読み取り技術
弊社は、AI OCR開発においても複数の特許を保有し、サービスに適用しています。
【特許取得済】
特許第6813704号 特許第6798055号 特許第6334209号 特許第6076773号
文字位置推定・重複読み対応技術
<人間にとって理解しにくい読み取り誤りの発生>
文字を読み取る際、文字の一部を重複して読み取ったり、逆に一部を読み取らなかったりする読み取り誤りが起こるケースがあります。
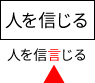
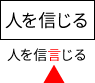
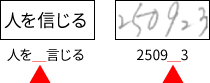
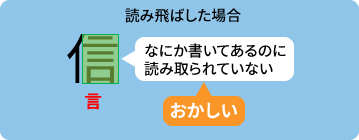
文字の一部が2回読み取られる例
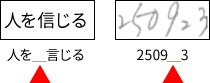
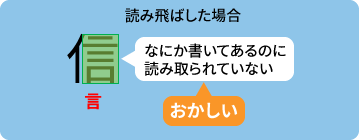
文字(の一部)が消えてしまう例
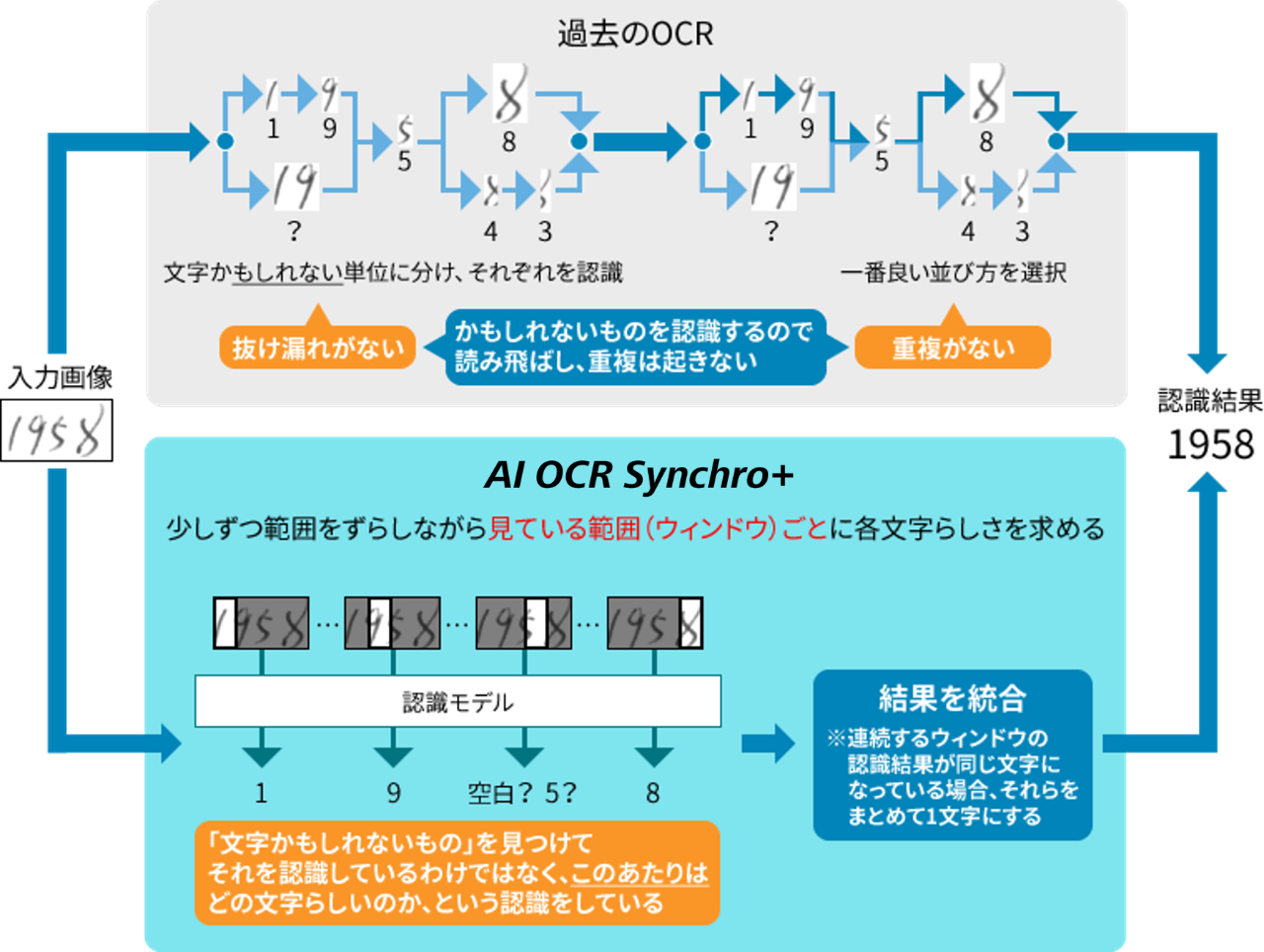
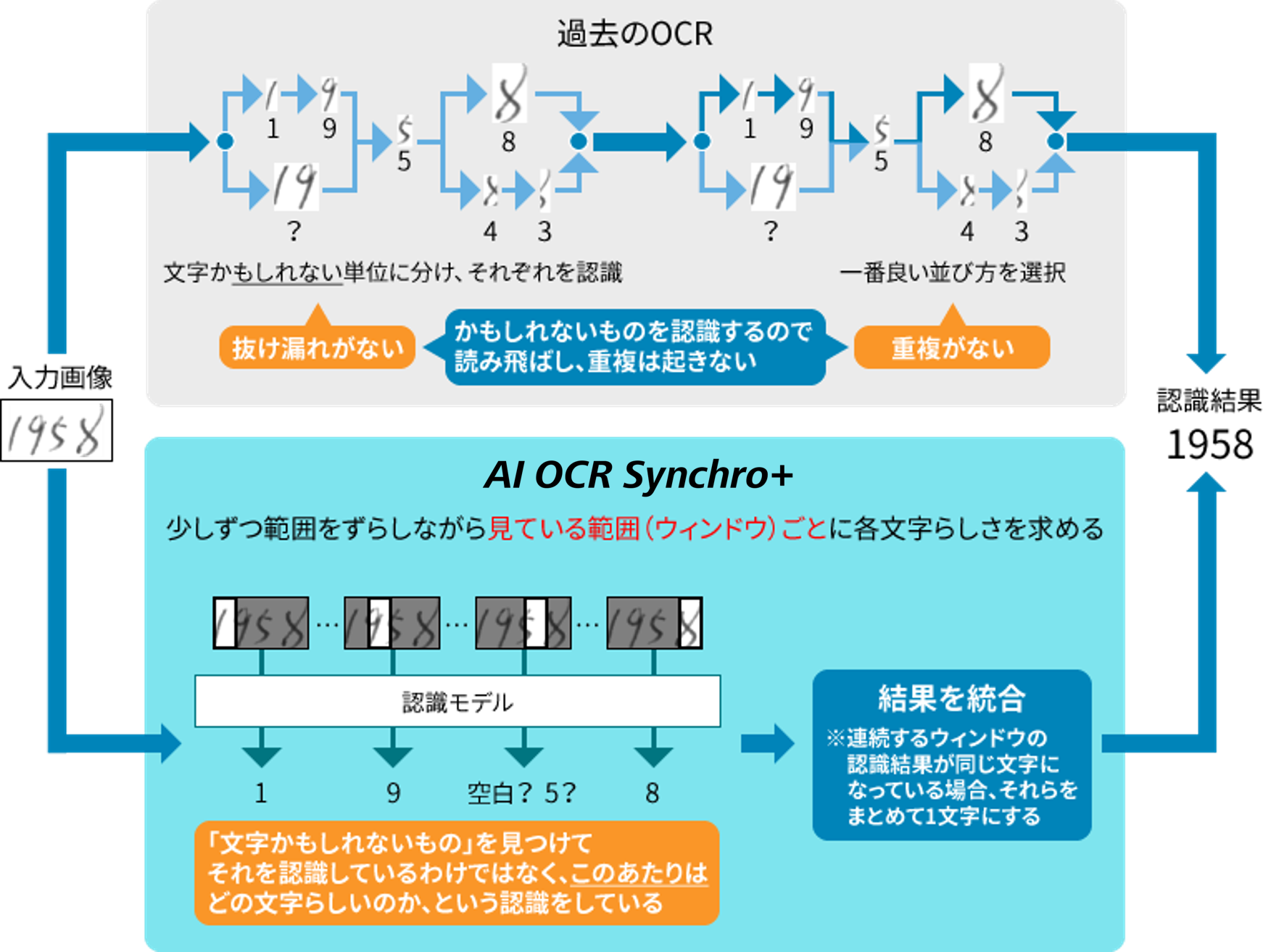
<従来OCRとAI OCR Synchro+の読み取りメカニズム>
AI OCR Synchro+では、読み取り範囲を少しずつずらしながら読み取ることで、乱雑に書かれた「接触文字」や文字がつながった「つづけ字」など、高い精度で認識できるようになりましたが、重複読み取りや一部を読み取らない場合に対応するため、文字位置推定・重複読み対応技術を開発しました。
<人間にとって理解しにくい読み取りはなぜ起きるのか>
ウィンドウ(文字を読み取る範囲)の幅は決まっていますが、ウィンドウ内だけでなく、周辺にある文字列も考慮して読取結果を出すため、重複や読み飛ばし/別の文字に置き換えての読み取りが発生します。
隣のウィンドウで、別の文字らしさが高い → 重複読み取り
どのウィンドウでも、その文字らしさが低い → 読み飛ばし/別の文字で読み取り
文字の一部が2回読み取られる例
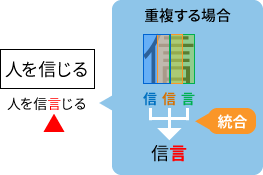
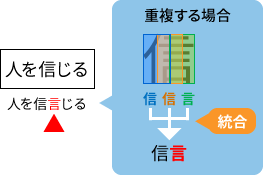
本来緑のウィンドウでも周辺を考慮して「信」という結果を返してほしいが、うまくいかずに「言」になってしまった。
文字の一部が消えてしまう例
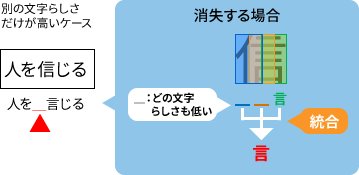
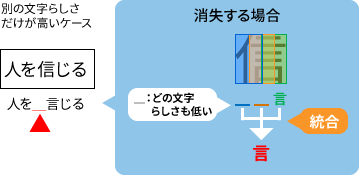
どのウィンドウからも「信」という結果が返ってこなかった。この例では文字の一部である「言」の部分だけを認識してしまっている。
※人偏の書き方がよくない(極端に傾いている、かすれているなど)と、こういう事例が発生しやすい。
<理解しにくい読み取りを防ぐ>
文字位置を推定しながら読み取り、重複読みや読み飛ばし現象を抑制することで、精度高い認識結果を得ることができます。


「文字かもしれない単位に分ける」のは困難


読み取りと並行して文字の位置も得る手法を開発
これに基づき重複読み・読み飛ばしを改善
※特許第6813704号、ほか関連特許出願中
文字位置推定の結果


詳細は国際学会でも発表
Ryohei Tanaka et al. “Text-conditioned Character Segmentation for CTC-based Text Recognition”
ICDAR2021, September 5-10, 2021, Lausanne, Switzerland
取消文字読み飛ばし・訂正文字認識技術
<間違った記入の取り消し、さらに訂正があっても意図通り認識する>
間違った記入を2重線で取り消している例


間違った記入を2重線で取り消し、さらに訂正内容を記入している例


<一般的な動作>
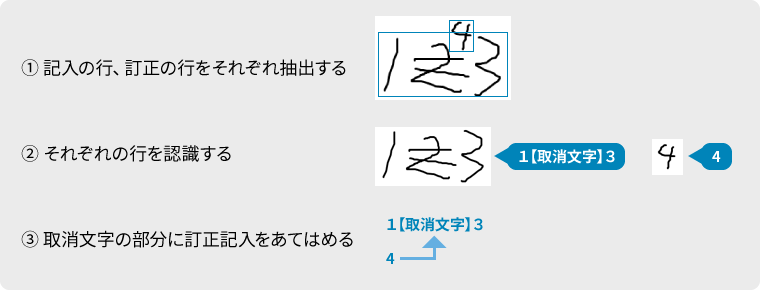
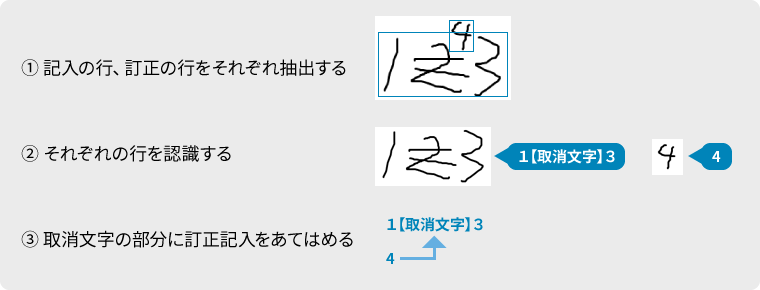
訂正記入はいろいろな書かれ方をするので、訂正の抽出や対応関係の決定が難しい
<東芝での方式>
Step1: 訂正記入も、取消と同じ行として行抽出
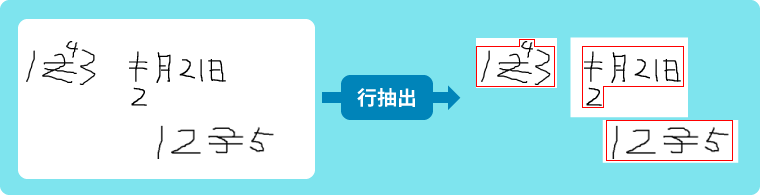
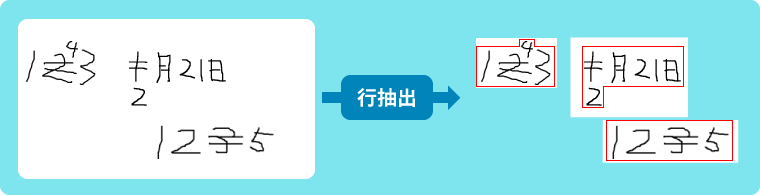
Step2: 取消、訂正記入を含む行画像をそのまま認識
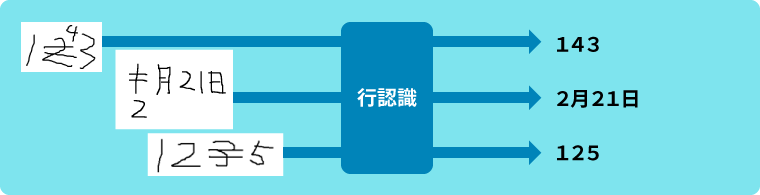
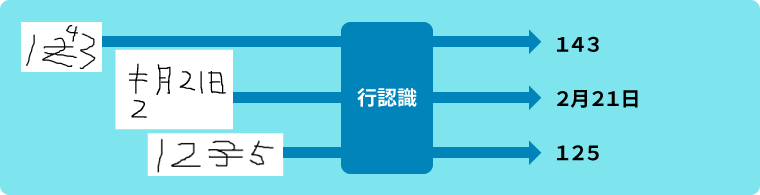
様々な取消、訂正記入サンプルを学習データとして活用することで、精度高い認識結果が得られるようになりました。
<動作イメージ>


項目フィルター対応技術
<文字認識の課題>
住所や電話番号など読み取りたい項目が近接していて、適切に読み取り範囲を指定することができず、認識精度が低下する場合がありました。
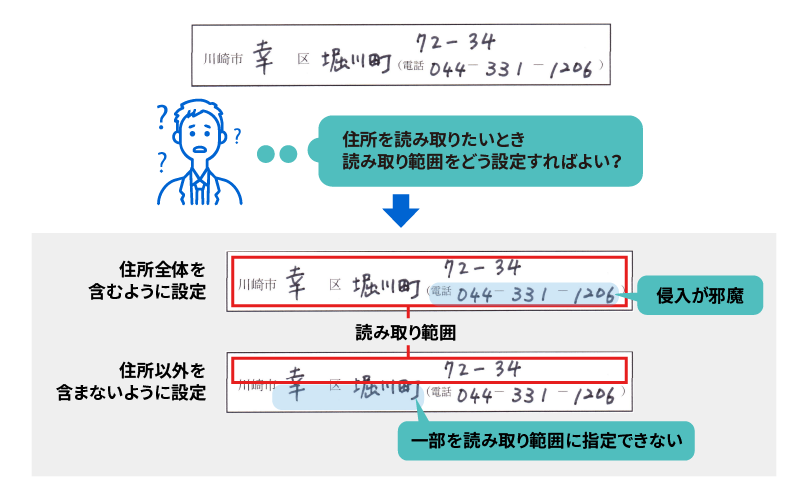
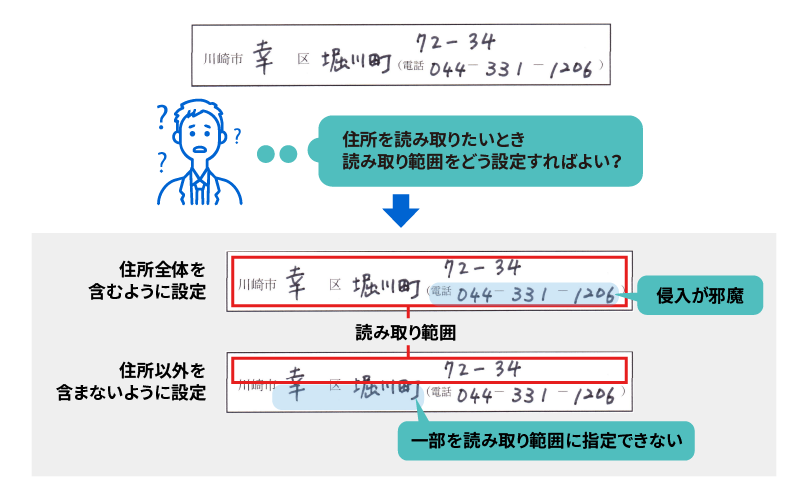
<項目フィルター機能>
読み取り範囲指定を行う際、住所、電話番号、名前など複数項目が同じ枠にあっても「住所」または「氏名」を選択すれば、選択した項目だけが読取可能です。(現時点では「住所」「氏名」に対応)
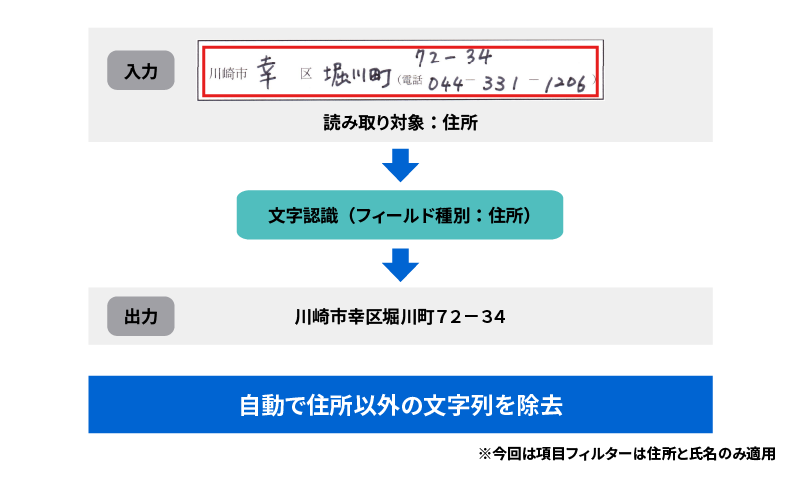
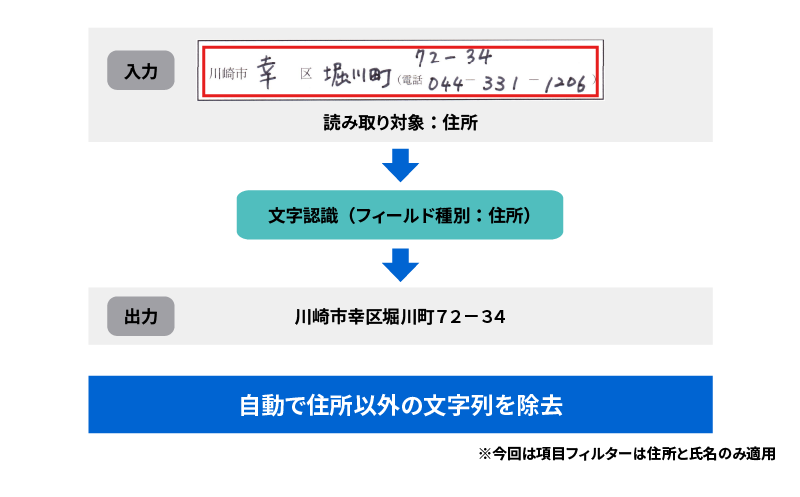
<項目フィルターによる改善例>


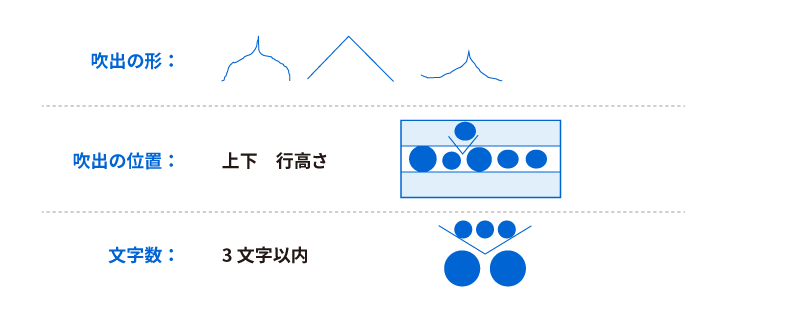
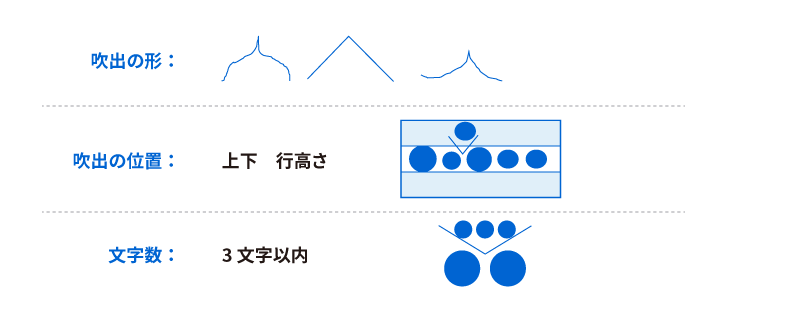
吹き出し挿入対応技術
<吹出挿入>
「取消文字読み飛ばし・訂正文字認識技術」を応用し、吹き出し挿入にも対応しました。


<吹出挿入仕様>
<認識例>
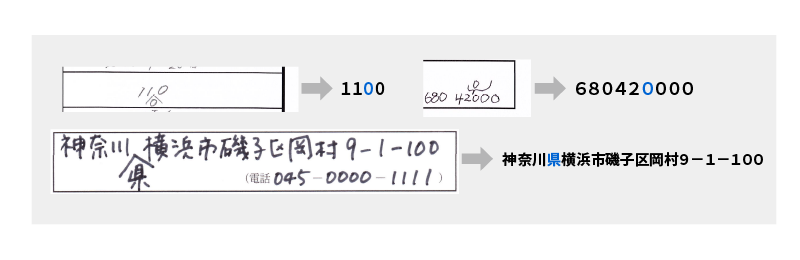
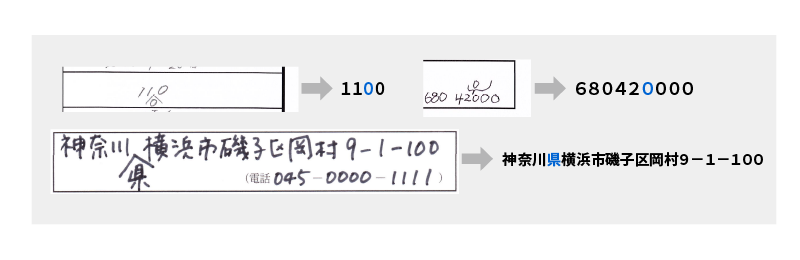
都道府県・市区町村 選択肢の行認識対応技術
<都道府県・市区町村選択肢の行認識対応>
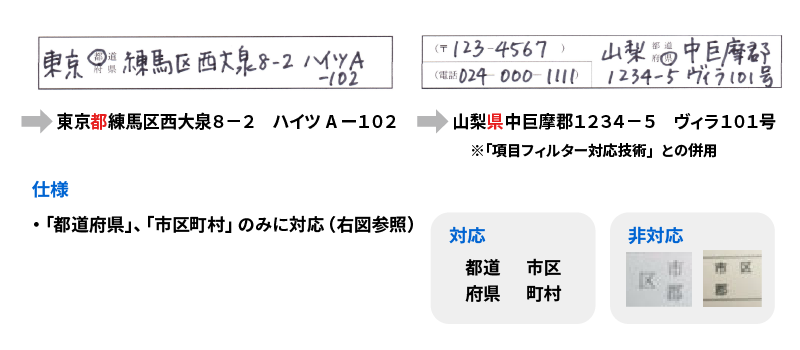
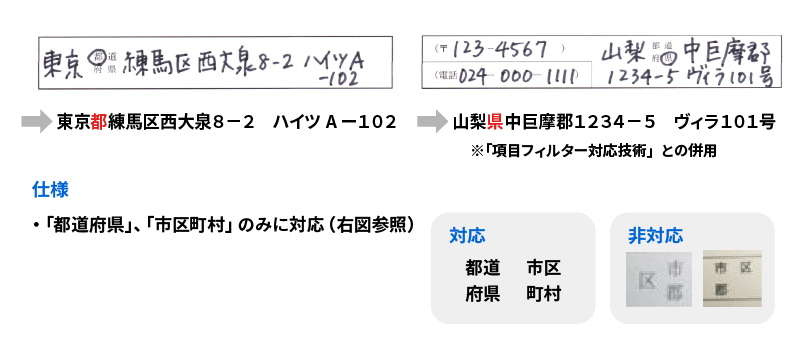
<認識例>


表解析、項目抽出技術
【 例1 】
右サンプルのように、セルの一部が結合されるなど、不規則な表の場合、従来は読み取りが困難でしたが、今回の改良で赤枠内の認識精度が向上しました。
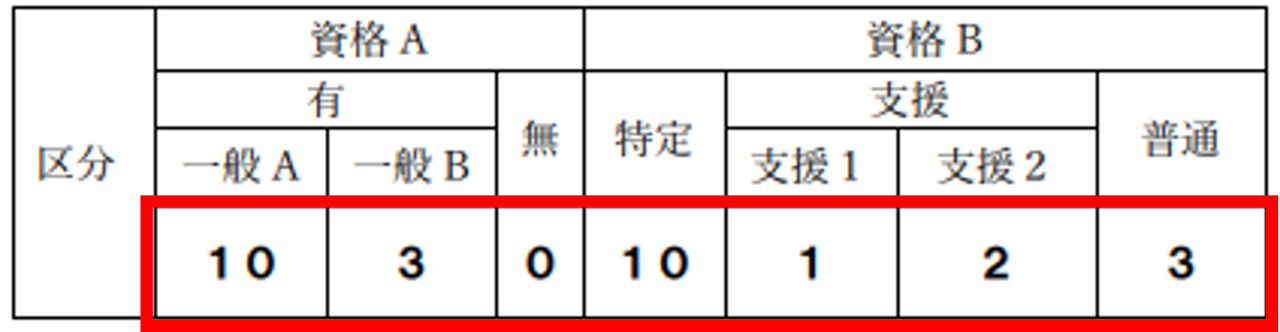
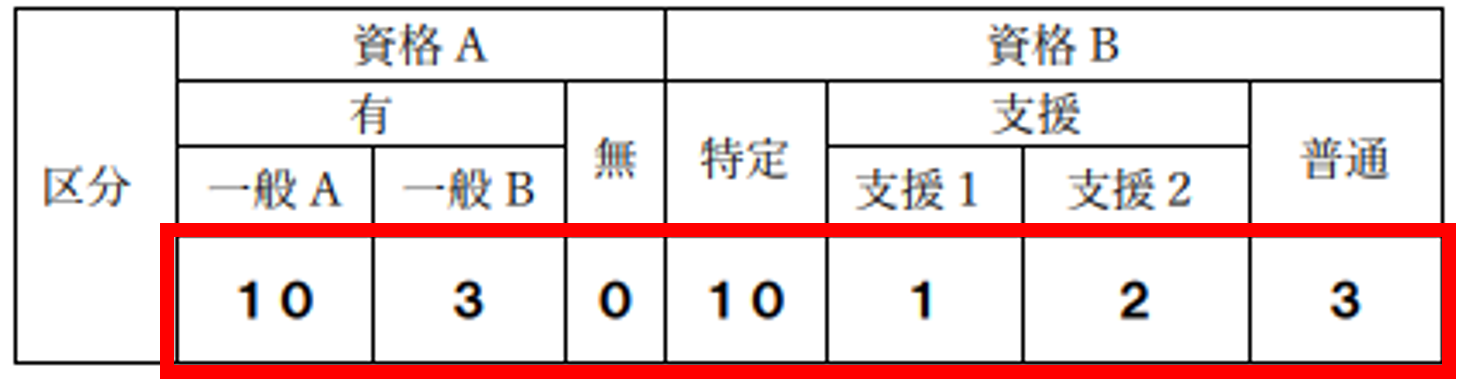
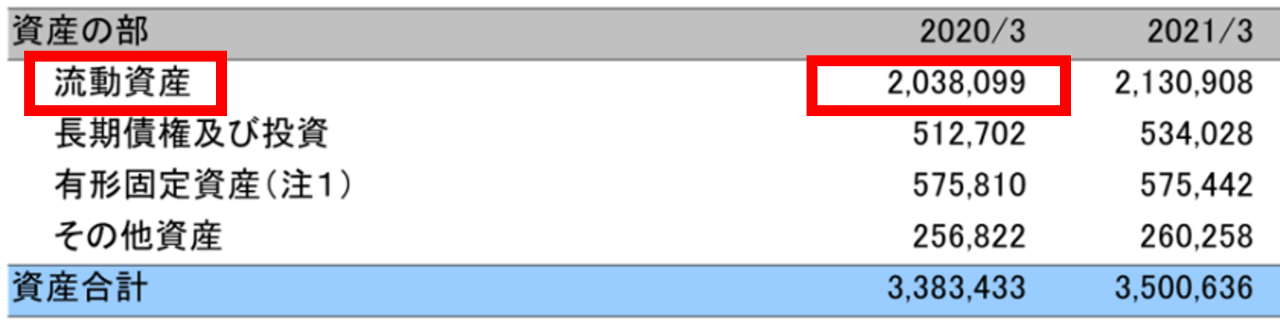
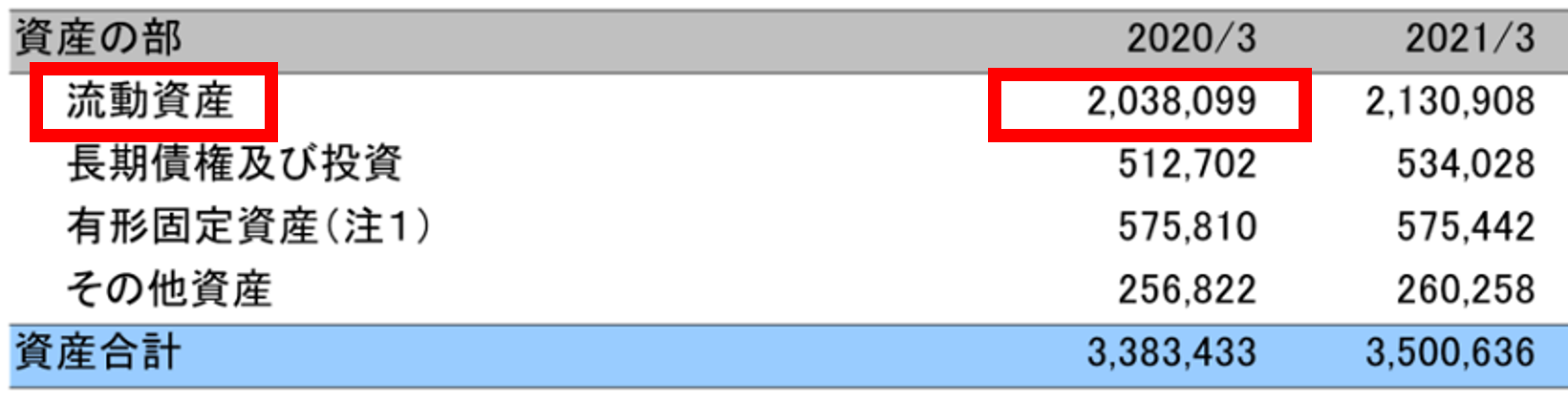
【 例2 】
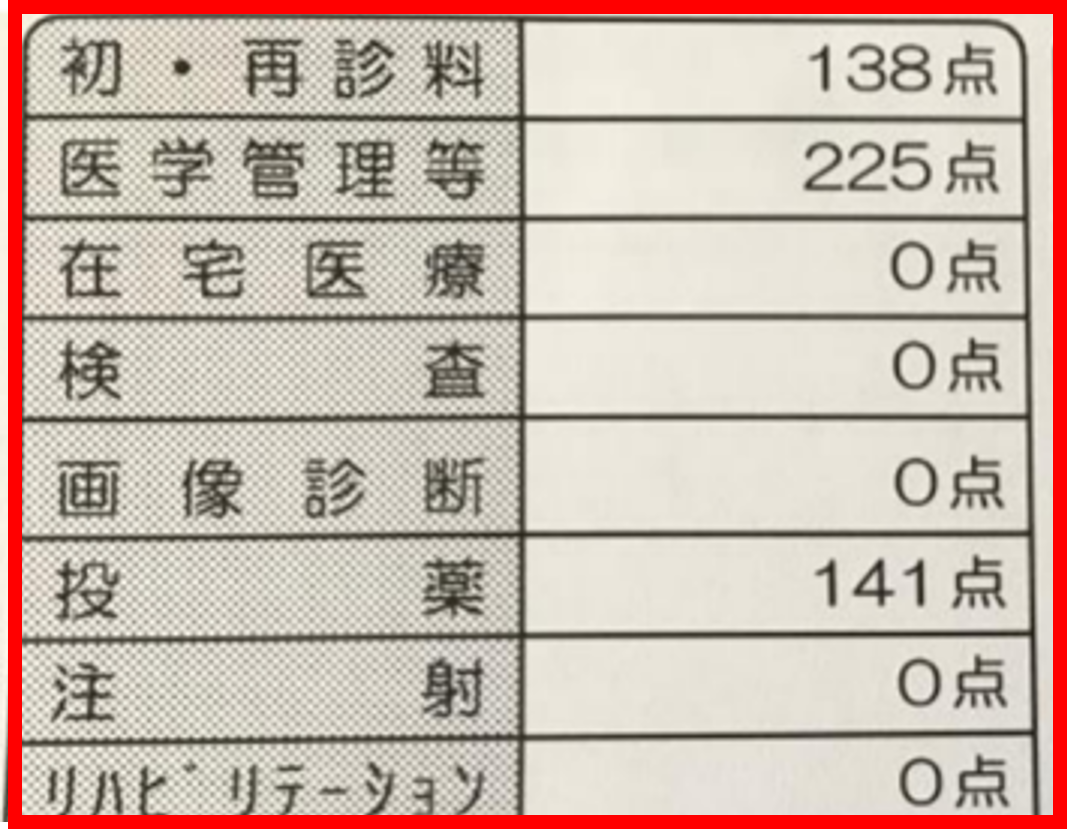
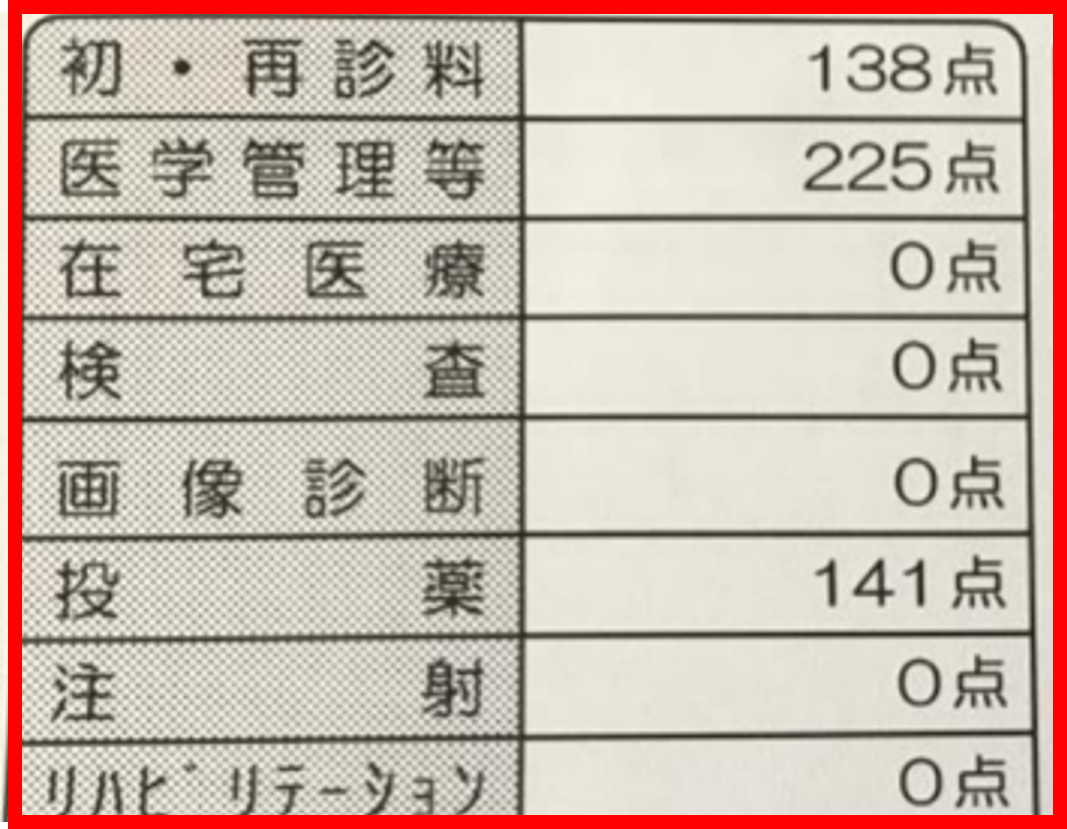
右サンプルの赤枠(流動資産、2,038,099)のように、縦横の罫線が無い・セルが結合されているなど、文字と数字の組み合わせが判別しにくい帳票の場合、従来は読み取りが困難でしたが、今回の改良で認識精度が向上しました。
【 例3 】
右サンプルの赤枠のように、文字の背景が白ではなく、網掛けや色が付いている帳票の場合、従来は一部が読み取れないなどの課題がありましたが、今回の改良で認識精度が向上しました。