


家電やカーナビゲーションをはじめ、音声を用いてユーザーに情報を伝えるコンシューマー向けの機器には、多種多様なものがあります。例えば、電車やバスの車内アナウンスや、スマートフォンアプリやゲームに登場するキャラクターのセリフ。これまでは、人が話した言葉を録音してさまざまな機器で音声を再生していましたが、近年は進化した音声合成の技術によって、人工的に作られた合成音声が利用される場面が増えています。東芝は、この音声合成技術に長年にわたり取り組んできました。より自然で質の高い音声を作り出すために、多くの基本技術を開発しています。ここでは、音声合成に関連する社会動向や東芝の技術の特長、製品開発の最前線、今後の世の中へ向けた展望などについて、3回の連載で解説します。
今回は、世の中における音声合成の利用シーンや一般的な技術、そして東芝の技術とその特長です。
広がる音声合成の用途と利用シーン
音声は、話し手が発した内容である言語と、そこに含まれる感情のような非言語の情報を、同時に聞き手に伝えられるものです。たとえ話し手が聞き手から見えない距離や角度にいても、また聞き手が、ほかの作業などで「聞く」という行為に集中していない場合でも、機能します。このため、人にとって自然かつ適時性に優れたコミュニケーションの手段といえます。
人が話す声、すなわち音声を任意のテキストを元に作り出すのが、音声合成技術です。作る音声の声色(話し方・声の質など)を、あらかじめ手本として収録した声の主(話者)に似せることもできます。音声が持つ特徴を手軽に生かせるようになることから、音声合成技術は、日常のさまざまなシーンや用途において、広く利用されています(図1)。

まず、典型的な用途として挙げられるのは、機器と人とのインターフェースを構築するための機能部品(音声生成システム)です。実際に、さまざまな民生用の製品や業務システム、サービスに実装されています。例えば、カーナビゲーションシステム(以下、カーナビ)です。カーナビによる音声を使ったルートや交通情報、気象情報などの案内により、ユーザーは自動車の運転中に視線を変えることなく情報を取得し、目的地にたどり着けます。このように、状況に応じたタイムリーな情報提供がカーナビから音声でできるようになったことで、地図などを表示している表示画面と音声出力を併用した、より効果的な伝え方や効率的な活用が可能となります。さらには音声が機能することで、画面サイズの小型化など、製品を提供者する側のコストを抑えられることも期待できます。
次に、音声の自然さ(人間らしさ、聞き取りやすさなど)が向上したことで、従来は人が対応していた作業やサービスを代替する用途も増えています。これまでは、固定のアナウンスやガイダンスなどに用いる音声を人があらかじめ収録したり、その場の状況に応じて変わる情報の案内や説明を人が行ったりしていました。これらに対しても、音声合成技術の活用が広がっています。自分たちが必要とするタイミングで適切なテキストデータを入力して音声に変換し、再生するといった活用です。例えば、美術館における説明員のナレーションや、教育用の教材に収録する音声ガイダンス、鉄道など公共交通機関における構内や乗り物内でのアナウンスなどが挙げられます。音声合成技術を活用することで、タイムリーな内容の更新によるきめ細かな情報の提供を望む提供者側のコストを抑えることが期待できます。
さらには、手本として収録した音声の話者が持つ話し方や音色といった個性の再現度や表現力が増したことで、情報伝達を目的とする用途に限られない、声優やナレーターのような魅力的な声色を持つ話者に似せた合成音声の活用も増えつつあります※。例えば、アニメーションやゲームに登場するキャラクターに用いる音声の制作などが挙げられます。これによって、制作者はより豊かなコンテンツを提供でき、ユーザーはより良い体験を得ることができるようになります。
今後、さらなる技術の進化や社会的な認知の高まりにつれて、音声合成技術の用途や活用シーンが、より広がっていくことが期待できます。
※声の権利関係や収録音源の管理などにおける世の中の動向は、第3回で解説します。
音声合成の基本技術
任意のテキストデータに対して自然で質の高い音声を生成(合成)するには、人が聞き取りやすく、各言語や各地域で違和感がない話し方となる発音やアクセント、イントネーション、リズムなどを実現する音声波形を作り出す必要があります。また、違和感がなく意味が伝わる合成音声を、手本として収録した音声の話者の個性に近づけるためには、収録した音声からその話者の話し方や音色の特徴を高い精度で抽出し、それを任意のテキストに対して音声波形で表現できなければなりません。
これらを実現するために、さまざまな技術が用いられます。その中から、音声合成において基本となる技術を、テキストから音声を作り出す「生成過程」と、推定モデルのパラメーター値を獲得するための「学習過程」に分けて説明します。
・生成過程
合成音声は、テキスト解析、韻律生成、そして音声信号生成という、3つの処理を経て生成します(図2)。
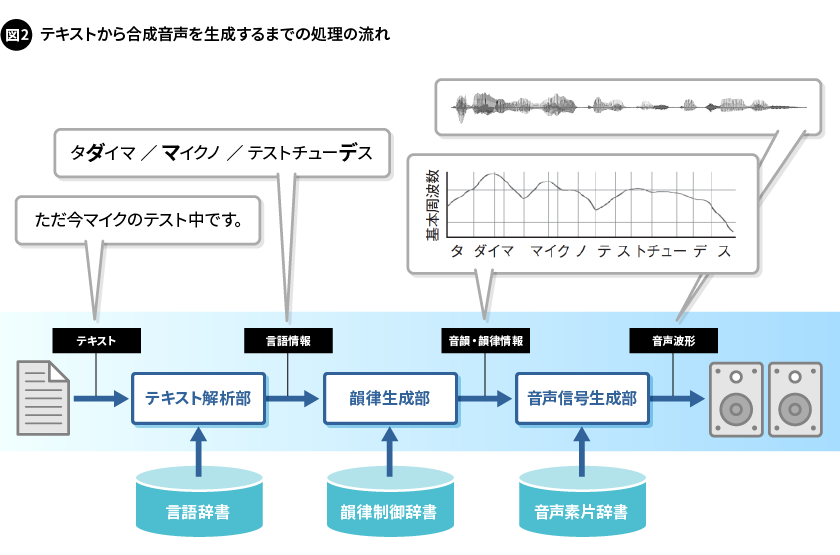
まずテキスト解析部では、入力された任意のテキストを言語モデル(規則・言語辞書)に基づいて解析し、各言語において標準的な「言語情報」を出力します。言語情報は、単語や形態素(意味を持つ最小の言語単位)の区切りや品詞のような言語属性をはじめ、読み(言語的な意味を表現するために必要な音の種類を表現した記号の列)、アクセントやイントネーションといった音調単位の区切り、さらには各音調単位の核となる変化点の位置や変化の程度などがあります。
次の韻律生成部では、韻律制御辞書を用いた推定モデルを用いて、テキスト解析部で出力した品詞や読み、アクセントの位置といった質的変数である言語情報から、声(音)の高さや長さといった各種物理量の変化パターンである「音韻・韻律情報」を生成します。音韻・韻律情報には、基本周波数(声の高さ)の時間変化パターン(以下、基本周波数パターン)や、各音韻の継続時間(長さ)といったものがあり、これらによって合成音声のアクセントやイントネーション、リズムなどを表現します。基本周波数パターンは、もっとも声の自然さや話し方の個性に影響する要素です。
最後に音声信号生成部です。ここでは、音声合成に使用する基本的な音声の断片や単位である音声素片を、音韻・韻律情報に従って選択・接続することで、音声波形を生成します。各音声素片の選択と、それらの接続方法は、声としての自然さや話者の声質といった個性の再現度に影響します。
・学習過程
生成過程の各処理部では、さまざまな推定方式とモデルが導入されており、また各モデルを表現するパラメーター群(モデルパラメーター)の値は、学習により獲得します。東芝では、合成音声の品質を向上させるために、新しいモデルと、そのパラメーターの学習方法をいくつも考案し、それらを利用した音声合成システムの開発を続けてきました。その代表的な技術は、次の章で紹介します。
また、合成音声の品質向上には、上記のような推定・学習方式の考案だけではなく、それらの処理の入出力となる特徴量や属性のようなパラメーターの考案とその値の導出方法、精度の高い推論や効率の良い学習を行うための音声コーパス(学習用の情報を付加した大量の音声データ)の収集方法も重要です。収集方法とは、音声コーパスの作成にあたって「そもそも何を収録するのか」「効率的に作成するには何を収録すればよいか」「狙いどおりの音源を録音するために何を演者に指示するか(ディレクション)」といったことです。このような音声コーパスを設計するノウハウは、音声合成の実用化に欠かせません。どんなに音質の優れた音声合成方式でも、収録する音声の種類や量、あるいは特徴量の抽出や機械学習、推定処理にかける計算リソースをやみくもに増やしては、工業製品としての実用性が低下するからです。
このように、音声合成技術には、さまざまな技術が複合的に関わっています。
東芝の音声合成の特長とこれを支える独自技術
当社の音声合成技術は、任意のテキストに対して自然で滑らかな音質の合成音声を生成でき、かつ、その処理に必要なメモリサイズや計算量を小さく抑えているものです。これらの特長は、韻律生成と音声信号生成の処理部に用いている、以下のような独自技術により、実現しています。
・閉ループ学習方式
当社がいまから約30年前に開発した、韻律と音声素片の閉ループ学習という基本方式の本質は、収録した音声と合成音声での違いを定式化し、その違いを最小化する音声素片を、収録した音声から自動的に獲得する学習方法にあります。それまで行われていた、エンジニアが不自然な合成音声を見つけるたびに個別に調整して改善するような、アドホックな(その場限りの)開発手法ではありません。この方式の実現により、学習に使用した収録音声の全体に対して最適な音声素片を、計算によって獲得できるようになりました。テキストから合成音声を生成するときは、学習済みのモデルや音声素片を使います。小さい演算量とメモリサイズで音声合成が行え、また大規模なデータベースから韻律情報や音声素片を探索する必要がない、画期的な方法です。
・代表パターンコードブック方式
韻律パターンの学習に閉ループ学習を適用して開発したものが、代表パターンコードブック方式です。収録した音声から抽出した基本周波数パターンを手本として、代表パターンコードブックと呼ぶ文節(アクセント句)単位の典型的な基本周波数パターンと、それを選択したり制御したりする規則を学習により獲得します。代表パターンコードブックは話者ごとに形状が異なり、規則は収録した音声に依存することから、話者の特徴を捉えた基本周波数パターンの生成が行えます。
・複数素片選択融合方式
音声信号生成部における音声素片の選択肢のいずれもが、目標とするコンテキスト(基本周波数、継続時間、前後の音韻など)から遠い(あるいは「ない」)場合は、部分的に音質が低下する問題があります。そこで、音素や音節などの各合成単位に対して部分的にコンテキストが近い複数個の音声素片を、収録した音声から選択し、それらを融合して新しい音声素片を生成する方式を開発しました。融合した音声素片を、韻律情報に従い接続することで、鼻声のようなこもった聞こえや音質の低下を抑えた、均質で安定した音声を生成できるようになりました。
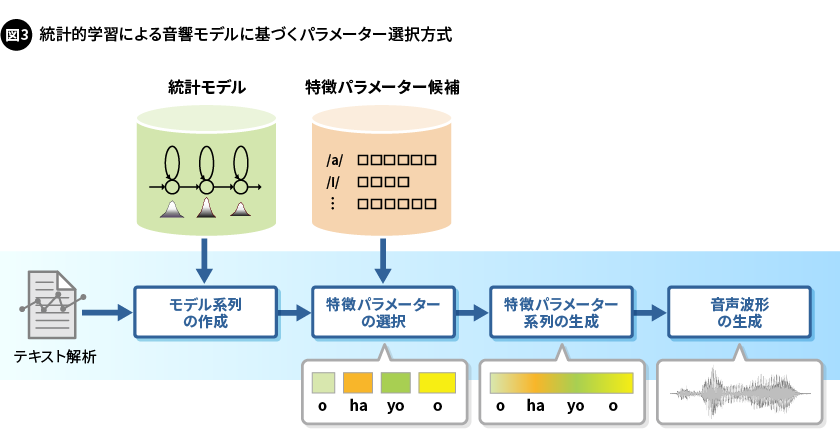
・統計的学習による音響モデルに基づくパラメーター選択方式
話者への適応や感情の制御といった合成音声の多様性向上に有用な技術と親和性が高い方式として、隠れマルコフモデル(Hidden Markov Model:HMM)という統計モデルに基づく音声合成方式も開発していました。この方式では当初、特徴パラメーターを特徴量分布へとモデル化することで過剰な平滑化が起こり、音声の再現性が低下してしまう問題がありました。この問題に対して、モデル化された分布から導出した値ではなく、その分布を作成するもとになった学習データの中から選択する統計的手法を導入して収録した音声から得た(平滑化されていない)特徴パラメーターの値を選択し、その特徴パラメーターを滑らかに変化させることで、クリアで不連続感も抑えた特徴パラメーター系列を生成する改良を加えました。また、パワースペクトル(周波数成分ごとのエネルギーの強さ)だけではなく音声の波形形状を表す位相情報(周波数成分ごとの時間軸上の位置)も含めた新たな特徴パラメーターを導入することで、音声を精密に表現できるようになりました。これらにより、過剰な平滑化が解消されて音声の表現力が増し、多様性と音質の両立、さらには手本とした話者の音声に対する再現性が向上しました(図3)。
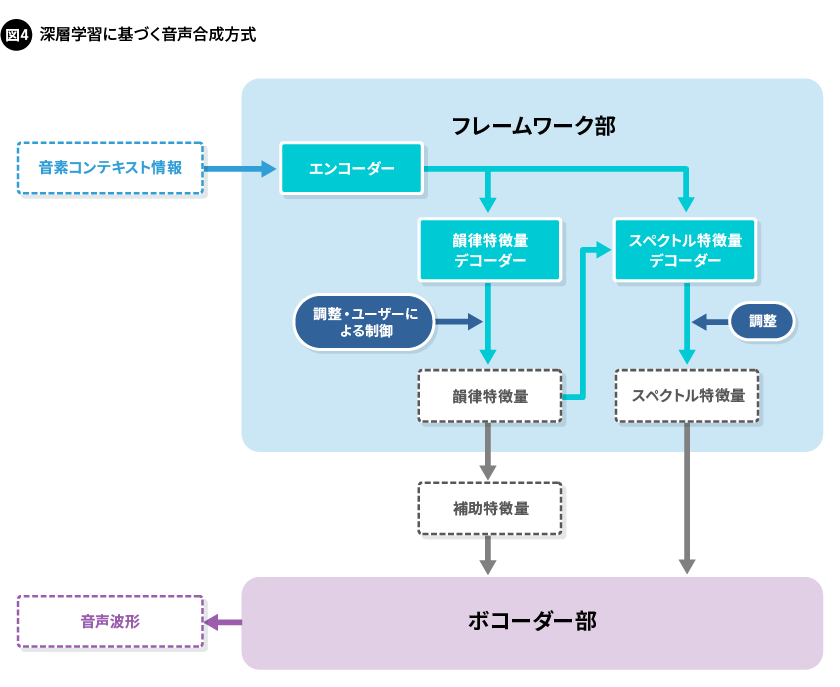
・深層学習に基づく音声合成方式
近年、深層学習(ディープラーニング)の導入によって、合成音声の品質が格段に向上しています。当社でも、音声合成に関する既存の製品の機能性は維持したまま、さらなる音声の品質の向上に向けて、深層学習を用いた音声合成方式を開発しています。この方式では、特徴量を求めるデコーダーを、韻律特徴量用とスペクトル特徴量用に分離することで、各特徴量を必要に応じて調整できるようにしました。また、スペクトル特徴量の生成と、スペクトル特徴量や韻律の補助特徴量から音声波形を生成するボコーダーの処理を逐次的に行えるようにし、音素コンテキスト情報が入力されてから音声波形を出力し始めるまでの応答時間を短くしています。さらには、当社独自のDNN(深層ニューラルネットワーク)コンパクト化技術の適用により、従来の方式を超える省メモリ化も実現しました(図4)。
当社では、継続的に新しい基本方式を考案し、新たな機能の開発や品質の改善を続けながら、さまざまな機器への組み込みの用途で利用できる省リソース化を追求した音声合成技術を開発しています。今回の記事では、音声合成に関する世の中の動向と東芝の技術が持つ特長について説明しました。次回は、多くの企業で活用されている東芝の音声合成ミドルウェア「ToSpeak」を中心に、さまざまな音声を実現する技術を紹介します。ご期待ください。

西山 修(NISHIYAMA Osamu)
東芝デジタルソリューションズ株式会社
デジタルエンジニアリングセンター リカイアスビジネス推進部
エキスパート
東芝に入社後、音声合成技術の研究開発に従事。2012年からは、音声認識や音声合成の技術を活用した製品およびサービスの拡販に携わる。現在は、音声技術の商品企画にも取り組んでいる。
- この記事に掲載の、社名、部署名、役職名などは、2025年3月現在のものです。
- この記事に記載されている社名および商品名、機能などの名称は、それぞれ各社が商標または登録商標として使用している場合があります。



