


変化の激しい世の中にあって、複雑化する課題の解決に取り組む社会や企業では、量子関連の技術が注目されています。量子現象を利用した本格的な量子コンピューターの実現には時間がかかると考えられている中で、東芝では、量子現象から着想を得た量子インスパイアード最適化技術に取り組んでいます。これは、膨大な選択肢の中から最適な解を導き出す「組合せ最適化」に対応する当社独自の技術で、既存のコンピューターを使って高精度な近似解(良解)を短時間で得られる量子インスパイアード最適化ソリューション「SQBM+」として提供しています。ここでは、量子インスパイアード最適化技術について、連載でご説明します。
第1回から第4回にわたり、量子インスパイアード最適化技術の目的、概要、関連する技術の中での位置づけ、さらにはその応用について解説しました。ここからは2回に分けて、リアルタイムあるいはミッションクリティカルと形容されるシステムへの量子インスパイアード最適化技術の適用について説明します。今回は、適用にあたりキーデバイスとなるFPGA、そしてFPGAと量子インスパイアード最適化技術の組み合わせによりどのような新しいことができるのかを解説します。
量子インスパイアード最適化技術の重要な構成要素と代表的な古典コンピューター
量子インスパイアード最適化技術は、量子コンピューターの理論から演繹(えんえき)された、あるいはそこから着想を得て開発したアルゴリズムを、既存のコンピューター(古典コンピューター)に実装することで実現します。アルゴリズムとは、計算したりデータへアクセスしたりする順番を定めたものです。そのため、アルゴリズムだけではそれらの実行にかかる時間は決まりません。アルゴリズムを、どのような古典コンピューターに、どれだけ巧みに実装するかによって、実行時間は大きく変わります。量子インスパイアード最適化技術は、従来は不可能だったほどの短時間で、組合せ最適化問題を解くことを目的の1つとします。実装するアルゴリズム、そしてそれをコンピューターへ実装する方法は、量子インスパイアード最適化技術の目的を実現するために重要な2つの構成要素です。
ここで、アルゴリズムを実装する主な古典コンピューターを分類し、特徴を比較していきます。
一般の人にとってなじみのあるコンピューターの主要な構成要素といえば、パソコンにも搭載されている中央演算処理装置(Central Processing Unit:CPU)ではないでしょうか。CPUは、システム全体の制御に加えて、その時々で必要となるアプリケーションソフトウェアの実行を担当します。多くのシステムでは、CPU(メインプロセッサ)に加えて、それを補助する装置(コプロセッサ)を備えています。例えば、CPU自身で実行するよりも、ある処理を実行するにあたり入力から出力までの応答時間をより短くする(低遅延)、あるいは単位時間当たりの処理能力を高くする(高スループット)、消費電力を抑えるといった補助的な処理を担うものです。コプロセッサは、その目的からアクセラレーターとも呼ばれています。
代表的なコプロセッサには、画像処理やゲーミング、AI処理などに使われる画像処理装置(Graphics Processing Unit:GPU)、そしてシステムのボトルネックになる処理や通信、周辺機器の制御のような高い効率を求められる処理に使われる、特定用途集積回路(Application Specific Integrated Circuit:ASIC)と現場プログラム可能ゲートアレイ(Field-Programmable Gate Array:FPGA)があります。ASICとFPGAには共通する特徴が多く、ハードウェアとして製造後にアルゴリズムを書き換えできるかどうかが大きく異なる点です(図1)。
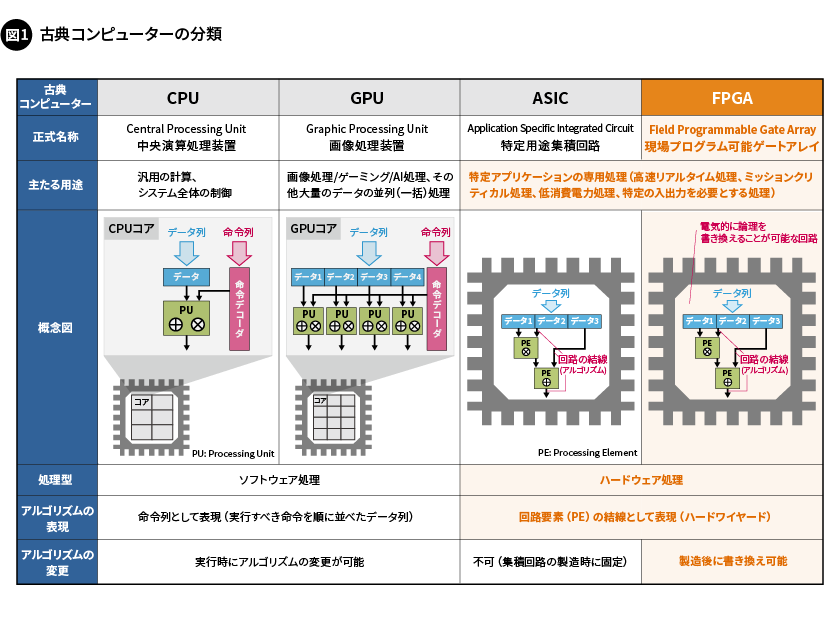
各プロセッサで異なる汎用性と処理効率
コプロセッサは、CPUよりも汎用性は低く(用途はより限定的)、処理の効率は高いという特徴を持ちます。
CPUはコア(処理を行う中核となる部分)1つあたり、強力な処理ユニット(Processing Unit:PU)を1つ持ちます。PUは、加算をはじめ、乗算、シフト、データのロードやストアなどの基本処理と、より高度な拡張処理を実行することが可能で、その中からどれか1つの処理を、クロックサイクル(デジタル回路の単位処理時間)ごとに実行します。実行する処理は、命令デコーダによって指示され、このときのアルゴリズムは、実行するべき命令を順に並べたデータ列(命令列)で表現されます。
またGPUは、膨大なデータに対して比較的単純な処理を効率よく実行することが得意です。GPUのコアは、多数の単純なPUを備え、それらのPUが1つの命令デコーダを共有します。このハードウェア構成が、複数のデータに対して同時に同じ処理を効率よく実行することを可能とします。
ここまでに説明したCPUとGPUはソフトウェア処理です。そして、ここから説明するASICとFPGAはハードウェア処理であるという点に大きな違いがあります。ソフトウェア処理において、アルゴリズムは命令列で表現されます。一方、ハードウェア処理におけるアルゴリズムは、回路要素の結線(アルゴリズムの回路化、ハードワイヤードと呼ばれる)として表現されます。
例えば、ASICおよびFPGAにおいて、データ1とデータ2を乗算し、その結果とデータ3を加算するときのアルゴリズムを考えてみます。図1の概要図に示すように、このアルゴリズムは、データ1およびデータ2の出力と乗算器(Processing Element:PE)の入力との結線、そしてその乗算器の出力およびデータ3の出力と加算器(PE)の入力との結線で表現できます。あるアルゴリズムを表現する回路は、専用回路もしくは専用ハードウェアと呼ばれます。データ1からデータ3までを表すデジタル信号が、図1の専用ハードウェアを通過すると、そのアルゴリズムの結果のデータがハードウェア処理によって得られるというわけです。
一般にハードウェア処理は、ソフトウェア処理よりも高い処理効率を実現します。例えば、同時に実行できる乗算が1000か所あるアルゴリズムで考えてみます。ハードウェア処理の場合は、1000個の乗算器(PE)を用意し、すべての乗算を1クロックの時間で完了できます。一方、1つのPUを持つCPU(ソフトウェア処理)で同じアルゴリズムを実行する場合には、少なくとも1000クロックの時間が必要となります。
FPGAの仕組みとASICとの用途の違い
ASICとFPGAは、いずれもハードウェアの設計者がアルゴリズムごとに設計した専用ハードウェアを実現する半導体集積回路です。ASICは、半導体の製造工場において専用ハードウェアそのものを物理的に製造したもので、製造後にアルゴリズムを書き換えることはできません。一方のFPGAは、製造後に「電気的に書き換えが可能」な情報処理回路です(図2)。
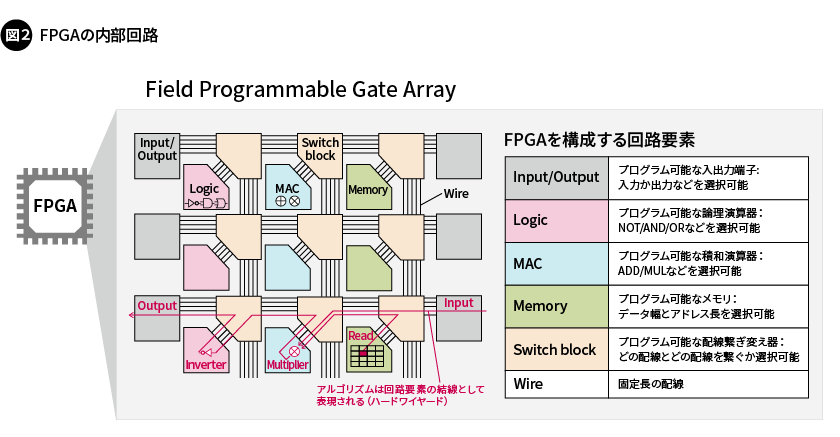
FPGAの内部には、電気的に結線を切り替えることで機能を変更できる回路要素(プログラマブル回路要素)が、規則正しく並んでいます。プログラマブル回路要素には、入出力端子や論理演算器、積和演算器、メモリ、配線繋(つな)ぎ変え器などがあり、これらを使って任意の専用ハードウェアを実現することが可能です。専用ハードウェアの例を、図2に赤色で示しました。この専用ハードウェアは、ある入力端子からのデータとあるメモリに格納されたデータを乗算(MUL演算)し、その結果を反転(NOT演算)して、ある端子から出力するものです。
FPGAは、製造後に書き換えることが可能なため、ASICと比較して、アルゴリズムの決定から製品の展開までの開発期間が短く、加えてチップ自体の開発費が不要であるというメリットがある反面、まったく同じハードウェア機能を実現するときはより大きなチップサイズを必要とします(チップ単価は高い)。これは、FPGAには、書き換え可能な回路とするために複雑な回路構造を備える必要があり、面積が大きくなる特性があるからです。これらの特徴から、高い処理効率が求められる製品であって、大量生産型のものにはASICが、短い開発期間を要求されるもの、もしくは、少量生産型のものにはFPGAが採用される傾向にあります。
処理効率に優れたFPGA実装による量子インスパイアード最適化技術
量子インスパイアードアルゴリズムの1つである「シミュレーテッド分岐アルゴリズム(Simulated bifurcation Algorithm:SBアルゴリズム)」は、東芝の量子コンピューターである「量子分岐マシン」から演繹されたものです。新規のメカニズムで膨大な選択肢の中から良解を探し出せることを、第1回と第2回の記事で説明しました。古典コンピューターに実装する観点から見たSBアルゴリズムの特長は、その並列度(同じクロックで計算できる演算の数)の高さにあります。
今回紹介したコプロセッサは、いずれも並列処理によってCPUよりも高い処理効率を実現しますが、あらゆるアルゴリズムを高効率に実行できるわけではありません。アルゴリズムの並列度が高いことに加えて、アルゴリズムの構造(データ依存性)と古典コンピューターのアーキテクチャーの親和性が高い必要があります。SBアルゴリズムのもう1つの特長は、GPUのアーキテクチャーだけでなく、FPGAのアーキテクチャーとも高い親和性を示すところにあります。
FPGAにSBアルゴリズムを実装した最初の例が、2019年に発表された論文(https://doi.org/10.1126/sciadv.aav2372)に掲載されました。この例では、SBアルゴリズムの並列度を最大限に引き出す超並列の専用ハードウェアが設計され、それが1つのFPGAに実装されています。8192個の積和演算器が搭載され、さらにその膨大な数の積和演算器はクロックサイクルのうち92%で有効な計算を実施します。これは、空間的に高い並列性をもつハードウェアが、時間的に高い活性度を持つ(アイドリング時間が少ない)ことを意味します。
実装の結果、計算の困難性が証明されている学術ベンチマーク問題(組合せ最適化問題)において、従来の古典的なアルゴリズムであるシミュレーテッドアニーリング法(焼きなまし法、Simulated Annealing:SA)よりも392倍高速でかつ、同等水準の良解を得ること(同等のイジングエネルギーに相当する解を得ること)に成功しています(図3)。
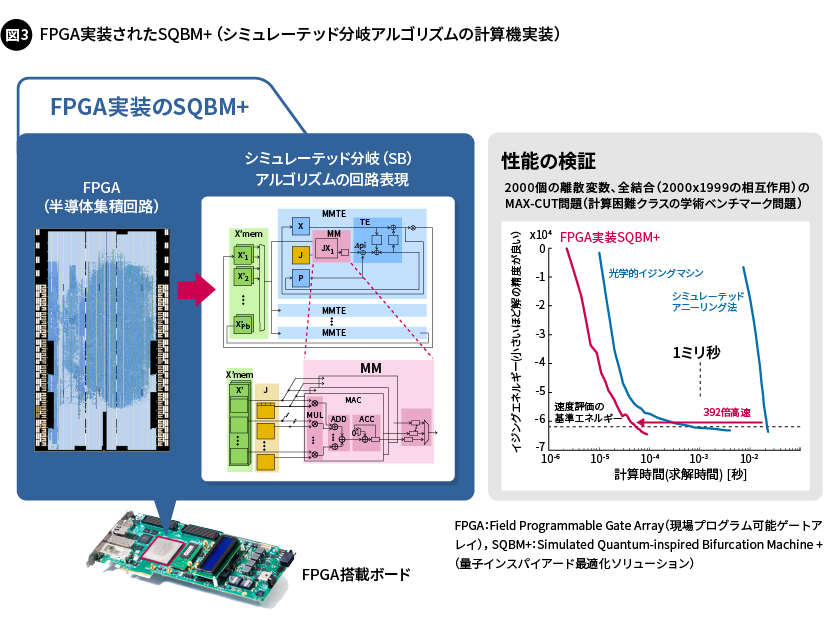
量子インスパイアード最適化技術とFPGAの組み合わせで高まる提供価値
量子インスパイアードアルゴリズムである「SBアルゴリズム」は、GPUやFPGAに高効率に実装することが可能です。ここでいう高効率な実装とは、古典コンピューターが持つ多数の回路リソースが無駄なく使われ、またその回路リソースが時間軸においても隙間なく有効な計算を実行する状態を指します。
GPUおよびFPGAに実装したSBアルゴリズムは両方とも高い処理効率を示しますが、GPUとFPGAの計算機アーキテクチャーの違いを反映して、異なる特徴を示します(図4)。
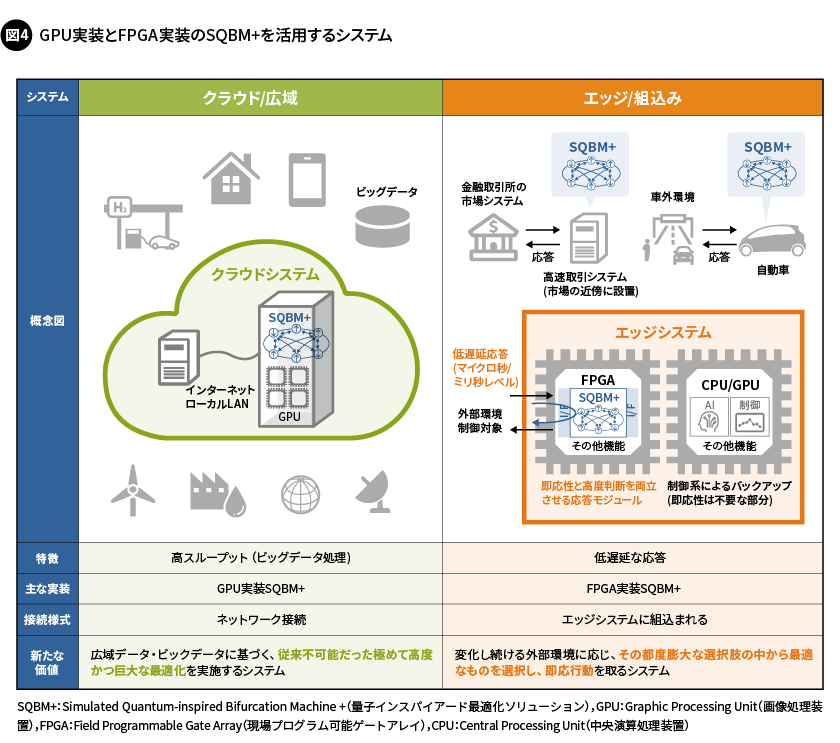
GPUへの実装は、高スループットを特徴としており、巨大な組合せ最適化問題や数多くの問題を解くシステムの構築に役立てられます。クラウドコンピューティング環境にあるGPUの資源を使うことで、広域なデータやビッグデータに基づいて、従来は不可能だった極めて高度かつ巨大な最適化を行うシステムを実現することが可能となります。
一方、FPGAへの実装は低遅延な応答を特徴としており、変化し続ける外部環境に応じて、その都度、膨大な選択肢の中から最適なものを選択し、即応行動を取るエッジシステムを構築することが可能となります。このような低遅延応答は、量子インスパイアードアルゴリズムの専用ハードウェアだけでなく、そのほかのシステムモジュールを1つのFPGAに混載することで実現します。このようなFPGA実装した量子インスパイアード最適化ソリューション「SQBM+(Simulated Quantum-inspired Bifurcation Machine +)」の応用分野としては、高度な高速金融取引システムや車載制御システムなどが考えられます。
今回はFPGAとは何か、そしてFPGAに実装する量子インスパイアード最適化技術の特徴について説明しました。第6回では、SBアルゴリズムを実装したFPGAを活用する金融・車載システムの具体例を紹介します。ご期待ください。

辰村 光介(TATSUMURA Kosuke)
株式会社東芝 研究開発センター 情報通信プラットフォーム研究所コンピュータ&ネットワークシステムラボラトリー フェロー
東芝デジタルソリューションズ株式会社 ICTソリューション事業部 データ事業推進部 新規事業開発担当 フェロー
東芝に入社後、ドメインスペシフィックコンピューティングに関する研究開発に従事。現在は量子インスパイアード最適化ソリューション「SQBM+」に関する研究開発および事業開発に取り組んでいる。

山崎 雅也(YAMASAKI Masaya)
株式会社東芝 研究開発センター 情報通信プラットフォーム研究所コンピュータ&ネットワークシステムラボラトリー エキスパート
東芝に入社後、TV向け映像エンジンの高画質化回路設計開発および高位設計によるFPGA高速回路実装に従事。現在は量子インスパイアード最適化ソリューション「SQBM+」に関する研究開発に取り組んでいる。
- この記事に掲載の、社名、部署名、役職名などは、2025年3月現在のものです。
- この記事に記載されている社名および商品名は、それぞれ各社が商標または登録商標として使用している場合があります。
>> 関連情報
関連記事
連載:複雑で膨大な選択肢から最適な解を短時間で導き出す量子インスパイアード最適化技術(連載記事一覧)




