
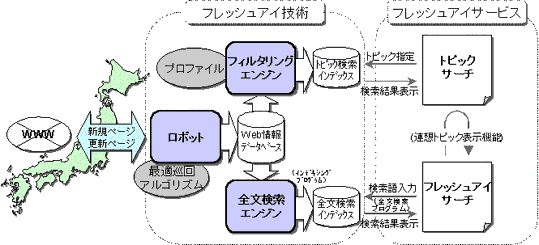
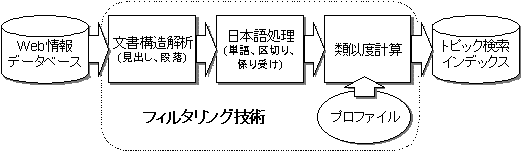
 フレッシュアイの全体構造
フレッシュアイの全体構造
 |
プレスリリース記載の情報(製品価格/仕様、サービスの内容、お問い合わせ先、URL等)は、発表日現在の情報です。予告なしに変更されることがありますので、あらかじめご了承ください。最新のお問い合わせ先は、東芝全体のお問い合わせ一覧をご覧下さい。 | |
|
プレスリリース記載の情報(製品価格/仕様、サービスの内容、お問い合わせ先、URL等)は、発表日現在の情報です。予告なしに変更されることがありますので、あらかじめご了承ください。最新のお問い合わせ先は、東芝全体のお問い合わせ一覧をご覧下さい。 | |