
![]()


In the past, it was not necessary to store high frequency sensor data that could be used to obtain real-time control of site equipment and processes. However, as IoT becomes more prevalent today, more advanced control and better predictions could be attained by retaining these data. Digital representation of site machinery and processes could be simulated more accurately by collecting the sensor data into Digital Twins. To realize this, the backend database needs to be fast, scalable and very efficient in storing enormous amount of time-series data. Based on the open design concept of SPINEX (Toshiba's IoT architecture), we proudly introduce GridDB - Toshiba's in-house database for IoT data. Toshiba has been working with large amounts of time-series data since the beginning of the IoT era. GridDB is the culmination of many years of expertise and innovations.
The challenge with conventional databases when handling time-series data
IoT systems collect, store and process time-series sensor data for visualization and control purposes. Databases play major roles in the platforms of these systems. However, in the world of IoT systems, as it is impossible to predict the growth of data in the future and a faster response of the analysis results become mandatory, the requirements for database have evolved to a point where conventional technologies become obsolete and are not capable of handling new problems.
First, with regard to data collection, it is difficult to accumulate a large amount of data regularly generated every milliseconds. Numerous sensors in the system collect and transmit various information, such as temperature, brightness, voltage, and image. Furthermore, data is gathered from every installed sensor 24/7 regularly in the intervals of minutes, seconds, or even milliseconds. So databases must have high-speed processing capabilities, ability to write large amounts of data, and the reliability to record this constant inflow of data non-stop.
With regard to storage, databases face a major challenge in storing massive amounts of data which is growing over time. These databases must therefore have exceptional scalability that can flexibly handle tremendous amount of data. The range and structure of stored data accumulated every milliseconds, monthly or yearly are also complicated. When building databases, it is extremely important to ensure reliable data integrity in order to store diverse data without gaps or inconsistencies.
Turning to analysis, it is essential that databases offer high level of performance, and are capable of searching in real-time immediately after the data is written to the database. IoT systems immediately begin analysis of the data stored in time-series form, using this analysis to rapidly detect irregularities and implement preventative maintenance. This is only possible with databases with sufficient performance capabilities.
Click here to move to the top of this page.
Toshiba's GridDB, going beyond the limits of conventional databases

Selecting the right database is the key to creating an effective IoT system. Until today, company systems have used RDB (relational databases) in their platforms. However, RDBs store data in two-dimensional form (tables), and combine multiple tables. While they excel at ensuring data integrity, they are insufficiently able to process large amounts of data or handle frequent data processing demands. IoT systems can use NoSQL databases, which excel at high-speed reading and writing that are needed when handling time-series data. However, they do not offer the same reliability as commercial RDBs.
Toshiba's GridDB goes beyond these limits of conventional databases. It offers a database with high performance and high scalability features that meets all of the requirements of IoT systems. GridDB was developed as an answer to the lack of databases with suitable data processing capability and data growth management. Toshiba's experience and innovations in this field include successful implementations in improving the productivity of factory's production lines, monitoring and visualization of industrial equipment, and ensuring stable operation of systems in fields such as power, transportation and logistics, and social infrastructure. We began offering GridDB in 2013 as a completely new type of NoSQL database with the advantages of RDB. Since then, it has been deployed in a wide range of industrial and social implementation, building up an extensive track record of use in time-series data processing for critical systems such as social infrastructure systems.
GridDB provides robust support of high accuracy simulations and rapid control through digital twins, one of the features of Toshiba's SPINEX IoT architecture. GridDB's four key features are: “IoT-oriented data model,” “High Performance,” “High Scalability,” and “High Reliability and Availability” (Fig. 1).
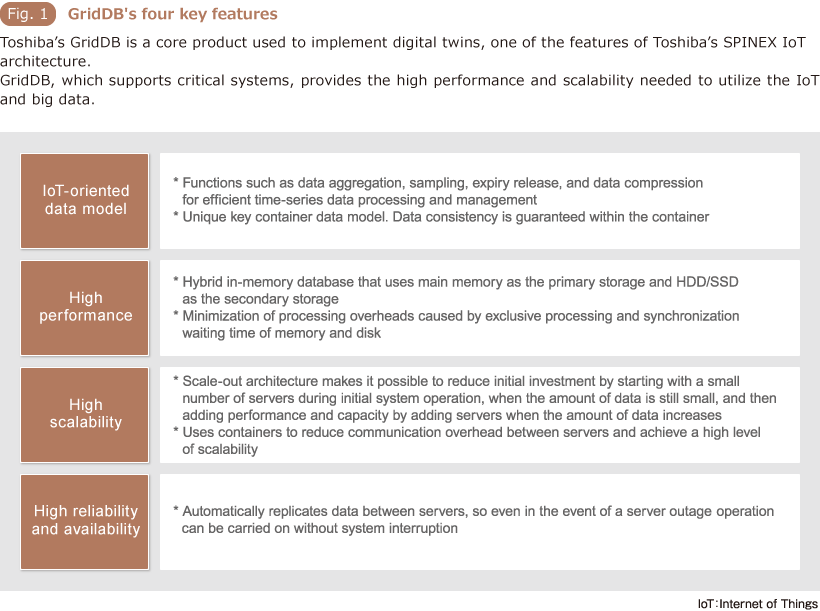
- 1. IoT-oriented data model
- One of the notable features of GridDB is Toshiba's proprietary and IoT-oriented “key container” data model, which is designed to accommodate the characteristics of time-series data. Data generated by numerous sensors is stored in each “key”. Timestamps and values from individual sensors on corresponding devices are managed in units called “containers,” and database consistency is guaranteed on the container level. It also offers numerous functions for handling time-series data effectively, such as data compression functions that dramatically reduce memory usage and expiry release functions which automatically delete unnecessary data by specifying its retention periods.
- 2. High performance
- Problems in conventional databases such as I/O bottleneck, which prevent them from being able to take full advantage of the CPU's capabilities are resolved in GridDB by utilizing in-memory processing and keeping the necessary data as much as possible in memory instead of disk. The overheads produced by exclusive processing and synchronization waiting time of memory and disk are minimized. This makes it possible to achieve high-speed data processing, leveraging maximal hardware performance while handling petabyte-level big data.
- 3. High scalability, 4. High reliability and availability
- Database processing capabilities can be improved in two ways: scale up, improving the capabilities of individual servers; and scale out, increasing the number of servers. Not only that the former approach requires temporarily stopping the system, it is also expensive. The latter results in an increase in traffic between servers, which in itself produces new performance issues. GridDB adopts the scale out approach. Key containers reduce traffic between servers and provide exceptional scalability without degradation in database processing performance. GridDB offers a high level of reliability and availability by automatically replicating data between servers, so even in the event of a server outage, operation can be carried on without system interruption.
Click here to move to the top of this page.
High performance verified through benchmark testing and use in actual power infrastructure
There is some interesting data that backs up GridDB's performance and scalability excellence.
The YCSB, database performance verification tool, was used to compare the performance of GridDB with
that of Cassandra, a NoSQL database famous for its high performance (Fig. 2).
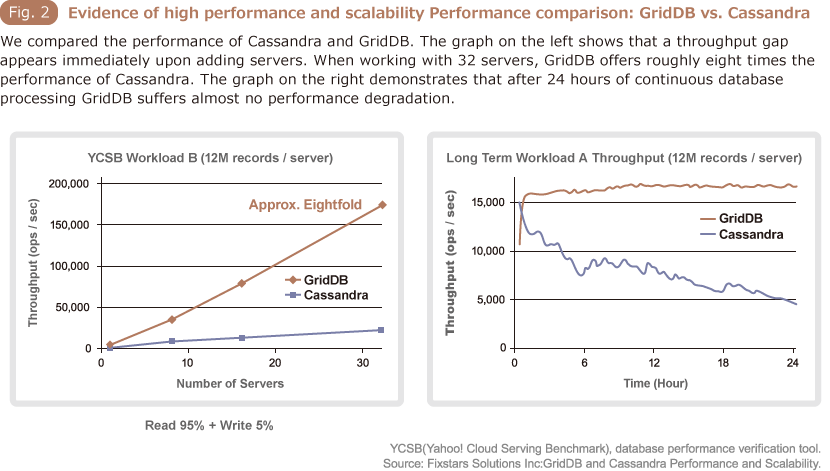
In the graph on the left hand side, the vertical axis represents throughput and the horizontal axis
represents the number of servers. GridDB's throughput increases almost linearly with respect to the
number of servers. Differences in the performance offered by the two databases become evident
immediately upon adding servers. With 32 servers GridDB demonstrated roughly eight times the
performance of Cassandra.
The graph on the right compares performance after 24 hours of database processing. Cassandra's final
throughput is only 50% of its total throughput during the first hour, whereas GridDB's throughput
remain stable with almost no performance degradation.
This overwhelming performance has been the key differentiator especially when GridDB is used in systems which require high levels of performance and quality, such as a wheeling system* for a power company. Following the deregulation of electrical power, GridDB-based system is capable of processing large amounts of data sent every 30 minutes from millions of smart meters in less than 1/35 the time it took with a conventional RDB-based system. GridDB continues to provide stable support for critical systems where data gaps and loss of data are unacceptable such as in the wheeling bill calculation case.
* Wheeling system: These systems are used to calculate and provide usage information of the power distribution network, and usage billing amounts, based on data obtained from power meters, for use in power sales by electrical power retailers. Unlike ordinary time-series data, these systems use time-series data in which gap filling and correction is performed at a later time.
* The power company's case example is introduced in #04.
In 2016, GridDB was released as an open source software. We are actively promoting efforts to create
new value through community-led technical improvement and mutual coordination with open source
software such as Apache Hadoop. (Click
here ![]() (GitHub, Inc.) for the dedicated open source community)
(GitHub, Inc.) for the dedicated open source community)
GridDB was born through the culmination of Toshiba's experience and expertise, and its performance has been refined and evolved in order to handle explosive time-series data growth. We are confident that full-fledged growth of IoT-led digital transformation is just ramping up.
* For application and services developers using GridDB, please visit GridDB Developers ![]() technical
information site.
technical
information site.
* The corporate names, organization names, job titles and other names and titles appearing in this article are those as of August 2017.






 Following links will open in a new window
Following links will open in a new window