

世の中のさまざまなモノへIoT(Internet of Things)の適用が広がる中、サイバーフィジカルシステム(CPS:Cyber Physical Systems)が注目されています。CPSとは、実世界(フィジカル空間)にあるIoTデバイスやセンサーから多種多様な情報を収集し、仮想世界(サイバー空間)で大規模データ処理技術などを駆使してリアルタイムに分析し、そこで創出した情報や価値を実世界に戻すことで、産業の活性化や社会問題の解決を目指す仕組みです。ここでは、CPSを実現するために必要となるデータ基盤技術と、そのコアとなる「データベース管理システム(DBMS:DataBase Management System)」について、3回にわたって解説します。
第1回では、従来とは異なる「NoSQL」と、ビッグデータやIoTシステムに特化した東芝のデータベースである「GridDB」が誕生した背景、そしてGridDBの基本的な特長の中から独自のデータモデルであるキーコンテナ型データモデルについて紹介しました。第2回では、進化を続けるGridDBにおけるデータ基盤技術の特長と、ペタバイト級の製造データの活用に貢献した実際の適用事例を解説します。
ペタバイト級の時系列データを絶え間なく高速で分散処理
一般的に、GridDB をはじめとするNoSQL DBMSの特性は、CAP定理で示された「一貫性(Consistency)」「可用性(Availability)」「分断耐性(Partition tolerance)」という3つの要素で説明できます。第1回で解説したように、CAP定理によると、この3つの要素のすべてを満たす分散システムは実現できないとされています。GridDBは、3つの要素のうち、データの一貫性とシステムの分断耐性を優先するCP型のデータベースに分類されます。深刻なネットワークの分断により、データの操作に一貫性を欠く場合には、DBMSの稼働を停止します。ただし、DBMSの継続した稼働を維持するために、GridDBには可用性を高める独自の仕組みが備わっています。
その基本となるのが、「自律データ再配置技術(ADDA:Autonomous Data Distribution Algorithm)」です。クラスタ上のデータは「クラスタパーティション」と呼ばれる単位に分割して複製され、各ノードに分散して配置されます。ADDAに基づき、クラスタパーティションの複製(レプリカ)を各ノードがバランスよく持ち合うように、通常稼働時に自動的に複製の再配置が行われます(図1)。
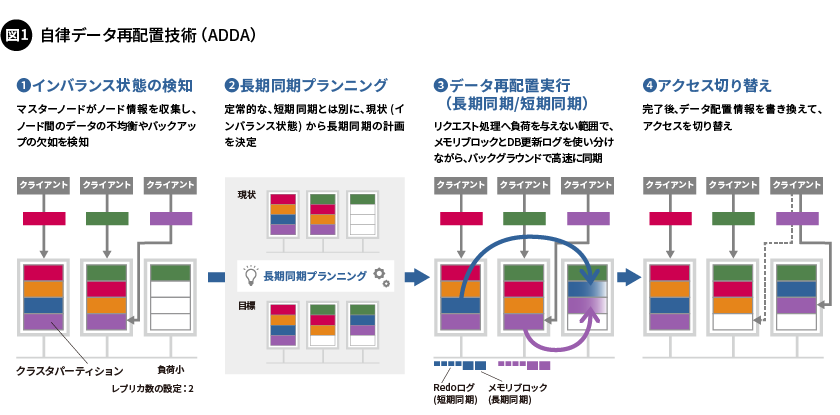
これにより、一部のノードに異常が発生して停止した場合でも、各ノードに最適に配置された複製を活用することで、わずかな時間で自動フェイルオーバー処理が完了するため、DBMSを稼働し続けることができます。万一、「スプリットブレイン」と呼ばれるノード間のネットワークが分断されるような異常が発生したとしても、クォーラムポリシー(過半数のノードからなるクラスタを正規のクラスタとみなす方針)に基づいて各ノードの判断で確実にDBMSを停止し、データの一貫性が損なわれるのを防ぎます。
ADDAは、新しいノードを追加した際にも効果を発揮します。「ノンストップスケールアウト」と呼ばれる機能で、DBMSの稼働を停止することなく、マシンの増強と、それに見合った分散処理の性能向上が期待できます。マシンのリソースを増強するために新しいノードを加えると、ADDAに基づいて自動的にデータの再配置が行われ、各データへのアクセスが一層分散されます。この特性により、データ量に応じて、一般的なIA(Intel Architecture)サーバーあるいは同等のVM(Virtual Machine:仮想マシン)などの中から、必要最小限の台数を組み合わせるだけで、高い信頼性と処理性能を備えたペタバイト級のデータベースを運用することが可能になります。
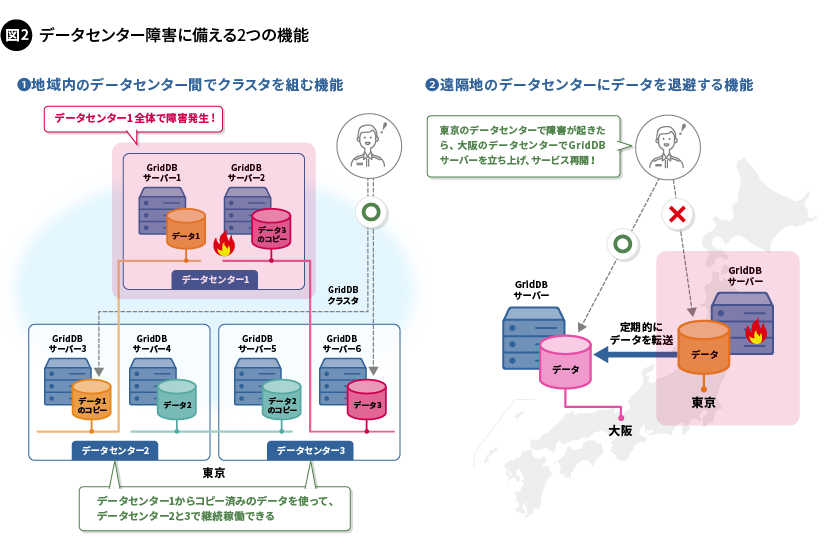
GridDBの信頼性をさらに向上させるため、同じ地域内にある複数のデータセンター間でクラスタを組む機能や、遠隔地のデータセンターにデータを退避する機能をサポートしています(図2)。これらの機能により、データセンターの一部あるいは全体に障害が起きた際にも、IoTシステムの稼働の継続を可能にします。また、クラウド上にあるプライベートネットワークのようなお客さま固有のネットワーク環境を構築しても運用できるように、マルチキャストパケット※を使用せずに構成することを可能とするクラスタ設定、複数の通信経路を使い分けるための経路設定、さらにはSSL(Secure Socket Layer)接続といった各種機能も備えています。
※マルチキャストパケット:ネットワークにおいて、複数のマシンに同じデータを一斉に送信することを意味します。GridDBでは、クラスタを構成するノードの一覧を手間なく管理するための手段として採用しています。しかし、クラウドサービスによっては使用できないなど、ネットワーク環境による制約もあるため、代替する設定機能もサポートしています。
時系列データを効率的に蓄積し続けるための技術
ビッグデータを扱うシステムの中でも特にIoTシステムにおいては、システムにつながる多数のエッジデバイスから同時多発的にデータが発生することが想定されるため、インメモリ処理に高い性能が求められます。またそれに加えて、IoTデータは24時間365日絶え間なく発生し続けることから、長期的に効率よくストレージへアクセスできることも欠かせません。GridDBは、この両面において強みを発揮します。
まずGridDBの高いインメモリ処理性能を支えるために開発したのが、イベント駆動型の処理エンジンです。同一のクラスタパーティションごとに、担当させる処理スレッドを割り振ることで、バッファ単位でのロックを必要としない、ロックフリー型のバッファ処理を実現しています。さらにストレージへの書き出し量を抑えるデータベースログ処理や、高速レプリケーション処理の機能を備えているため、マルチコアCPU・マルチCPUの性能を十分に引き出すことができます。
次に、長期にわたってストレージへのアクセスの効率性を高めるために導入したのが、メモリを最大限に有効活用する「データ配置技術(TDPA:Time Series Data Placement Algorithm)」です。時系列データに関しては、同じコンテナの中で、データを登録した順序ではなくデータが発生した時刻順に配置されるため、効率的な検索、さらにはコンテナを横断した最適なデータの配置が行えます。
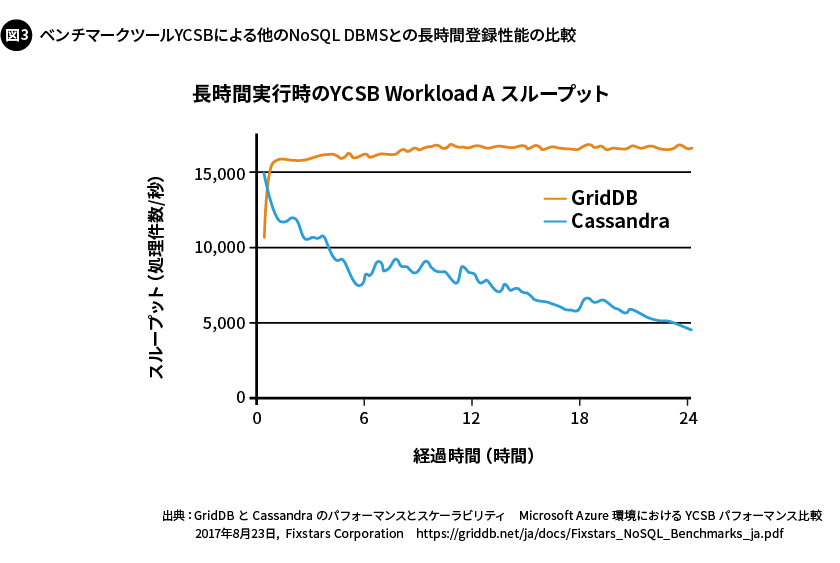
例えば、GridDBのデータモデルであるキーコンテナ型データモデルにおいて、各センサーをそれぞれコンテナにあてはめて、多数のコンテナを扱うこととします。このとき、時刻が近いデータは、コンテナが異なっていても隣接したデータブロックに配置できる特長があります。これにより、同一の時間帯における複数のセンサーのデータに対し、コンテナを横断して素早く検索できるため、ストレージから必要なデータを読み出す効率が向上します。実際のベンチマークにおいても、長時間にわたって処理性能の高さを維持し続けられていることを確認できています(図3)。
さらに、より長期にわたってデータを蓄積したり読み出したりする性能の高さを維持するために、時間軸などでコンテナを分割して複数のクラスタパーティションに配置する機能や、同様の分割単位で過去のデータを一括して削除する機能、コンテナごとに固有のブロックを割り当てる機能もサポートしています。
リアルタイム分析をより身近にするデュアルインターフェース
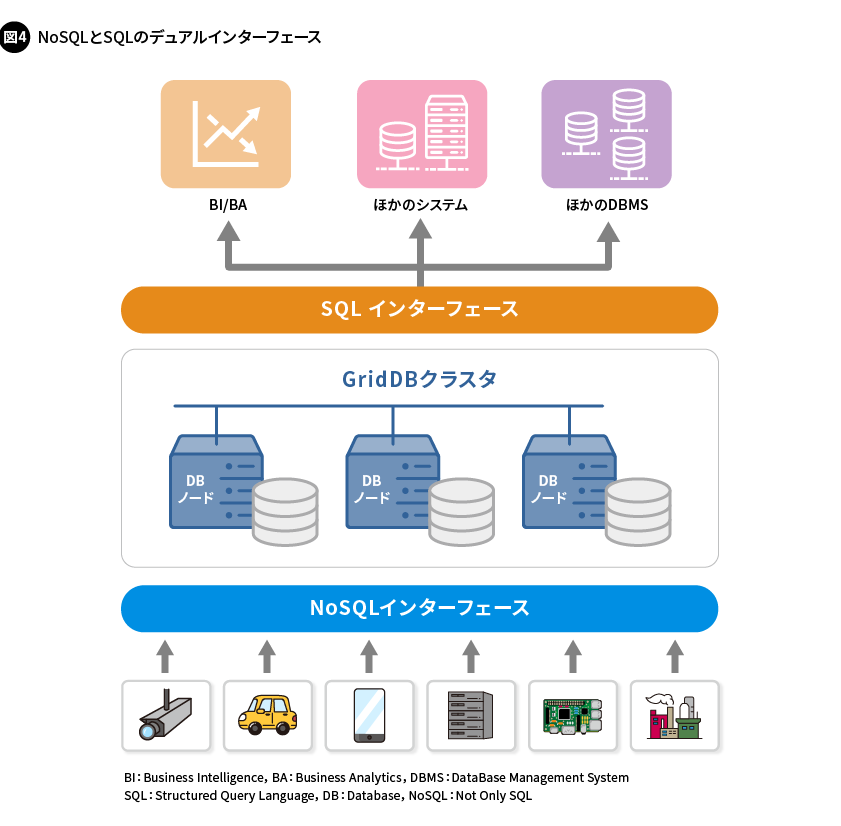
GridDBは、NoSQLデータベースでありながら、RDBMSと同様の標準的なインターフェースを備えています。デュアルインターフェースとも呼ばれる2種類のインターフェースで、GridDBの高速性を生かすNoSQLインターフェースと、高度なリアルタイム分析を容易にするSQLインターフェースを備えています(図4)。
GridDBは、一般的なNoSQL DBMSと同様に、NoSQLインターフェースとして、独自のAPI(Application Programming Interface)をサポートしています。データベースクライアントは、クラスタの構成を収集して解釈する仕組みを内蔵していることから、扱うデータを管理するノードを特定できるため、中間サーバーなどを介さずに直接データの受け渡しができます。また、データを分割する単位であるクラスタパーティションごとにデータをまとめて転送するため、ノード内にあるイベント駆動型の処理エンジンと直結し、わずかなオーバーヘッドの発生で処理が完結します。これにより、低レイテンシーと高スループットを実現し、同時多発的に発生するIoTデータの登録を効率的に行えます。さまざまなプログラミング環境にも対応し、Java/C/Python/Node.js/Go向けのAPIをサポートしています。
もう一つのSQLインターフェースとしては、JDBC(Java DataBase Connectivity)やODBC(Open DataBase Connectivity)といった標準的なAPIを備えているため、SQLでクエリを実行できます。クラスタノード上で、並列分散処理に最適化されたクエリ実行プランが生成され、各ノードのマシンリソースを最大限に活用して高速に処理します。SQLインターフェースを備えていることで、データを分析するにあたり事前にバッチ処理でデータを取り出しておく必要がなく、絶え間なく登録され続ける「今」のデータをリアルタイムに用いて、DWH(Data Ware House)のような分析ができます。また、標準的なAPIを備えているため、一般的なBI(Business Intelligence)ツールを利用でき、ノンプログラミングで手軽にデータを分析することも可能です。
SQLの並列分散処理性能を向上させるための仕組みも備えています。絞り込み条件に基づく最適化(プレディケートプッシュダウン最適化)、コンテナの分割配置やクエリに基づくスキャンやジョインの最適化(パーティションプルーニング最適化・パーティションワイズジョイン最適化)のほか、さまざまなクエリ実行プランを最適化する技術を適用しています。また、データ分析に役立つSQL機能として、ウィンドウ関数機能(OVER句)や分散・中央値・パーセンタイルなどの関数を拡充しています。
さらに、時系列データを分析するために、一定時間の間隔でアップサンプリング・ダウンサンプリングを行う機能(GROUP BY RANGE句)をサポートしています※。この機能を用いることで、例えば欠損を含む時系列データに対して、前後のデータを用いた線形補間を1つのSQLで記述することができます。
※標準的なSQLや一般的なDBMS(MySQL、PostgreSQL、SQLite、Oracleなど)では、範囲に基づいてデータをグループ化する方法として「GROUP BY RANGE」句は直接サポートされていません。ただし、少し煩雑になりますが、複数の構文を組み合わせることで、同様の機能を実現できる場合があります。
ペタバイト級のIoTデータの高度な活用に貢献
ビッグデータ、特にIoTシステムに特化したGridDBは、社会インフラや工場のシステムを中心に、いくつもの現場で採用されてきました。その事例の一つをご紹介します。
GridDBは、長期にわたり製造装置のセンサーデータを蓄積・分析して製品の品質改善を図る、ハードディスク製造会社の品質管理システムに採用されました。このシステムでは、製造・品質に関わる全てのデータを貯めることを目指しており、そのデータ量は5年間で1.9ペタバイトに及びます。GridDB導入前は、データベース専用機を使って大量のデータを分析していましたが、データベース専用機は値段が高く、毎年増えるデータに対応するために高価なデータベース専用機を買い足し続けることがコスト的に大きな課題となっていました。
そこでデータベースの専用機から、複数台の一般的なIAサーバーでクラスタを構成できるGridDBに切り替えることになりました。これにより大幅なコストダウン実現し、現在に至るまで約3年間にわたり稼働を続けています。
工場が稼働している間、センサーデータは製造装置から常に発生し続けます。GridDBでは、キーコンテナ型データモデルに沿った定義に基づいて分散化され、複数台のノードにバランスよくデータを蓄積し続けます。データの蓄積と並行して、分析のためのSQL文が分散化されたクエリ実行プランにより実行されます。使い慣れた既製のBIツールを活用し、より長期間かつ広範囲にわたる製造データを分析できるようになったことで、分析の精度が高まり、高度な品質管理が可能になりました。高信頼なクラスタ処理技術、長期にわたり高速に処理できるデータ蓄積・分析の技術、そして多様なインターフェースを備えたGridDBにより、ペタバイト級の製造データを活用する幅が広がりました。
このほか、電力会社における低圧託送業務システムのような、高い信頼性と性能が求められるシステムにも採用されています。
※DiGiTAL T-SOUL Vol.22で詳しくご紹介しています。
第2回では、膨大な時系列データの扱いに適したGridDBの技術的な特長と、その強みが生かされた適用事例を紹介しました。第3回では、GridDBの運用ノウハウが凝縮されたマネージドサービスであるGridDB Cloud、そしてGridDBにおけるオープンソースソフトウェア(OSS:Open Source Software)への活動について解説します。どうぞご期待ください。

浜口 泰平(HAMAGUCHI Taihei)
東芝デジタルソリューションズ株式会社
ソフトウェアシステム技術開発センター ソフトウェア開発部 第二担当
スペシャリスト
東芝に入社後、データベース管理システムや、文書管理システムの研究開発に従事。現在は、GridDBをはじめとするミドルウェアの開発に取り組んでいる。
- この記事に掲載の、社名、部署名、役職名などは、2023年9月現在のものです。
- この記事に記載されている社名および商品名は、それぞれ各社が商標または登録商標として使用している場合があります。
>> 関連情報
関連記事
連載:IoTが生み出す膨大な時系列データをリアルタイムに処理するデータ基盤技術(連載記事一覧)

