounds i.e. sound volume, according to the location within a space, delivering sound to where it is needed. In other words, it is a technology to make sounds properly audible.
This is effective for providing information such as voice guidance or announcements to the people who want to listen can hear it clearly. On the other hand, the latter is normally used to cancel out sounds around the listener so that they do not hear the sound.
For example, these technologies are effective in lowering the amount of undesired noise, such as that produced by worksites or machinery.
The two different approaches require the use of different technologies (Fig. 1).
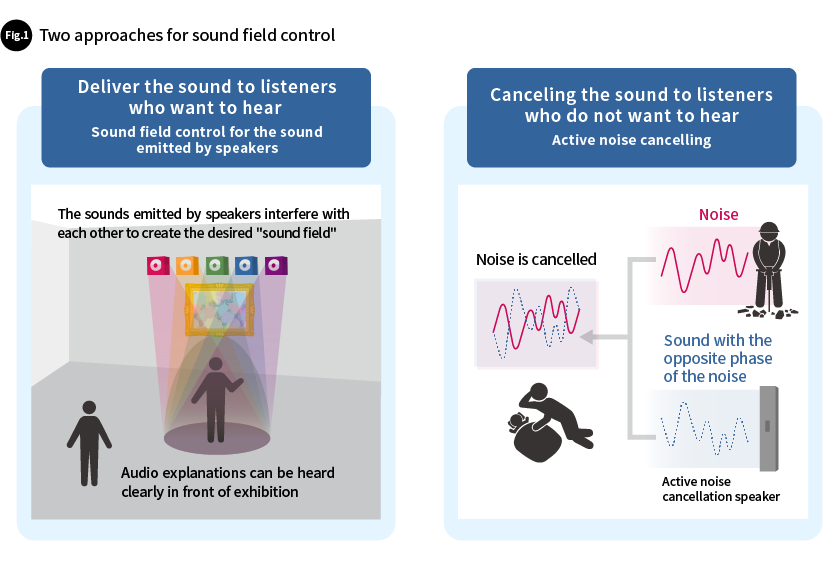
The sound field control for region separation technology we have developed as our core technologies of Soundimension for the Sound Field Control is the former category. It aims to convey audio information clearly and in a pleasant manner rather than cancel sound within an area. This is based on our sound solution concept of making more active use of sound as information.
Toshiba’s sound field control concept
Now we show our sound field control for region separation technology concept and the technologies that will make it possible.
The technologies that are used to control the sounds output from speakers have been known commonly. Its principle is that sound pressure is distributed arbitrarily within a space by emitting sounds from an array of speakers and controlling their phases. Highly directional speakers, such as ultrasonic speakers, also can be used to create separate areas with differing high and low sound pressures.
However, controlling sound fields with these ways requires the particular facilities as ultrasonic speakers or a large number of speakers. These speakers can be costly and take up space. This had limited the applicable situation for sound field control technologies.
To make it possible to use sound field control in various locations and situations, we have the following three concepts of sound field control for region separation (Fig. 2).
- Creating a sound pressure distribution area by a small number of ordinary speakers without enclosing the entire space. In addition, controlling the sound distribution over a distance of roughly one meter for use in personal spaces.
- Controlling the area to which the sound is delivered by the software operation instead of adjusting the configuration of each hardware respectively.
- Including the low frequency band sound, which is considered difficult to control, in the handling input sound, as a result, the range of sound sources that can be processed is expanded.
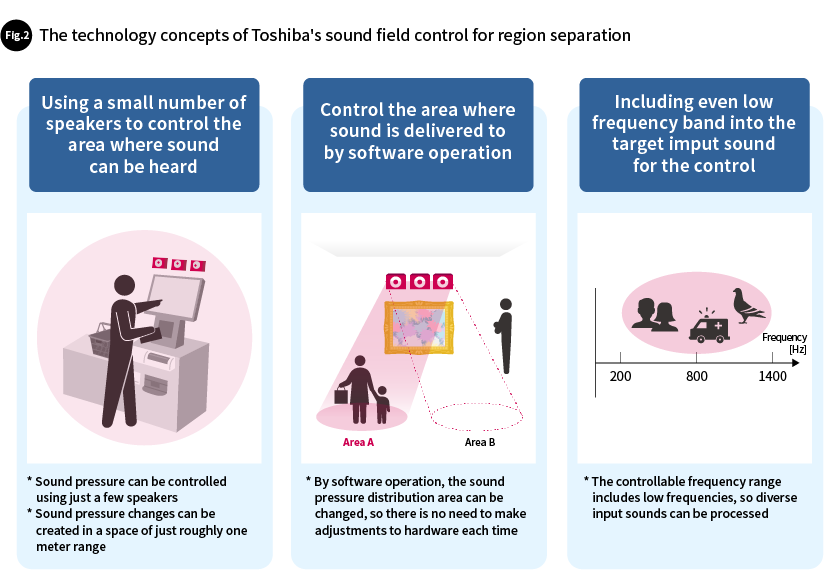
By enabling a small number of conventional speakers to be effective in controlling the sound field without surrounding the space with a group of speakers, a range of sound applications could be broadened. In addition, by controlling the sound distribution of the areas with a range of roughly one meter, this technology could be used for the cases where the listener is one or so and not wearing wearable speakers.
Furthermore, minimizing the number of elements that must be custom-tailored to the usage application, and using general purposes devices, makes it possible for anyone to use these technologies at little cost. Controlling the directionality of sound including long wavelengths (low frequencies), which is difficult when using conventional phase delay control, expands the range of frequencies that can be used in controlled sound sources. This makes it possible to use various types of sounds. These concepts all contribute to enhance freedom in use cases.
To make these concepts a reality, we began by establishing a technical approach for controlling sound pressure using speakers of N numbers, and then we worked to reduce the value of N.
In general, the smaller N is, the less the freedom of the controllability of sound pressure is, and the greater the technical difficulty is. We created opposite phases between speakers even when small numbers of speakers were used. As a result, we currently can produce sound field controls with an N value of just three -- in other words, just three speakers.
And now, creating a sound pressure distribution within a small, roughly one meter space requires additional ingenuity. Creating a steep sound pressure gradation over a small area is difficult, because sounds do not attenuate much with distance.
In situations, such as when providing automated voice guidance at a small device like an ATM or ticket machine, when speaking with a customer contact point, or when taking part in an online meeting, the sound is often transmitted to other people, besides just the person to whom the sound is directed. Therefore, when considering the transmission of sounds to the people who need it, it is important to realize “small space control” that enables the creation of sound pressure distributions not only in larger 5 to 10-meter areas but also over compact areas of a meter or less.
To make this “small space control” a reality, we decided to combine two types of control low: control that reduces acoustic power*1, a characteristic value that indicates the energy level of a sound source, and control that maximizes sound pressure within an area. We have balanced the use of these two types of control low in our method what we call the “Combination method” (which we refer to hereinafter as the “C method”).
The C method, which makes it possible to realize both types of control with three speakers, has succeeded in creating a sound pressure gradient over a small space.
*1 Acoustic power: The rate at which sound energy E[J] is emitted by a sound source per unit of time (1 sec). Acoustic power is represented in units of watts (W=[J/s]). The acoustic power level is 10 times of the logarithmic value of W/W0, where W0 is the reference value of acoustic power. It is represented in units of decibels (dB). It is a characteristic value that indicates the level of sound energy of an audio source, and differs from the acoustic pressure level which changes with measurement distance.
Considering actual usage situations, the locations and sizes of areas where sound is meant to be heard might differ even within the same space. It would be extremely time- and labor-intensive to rearrange speakers or change speaker types to produce the desired characteristics every time. Furthermore, an approach that required optimization by engineers every time when use case changed would cause obstacles to the use of these sound field control technologies in general-purpose applications.
That is why we worked to design a technology based on the concept of using software control, without needing to change hardware configurations. This technology would optimize and control the distribution of areas with high sound pressures and areas with low sound pressures by software control, once the number of speakers and their locations had been decided. We were also able to include the sound with low frequencies which are hard to control using conventional approaches, into the controlled objects, by adjusting “virtual boundaries,” which are set when adjusting phases.
To make it clear that Toshiba’s sound field control technology could be used to select areas and control the sound pressure distributions within them using simple systems, we named the technology “sound field control for region separation technology.”
What is the C method of sound field control for region separation?
There are several approaches for sound field control for region separation technology. The key features of our C method used in Soundimension for the Sound Field Control, mentioned above, are that amplification and cancellation of the sound are operated at the same time. It controls sound pressure and acoustic power to simultaneously create areas where sound is to be louder (amplification) and where it is to be quieter (cancellation).
When it would be needed to amplify sound in one specific direction only, one way to do this would be to add speakers and superpose the sounds from them. However, we increased volume by combining sound from a few speakers, in this case three, without adding any other speakers, and used the principles of acoustic power minimization control to create areas where the volume decreases from the base. By combining these, we have realized both amplification and cancellation of the sounds within a small area.
This method requires to place N speakers (currently three speakers) as one group to control the sound pressure distribution, so this way makes it possible to produce a sound pressure gradation over the area around the speakers without the need to have the speakers enclose the area.
In addition, the latitude of the design of the sound pressure distribution is also its feature. Speakers are placed optimally with respect to the core frequency of the input sound source to produce desired sound pressure distribution. On the other hand, the location of the sound pressure distribution generated within the space is not fixed in response to the speaker arrangement. Instead, it is selectable, so software control can be used to change the location where sound is to be heard, without the need to move any speakers.
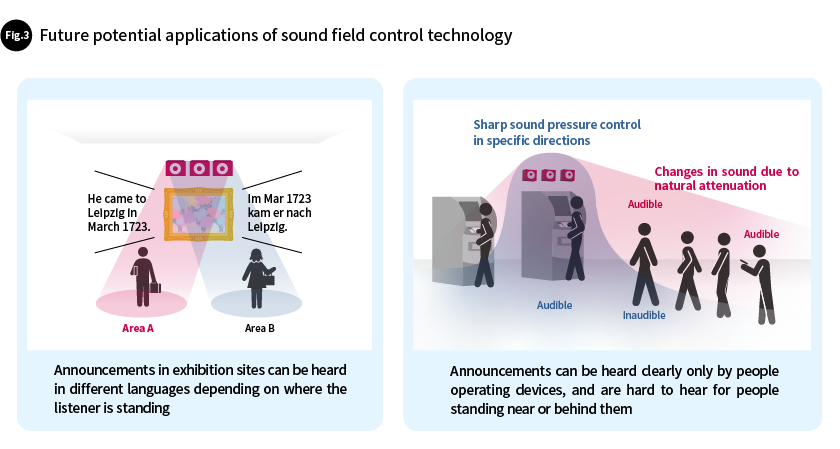
Further refining this feature would enable the overlapping of multiple distributions. This makes it possible, for example, to overlap different sound distributions for different sounds so that announcements could be heard in Area A while background music was heard in Area B.
The future of sound field control technology
In this way, to decrease the obstacles in utilizing sound field control to realize, we have developed our technologies without the need for large or special-purpose hardware. We aim to make this technology become part of everyday social infrastructure that is not limited to special spaces like event sites, movie theaters, and concert halls, but instead is used in a wide range of peoples’ day-to-day lives.
To make this vision a reality, we will continue to work to address the challenges faced in using a small number of speakers in a simple arrangement to produce benefits consistently in many situations.
For example, the effectiveness of sound field control varies depending on the usage environment: in a highly sound-absorbent location such as a home or automobile, in a semi-open environment such as in the ticket machine areas of train stations, or in front of digital signage in shopping malls. By further enhancing the sharpness of the sound pressure gradients over space, we will make it even more consistently effective, unaffected by differences in usage environments.
Furthermore, it is theoretically possible to play different content or content in different languages at the same time, so that only A' can be heard in Area A and only B' can be heard in Area B. However, there remain many technical hurdles before this can be achieved in a truly effective manner. In addition to that when the linearity of sound is too high in specific directions, the sound pressure would be requested to drop off sharply, rather than relying solely on natural attenuation. We plan to address these challenges then create even more varieties of ways of hearing sound and meet a wide range of needs (Fig. 3).
Through the three articles of this series, we have provided an overview of the sound solutions being developed by Toshiba and the sound images with controlled stereophony technology and explained sound field control for region separation technology that are at the heart of these solutions. Toshiba is creating further new applications for audio information and even clearer and more pleasant listening experiences for people with software controllability and simple, general-purpose equipment to control sound directionality and location-specific audibility.
We will continue to develop technologies and create solutions that contribute to the creation of a society where audio information is used comfortably in new ways.

Yuki Yamada
Expert
New Business Development and Marketing Dept.
ICT Solutions Div.
Toshiba Digital Solutions Corporation
Since joining Toshiba, Yuki Yamada has been involved in the research and development of new semiconductor devices. In 2015, she began working on the development of data utilization technologies, and then became involved in new business and product development. She is now helping launch new business that leverages sound technologies.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of March 2023.
- Soundimension is a registered trademark of Toshiba Digital Solutions Corporation in Japan.
- Soundimension for the Sound Images with controlled Stereophony and Soundimension for the Sound Field Control are not currently available for purchase outside Japan.
Related articles
Running Feature: Sound with controlled distribution and stereophony broadens the horizons of audio information usage(Article list)

