
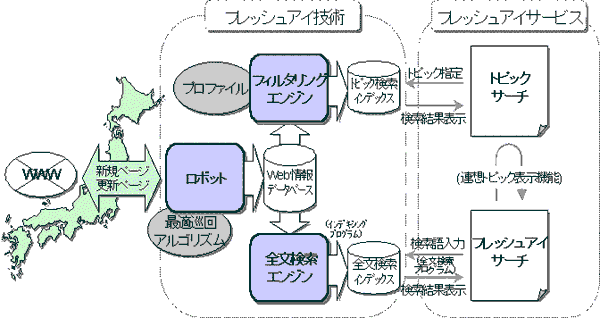
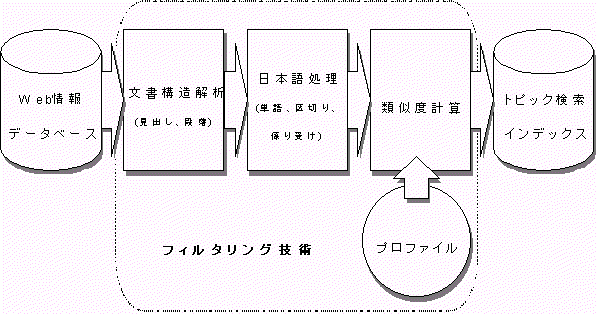
| フレッシュアイを支えるテクノロジーについて 日本の検索サービスの多くは、海外で開発された検索技術をベースにしているのに対して、 フレッシュアイの検索技術は、すべて当社が独自に開発したものです。 フレッシュアイの技術は、(1)Webページの自動収集を行う「ロボット技術」、 (2)収集したページを自動的にトピックへ分類する「フィルタリング技術」、 (3)ロボットが収集したWebページに索引(インデックス)を付け、 入力された検索語に適合するページを探し出す「全文検索技術」の3つから構成されます。
フレッシュアイのロボットは、 インターネットを巡回し新規情報を収集してWeb情報データベースに登録します。 訪問対象は、国内外にある日本語で書かれたサイトです。 ロボットは、新規または更新されたWebページのみを効率よく探し出せるように作られた最適巡回アルゴリズムに従って、 新しいと判断したWebページの情報だけを効率的に収集します。 また、各サイトの更新頻度を自動学習し、 更新時期に合わせて訪問するように設定されています。 これによってWebページ情報の収集スピードが向上します。 (2)トピックサーチのテクノロジー
フレッシュアイサーチのための全文検索エンジンでは、 インデキシングプログラムによって、Web情報データベース上にある各Webページについて、 索引付けを行って全文検索インデックスへ登録します。 フレッシュアイではこの全文検索インデックスの更新を一日に数回という高い頻度で行うため、 最短で12時間前に開設されたばかりのWebページも検索することができます。
|
 |
プレスリリース記載の情報(製品価格/仕様、サービスの内容、お問い合わせ先、URL等)は、発表日現在の情報です。予告なしに変更されることがありますので、あらかじめご了承ください。最新のお問い合わせ先は、東芝全体のお問い合わせ一覧をご覧下さい。 | |