
AI Technology
声と背景音のボリュームバランスを調整できる音源バランスコントロール技術
2013年4月
概要
当社は、音の入力信号から人の声と背景音の音源信号を推定する音源分離技術を開発しました。この技術を利用すれば、映像コンテンツを視聴する際に人の声を聴き取りやすくしたり、背景音を静かに抑えたり、スポーツの臨場感を高めたり、歌の練習をすることもできます。デジタル映像機器全般に汎用的に活用できる技術です。
開発の背景
様々なデジタル映像機器の普及に伴い、映像コンテンツの視聴方法が多様化しました。手軽に映像を楽しめるようになった反面、人の声が音楽など背景音に埋もれて聴き取りにくい場合や、歓声など背景音が小さくて臨場感を楽しめない場合もあり、人の声や背景音の強調など、音源毎のボリューム調整を目的とした高音質化機能が期待されるようになりました。しかし、従来の高音質化機能では、映像シーンや音声の収録方式など、入力信号の特性が変わると音源信号の推定が不十分で、音質が劣化してしまうという課題がありました。
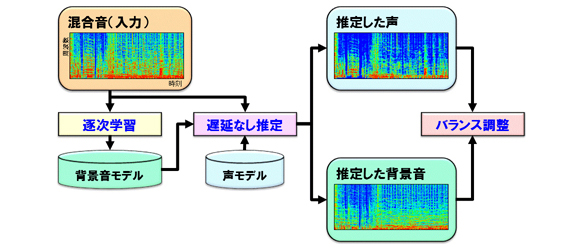
音源バランスコントロール技術
そこで、当社は、音の入力信号から背景音情報を学習、更新しながら人の声と背景音の音源信号を推定する、音源分離手法を開発しました。この技術は処理が軽く遅延がないため、端末を選ばず、効果をその場で体感することができます。また、人の声と背景音を個別に逐次学習するため、シーンや収録方式によらず音源信号を推定することができます。更に、音楽、歓声、雑音など、様々な背景音に柔軟に対応できるため、ホームビデオのようなアマチュアが作成したコンテンツに対しても有効です。すなわち、多様なコンテンツに対して効果を汎用的に発揮できます。この技術をデジタル映像機器に適用すれば、映像コンテンツを視聴している際に、人の声を聴き取りやすくできる、背景音を静かにできる、スポーツの臨場感を高められる、歌の練習ができるといった新しい機能をユーザに提供できます。
今後の予定
様々な視聴環境および視聴スタイルに応じた音源バランスコントロール方法を具体化し、新しいアプリケーションを開発していきます。