
AI Technology
多様な声を簡単・自在に作成できる声デザイン技術を開発-低コスト・短期間で多様な音声コンテンツの制作が可能―
2016年3月
概要
当社は、利用用途にあわせて多様な声を簡単・自在に音声合成で作成できる「声デザイン技術」を開発しました。ユーザーが、「性別」「年齢」「明るさ」などの声の特徴を示す各要素の強度を操作することで、多様な声を作り出せる技術です。これまでにない数万種類以上の声を生成できるだけでなく、GUI(グラフィカル・ユーザ・インターフェース)と組み合わせることで、従来の技術では難しかった「利用者のイメージに合った声」を、直観的な操作で効率的にデザインすることができます。
これにより、利用シーンにあわせた音声コンテンツを低コスト・短時間で作成できます。本技術の詳細は、3月9~11日に桐蔭横浜大学で開催される日本音響学会主催の「2016年春季研究発表会」で発表します。
開発の背景
音声合成は、カーナビ等のガイド音声、書籍や教材の朗読音声、ゲームや対話アプリでのキャラクタの音声など、様々な音声コンテンツの制作に使われ始めており、今後ますますIoT化される社会の中で、音声広告や映像制作、コミュニケーションロボット、オンライン教育などでの活用が広がることが期待されています。こうした多様な音声コンテンツを効果的に制作するには、対象コンテンツに必要な声を、簡単に入手するための手段が必要です。
しかし、従来、音声合成の声は、システム上にあらかじめ準備されているサンプルから選択するため、選択肢は限られていました。また、多数の声のサンプルが準備されている場合も、その中から求める特徴の声を探し出すのは容易ではありませんでした。
本技術の特徴
当社は、利用用途にあわせて多様な声を簡単に作成できる新たな「声デザイン技術」を開発しました。従来はシステム上に準備されたサンプルからの選択式だった声質を、ユーザーが自由にコントロールすることで、幅広い種類の声を簡単に作成することができます。
本技術では、話者による声質の違いを、当社独自のモデル最適化方式によって「性別」「年齢」「明るさ」などの知覚的な声の特徴を示す複数の要素(知覚語)に分解、モデル化した「知覚語空間モデル」を開発し、各要素の強度を変えることで声を自由に作成できるようにしました。
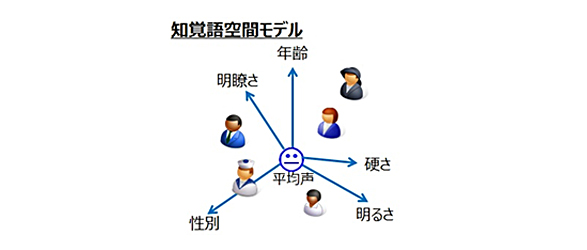
さらに、本モデルを元に、直感的な操作によって簡単に声を作成できる「GUI (グラフィカル・ユーザ・インタフェース)」を試作しました。声の特徴を示す知覚語の設定においては、多数の評価者による主観評価の結果をもとに統計分析を行い、代表的な少数の知覚語を選定しました。
また、求める特徴の声をもっと簡単に作り出せるよう、「かわいい」「知的」「丁寧」などの声の印象を表す印象語から「知覚語空間」の座標を定める「印象語変換モデル」を開発し、GUIに組み込んでいます。このGUIでは、「かわいい」「知的」などの印象語やキャラクタの顔画像からベースの声を選定し、さらに、「性別」「年齢」「明るさ」などの知覚語の軸で声の特徴を調整することによって、利用者のイメージに合った声を直観的な操作で効率的にデザインできます。
※再生ボタンをクリックすると、YouTubeに掲載している動画が再生されます。
※YouTubeは弊社とは別企業のサービスであり、各サービスの利用規約に則りご利用ください。
今後の展望
当社は、音声や映像から人の意図や状況を理解し人にわかりやすく伝え、人々の様々な活動を支援する、当社のクラウドサービス「RECAIUS™(リカイアス)」に、本技術を2016年度中に搭載することを目指して研究開発を進めていきます。
※RECAIUSは、株式会社東芝の商標です。