


When people are shown in news programs or on sports broadcasts, their names are displayed in on-screen tickers for the benefit of viewers. It is never something special. Many viewers might see it as a norm. However, behind the scenes, there are extremely important works: while watching the video, accurately identifying each person that is shown, making sure that the person shown on-screen is the intended person, and confirming that the correct name is shown in the on-screen ticker. This isn’t a job that just anyone could do. It is a demanding skill, and those who do this work must be able to, for example, confirm who is shown in videos even when there are ten or more people shown on-screen, and to immediately identify the names of members of the general public, such as amateur competitors in sports.
Recently, the work being performed by the media industry, including broadcasting stations, has been diversifying and growing increasingly complex. For example, various services are being used to stream content. There are limits to the industry’s ability to provide viewers with more appealing content through different media if it continues to rely on the skills of individual personnel. That’s why there are high expectations for the potential of AI.
In this article, we will introduce Kaometa, Toshiba’s facial recognition AI. Kaometa assists the media industry, such as broadcasting stations, in creating accurate video content and efficiently using their video archives by attaching metadata. It is also expected to be applied to various video content that exists in our daily lives.
Toshiba’s facial recognition technologies have some of the highest levels of recognition accuracy in the world
In recent years, facial recognition systems have become part of our daily lives, used to log into smartphones and to enter offices and event sites. Facial recognition is a type of biometric authentication, similar to fingerprint or iris recognition. Facial images are registered for people in advance, and then faces are detected in real time in data from cameras and identified by comparing them to registered facial data. The use of facial recognition has risen dramatically as the COVID-19 pandemic has created a demand for safe, secure activity that avoids physical contact.
Toshiba has a track record of over 50 years of AI research. A benchmark test conducted by the U.S.-based National Institute of Standards and Technology (NIST) in one area of that research, facial recognition, found Toshiba technologies to be some of the top technologies in the world, and the best technologies of their kind from any Japanese company (as of October 2021). These technologies have also achieved a high level of accuracy in recognizing faces even when masks are being worn.
Advanced facial recognition technologies developed especially for video content
Based on our world-class technology, we have engaged in advanced facial recognition technology R&D focused on video content. Thanks to these efforts, we have launched Kaometa facial recognition AI to the media industry. In conventional biometric authentication applications, facial recognition has generally been performed on a single person appearing in a video camera image. However, usage scenarios such as identifying who is shown in video content or attaching metadata that indicates who appears in a video, so that scenes can be efficiently selected later, requires facial recognition technology that satisfies advanced requirements. This includes the ability to perform rapid, highly accurate, continuous facial recognition, along with the ability to identify multiple people simultaneously.
That’s why we, together with the Nippon Television Network Corporation and the Toshiba Corporate Research & Development Center, developed a facial recognition engine especially for video content. For example, during live shows such as news programs or sporting events, broadcasting stations must be able to confirm, in real time, if the person being shown is the person they intended to show. That means that facial recognition must be performed quickly, accurately, and continuously. The engine we developed can even perform facial recognition processing in real time on numerous small faces in scenes where there are numerous people on-screen, such as on variety shows and in team sporting events. We have also made revisions and improvements to the facial recognition engine to meet the requirements of specific video content uses. For example, the engine can recognize faces in low-resolution images shown on split screens, like when confirming multiple video feeds. It can continue to track people for facial recognition purposes even if their faces are hidden due to their posture. It can even rapidly identify faces in video materials for use in live broadcasts, which requires accurate and clear video editing under severe time constraints.
What is the Kaometa facial recognition AI?
Kaometa is a solution that makes it possible to identify people in video in real time, and to attach meta information, simply by registering images of the faces of the people you wish to identify in a face dictionary in advance (Fig. 1).
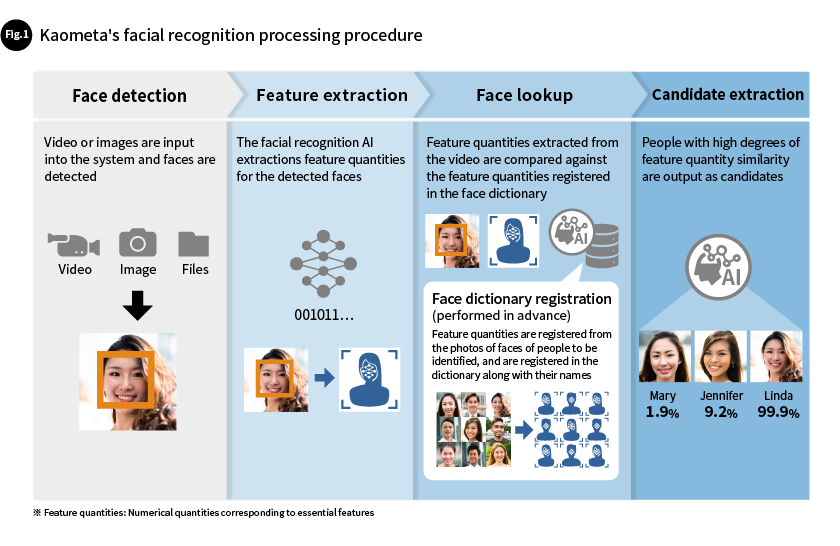
The first step in performing facial recognition is registering to a face dictionary. This dictionary contains feature quantities generated from images of the faces of all the people who are to be recognized, along with their names and other information. This dictionary can be used to identify people based on just one image, even if there are obscuring factors in the video, such as they have different facial expressions, are wearing a mask, or are in a low-light setting. Facial registration also works if the age of the person is different from the registered image, as long as the image registered in the face dictionary was taken when the person was an adult.
Kaometa supports both real time processing, immediately processing images fed in via an SDI (Serial Digital Interface) or HDMI (High-Definition Multimedia Interface) connection, and offline processing on video files such as mp4 files. When a video or image is fed into the system, it uses facial recognition AI to detect the presence and location of faces. Feature quantities are then extracted from the face and compared against the feature quantities registered in the face dictionary to output candidates with a high degree of resemblance.
In the case of news and sports programs, it may be difficult to register facial photographs in the face dictionary in advance. In cases such as this, Kaometa clusters faces detected in the video to create a list of people appearing in the video. Facial images can be registered in the face dictionary on the spot, building up the face dictionary as work progresses.
Kaometa use cases
Kaometa’s subject recognition capabilities can be used not only to confirm if the intended person is being shown, but also to recognize the low-resolution faces that are often shown in the nine-split multicam view, assisting with camera switching. It is effective in detecting when people have been captured in a video feed and ensuring their privacy, searching for VIPs and other key people in crowded scenes, and checking if names and titles shown in tickers are correct (Fig. 2).

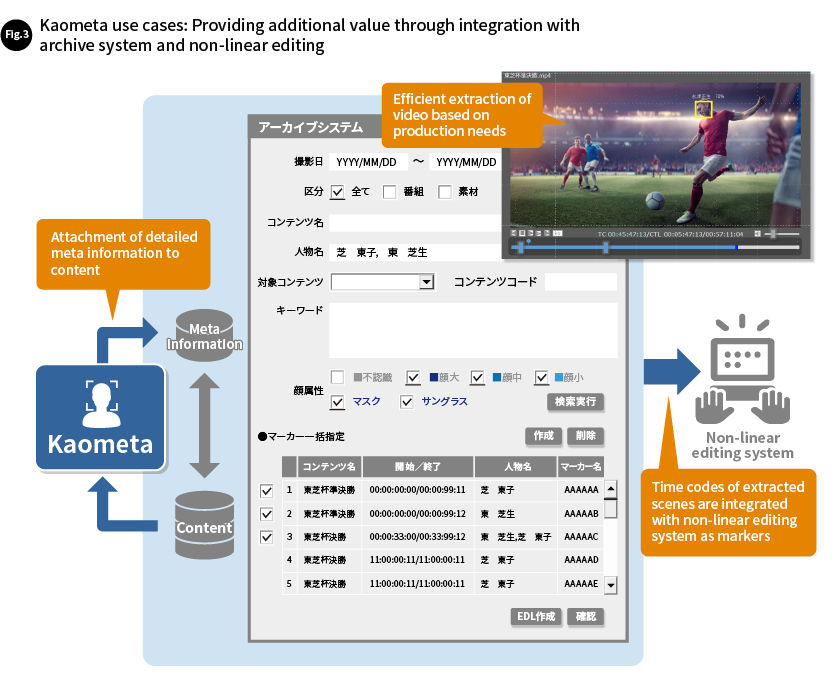
It also supplies an application programming interface (API), so Kaometa can be integrated with existing operational systems. In other words, it makes it possible to deploy AI-based facial recognition without changing the systems and operational processes that are already in use. For example, Kaometa can be used to attach detailed meta information to videos stored in an archive system, so specific videos and scenes can be searched for accurately. This is expected to promote the use of archive video.
The start and end times of scenes searched for using Kaometa can be fed into a nonlinear editing system to immediately extract and edit desired scenes, improving the overall efficiency of operations (Fig. 3).
A rich lineup of models, available for various usage situations
The Kaometa lineup consists of three models, so users can pick the model that best fits their video content, company scale, usage situation, and the like: Kaometa Live, Kaometa Archive, and Kaometa Entry.
Kaometa Live is the top-end model, offering every Kaometa function. It supports real-time processing of video, which is important for live broadcasting and streaming, as well as functions such as file processing necessary for archive video, and program editing. It can therefore be used in every kind of usage scenario.
Kaometa Archive offers a carefully selected set of functions that specialize in archive video processing, such as attaching meta information to video content and extracting scenes in which specified subjects appear.
Kaometa Entry is suited for use in short video content such as commercials and social media. The facial recognition engine itself is the same as that employed in the higher-end models, so it can be used to confirm the people appearing in video content using highly accurate facial recognition. It helps protect people’s privacy by identifying who is shown in videos.
Kaometa Archive and Kaometa Entry can be used on any general-purpose computer that meets their operating requirements.
Real-time facial recognition is contributing to broadcasting and child care
The Kaometa solution was created in conjunction with Nippon Television Network Corporation, developed through verification testing in the actual broadcasting field. It is currently used in WhoFinder, a business application sold by NTV Wands Inc. for use in the broadcasting industry.
Kaometa has evolved to better meet the needs of worksites where video content is used. We are leveraging Kaometa’s high-speed, real-time performance, and its high-resolution facial recognition capabilities among the top in the world, to extend its use to an even wider range of applications.
One of these is our collaboration with ChiCaRo Inc., through which Kaometa is being used in ChiCaRo childcare support robots. ChiCaRo is a robot that can remotely communicate with children. It aims to alleviate the problem of solo childcare, in which the entire burden of childcare is borne by one person. Linking ChiCaRo with Kaometa enables it to identify individual children in groups. Some childcare facilities face a shortage of childcare providers. Through a new service that combines Kaometa and ChiCaRo, we are helping create environments that watch over children, analyzing collected information, improving the quality of childcare, and helping parents gain a better understanding of their children.
Kaometa is not only supporting various work performed in the media industry, but is also assisting with the promotion of multifaceted video content use such as streaming and overseas use through various services. It is a solution that can be used in various kinds of situations which involve the use of video content.
It also has great potential as a solution that will offer people safety and security such as privacy protection. Toshiba will continue to leverage this state-of-the-art technology to contribute to society.
- WhoFinder is a registered trademark of Nippon Television Network Corporation in Japan.
- All other company names or product names mentioned in this article may be trademarks or registered trademarks of their respective companies.
- Kaometa is not currently available for purchase outside Japan.
- This article was co-authored by KEZUKA Masayoshi, Specialist, Sales Group, Media & Service Solutions Sales & Engineering Dept., ICT Solutions Div., Toshiba Digital Solutions Corporation, and SEKO Akiko, Specialist, Engineering Group 2, Media & Service Solutions Sales & Engineering Dept., ICT Solutions Div., Toshiba Digital Solutions Corporation.
- The corporate names, organization names, job titles and other names and titles appearing in this article are those as of March 2023.
