


The use of sound as a means of communication has made great advances in society and in our daily lives. Thanks to these advances, we enjoy greater freedom and convenience in our handling of information. However, the audio information that surrounds us would cause some problems, such as sounds interfering with each other and listener’s fatigue caused by long-time listening. In the future, it will become an even more important viewpoint on how sounds should be heard to offer better use for the people. Toshiba has been developing technologies for use in our sound solution, Soundimension Sound with Controlled Distribution and Stereophony. Our concept is providing sound to people in desirable way. We have commercially released two Soundimension products: Soundimension for the Sound Images with controlled Stereophony and Soundimension for the Sound Field Control.* In this three-part serial article, we will show our concept, the expected applicability and the core technologies of our solution, sound images with controlled stereophony and sound field control for region separation.
In part one, we introduced the expected new ways of sound-hearing and the overview of the sound technologies that will make them possible. In part two, we introduce sound images with controlled stereophony technology, one of Toshiba’s two core sound technologies.
* This includes products scheduled for release in the fiscal year 2023.
Sound images with controlled stereophony that give a sense of sound direction even when the listener’s position changes
In part one, we explained that we had named our stereophony technologies and the solutions Sound images with controlled stereophony. We also explained that one of the features of these sound images with controlled stereophony technology is that one could feel where sound is coming from not only when using earphones or headphones, but also with audio output by two fixed-position speakers.
This feature is realized because our technology can keep auditory localization effect even if there are slight changes in the positional relation between the locations of the sound sources and the listener’s ears. In other words, even if the listener changes their posture or turns their head, the localized sound image effects would be kept.
In this article, we would focus on the technology of sound images with controlled stereophony using a simple environment consisting of just two speakers, instead of a large number of speakers.
Creating a sense of a sound’s direction requires the system to reproduce the differences between the sound that reaches the listener’s right ear and that to the left ear, when a sound comes from a certain direction. There are various methods for reproducing that difference, the most typical way is using the head-related transfer function (HRTF)*1 to calculate the absolute sound pressures at the listener’s left and right ears and then designing an FIR filter*2.
*1 Head-related transfer function (HRTF): The physical properties of the incident sound wave that reaches a person’s ears from a sound source change as the result of the interaction with the person’s head and the area around it -- that is, everything from their earlobes to their shoulders (the transmission route). The head-related transfer function (HRTF) expresses these changes as properties of the transmission route.
*2 FIR filter: The FIR filter is a type of digital filter. Digital filters are used to convert the time domain into the frequency domain. Digital filters whose impulse response (one of their response properties) is of finite duration and settles to zero after a finite number of samples, is called a finite impulse response (FIR).
If the positional relationship between the speakers and the listener’s ears does not change, such as when using headphones or earphones, this method can generally be used to produce auditory localization. This is because the only sound that reaches the right ear is the sound from the right speaker, and the only sound that reaches the left ear is the sound from the left speaker.
However, the sounds produced by fixed-position speakers are transmitted through space, and some of the sounds from the right speaker reach the left ear, while some of the sounds from the left speaker reach the right ear. This is called crosstalk, and to give a sense of a sound’s location, the effects of crosstalk should be considered in calculations. Crosstalk transmission routes have some differences depending on the listener’s location. If the listener moves from the position where absolute sound pressure was calculated -- for example, if the listener moves their head slightly -- this will cause a gap between the ideal values and the calculated values, and the sense of auditory localization might be lost. This is one of the reasons that listeners could not hear sound with a sense of direction with natural posture.
To solve this problem, we reproduce the difference between the sounds reaching the right and left ears by calculating complex sound pressure ratios, not by calculating absolute sound pressure. That is, we use relative ratios of the sounds that reach the left and right ears.
Specifically, for sound with specific coordinate information, we adjust parameters so that the complex sound pressure ratio of both ears at listening point N1 (PL1/PR1) is roughly equal to the complex sound pressure ratio calculated for the target using the HRTF (dL1/dR1).
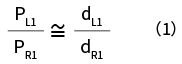
Then we also adjust the parameters for other multiple locations within the space (listening points N2, N3, ... Ni) in the same way so that the complex sound pressure ratios at these different listening points are within a certain value range. Therefore, the sound localization effect would be kept in that special area. We have developed this method as "spatial averaging method." Using the spatial averaging method makes it easy to maintain auditory localization even if values differ slightly from the complex sound pressure ratio for the target (Fig. 2).
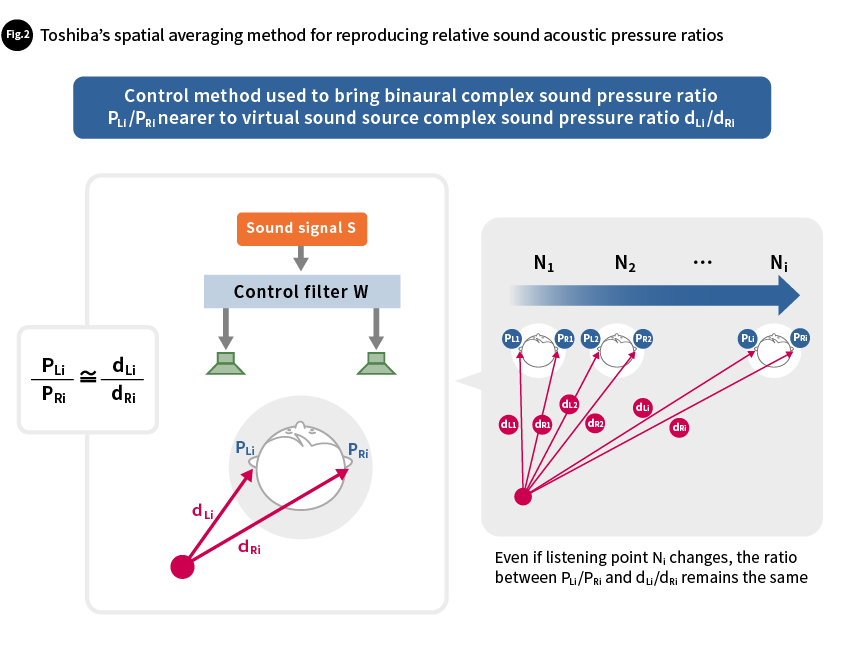
Using the spatial averaging method enables a sense of auditory localization to be maintained at multiple listening points -- that is, at different listener positions. This approach makes it possible for listeners to experience localized sound effects while maintaining a natural posture without needing to use earphones or headphones. This could reduce the limitations and burdens placed on listeners when listening to localized sound.
The latitude of feature design adjusted to the usage
The design concept of spatial averaging method using complex sound pressure ratios is simple, so it offers various other benefits beyond the robustness of providing directionality despite changes in the listener’s position.
For example, even without changing the hardware configuration, a moderate sense of sound localization could be achieved over a wide area. Conversely, the range of listening points could be narrowed to create a clear sense of sound localization within a limited area. What’s more, localization could be replicated for the listener’s right or left sides alone. Various listening designs could be created based on each purpose.
Furthermore, when we design the FIR filters, it is not necessary to take into consideration the properties of individual speaker hardware, due to the spatial averaging method.
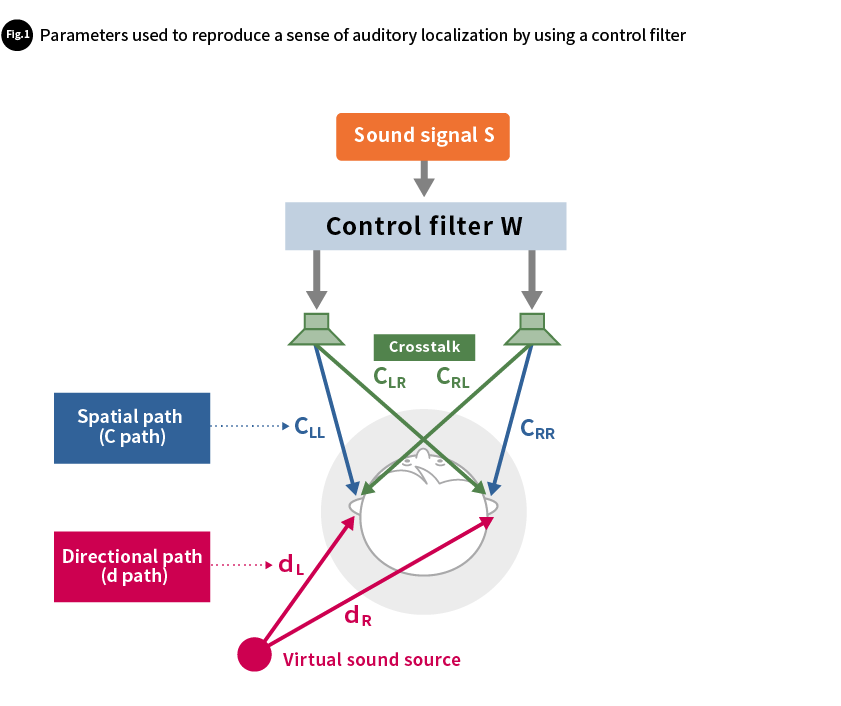
To reproduce a sense of directionality at the ears of a listener located some distance from the speakers issuing the sound, the spatial paths (C paths) of the speaker and the directional paths (d paths) of the sonic image must be calculated (see Figure 1). The C path is expressed as the product of spatial property F and speaker property G.

When designing a filter using the spatial averaging method, the relationship between the control filter W, the left and right complex sound pressure ratio (P=PL/PR), and C for an acoustic signal S is as shown in Formula (3). Here, d presents the previously mentioned directional path, and the four subscripts present the four spatial paths (LL: left speaker to left ear, LR: left speaker to right ear, RL: right speaker to left ear, and RR: right speaker to right ear).

When we calculate W using this formula, the crosstalk values WLR and WRL of control filter W, which includes speaker property G, are as indicated below. Here, the number of spatial averaging number (N) is set to 1.


When using the inverse filtering method that calculates the absolute sound pressure, speaker property G will remain in the crosstalk value, so speaker property information is necessary to calculate localized sounds. However, with our spatial averaging method, as you can see, G only remains in the formula W, as the form of the ratio of GR to GL. In general, the left and right speaker properties are designed such that GR/GL=1, so with the spatial averaging approach, the speaker property factor can be eliminated from control filter W.
With this design concept, it is not necessary to take spatial properties, including speaker properties, into consideration. In other words, filters can be designed using the parameters as the distance between two individual speakers, which are not reliant on each speaker property. This results in a great deal of freedom in the sense that it enables the same designs to be applied to various usage environments, such as computers, tablets, and televisions.
Natural sound feeling
We have explained how acoustic processing is used to create sounds with a sense of direction, but it should be undesirable that the process also causes obvious change of the original sound in volume and quality at the same time.
That is why we focused on the methods for generating sound that produce fewer side effects. We added the directional d path to the FIR filter of binaural signals*3 which cause fewer changes in experienced sound quality, then performed spatial averaging on crosstalk terms. That was how our monaural filter that suppresses changes in audio quality with respect to arbitrary angular changes was designed.
*3 Binaural signal: "Binaural" means "both ears," and binaural signals are signals created by the recording of the sounds that reach both of a person’s eardrums.
By applying this above with spatial averaging method which is the foundation of our technology, we developed Soundimension Sound with Controlled Distribution and Stereophony, which generates directional sound that provides a more natural listening experience.
The future vision of sound images with controlled stereophony
With our sound processing, we are aiming to realize the world where easy to hear, easy to understand, pleasant sound can be listened to naturally, without effort. To achieve this, we are considering how to expand effective areas and realize three-dimensional localization control in addition to the functions we already provide for giving sound a sense of direction.
Our Sound images with controlled stereophony are more robust than the localized sound created using absolute sound pressure methods, in the viewpoint of hearing position changing, but the degree of auditory localization falls if listeners move far from the sweet spot. If it were possible to expand the range over which the effects of auditory localization could be enjoyed, the directional sound would be effective everywhere between two speakers. This would decrease restrictions on usage situations, such as the positions and postures of listeners. For example, people in the same room could feel the same sense of directionality and presence of the sounds using the same speakers.
Furthermore, control of the horizontal localization of sounds has already been realized, but it is known that the control of vertical sound localization is more technologically challenging. More natural "sound arrangement" could be achieved if it would be possible to perform three-dimensional direction control, including vertical sound localization, through fixed-position speakers located at a distance from the listener’s ears, not just through headphones or earphones. We think that one of the keys of accomplishing this lies in the acoustic effects of the ear canal, so we are currently developing technologies.
Continuing to enhance the robustness and freedom necessary for listeners to be able to effortlessly enjoy sound localization, the combination of sound images with controlled stereophony technologies related to output, sensing technologies for acquiring input, and state analysis technologies that link them, would realize natural sound output that is optimized for the states of listeners.
This has the potential to make it possible to use audio information in new ways, and for a wider range of applications, including situations in which listeners are not using earphones or headphones. For example, the voice of online classes or meetings could be heard clearer and easier to understand.
It could also enable several people to share a more natural sense of experiencing the same "space" in usage situations such as virtual reality-based telecommunications, remote experiences, and the metaverse. Providing situation-adjusted sounds, voice announcements, and information also could be possible. This could be done even in places in which the locations of listeners are not strictly fixed, such as in offices, elevators, near signs, and other building and facility infrastructure, or in bathrooms, washrooms, kitchens, entryways, television viewing areas, and other housing environment. Even with the information devices with speakers inside, like smartphones and tablets, users could enjoy listening to directional sounds content while in a free, relaxed posture.
Toshiba will continue exploring more applications of Soundimension and developing the technologies to offer new sound experiences.
In part one, we provided an overview of our sound technologies. Here, in part two, we have explained one of Toshiba’s two core sound technologies, sound images with controlled stereophony technology. In the third article, final part of this series, we will explain Toshiba’s other core sound technology, sound field control for region separation technology.
Up next: (Part 3) Sound field control for region separation technology

Yuki Yamada
Expert
New Business Development and Marketing Dept.
ICT Solutions Div.
Toshiba Digital Solutions Corporation
Since joining Toshiba, Yuki Yamada has been involved in the research and development of new semiconductor devices. In 2015, she began working on the development of data utilization technologies, and then became involved in new business and product development. She is now helping launch new business that leverages sound technologies.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of November 2022.
- Soundimension is a registered trademark of Toshiba Digital Solutions Corporation in Japan.
- Soundimension for the Sound Images with controlled Stereophony and Soundimension for the Sound Field Control are not currently available for purchase outside Japan.
Related articles
Running Feature: Sound with controlled distribution and stereophony broadens the horizons of audio information usage(Article list)

