


世の中のさまざまなモノへIoT(Internet of Things)の適用が広がる中、サイバーフィジカルシステム(CPS:Cyber Physical Systems)が注目されています。CPSとは、実世界(フィジカル空間)にあるIoTデバイスやセンサーから多種多様な情報を収集し、仮想世界(サイバー空間)で大規模データ処理技術などを駆使してリアルタイムに分析し、そこで創出した情報や価値を実世界に戻すことで、産業の活性化や社会問題の解決を目指す仕組みです。ここでは、CPSを実現するために必要となるデータ基盤技術と、そのコアとなる「データベース管理システム(DBMS:DataBase Management System)」について、3回にわたって解説します。
第1回では、従来とは異なる「NoSQL」、そして東芝のデータベース管理システム「GridDB」が出現した背景についてご説明します。
データベース管理システムの種類と歴史
爆発的に増えるデータを活用して、社会課題の解決に生かすことが求められる時代。これまで、データの活用範囲を広げてきたのは、データベース管理システム(DBMS)の進化によるものといっても過言ではありません。それを説明するために、DBMSの歴史を振り返ります(図1)。
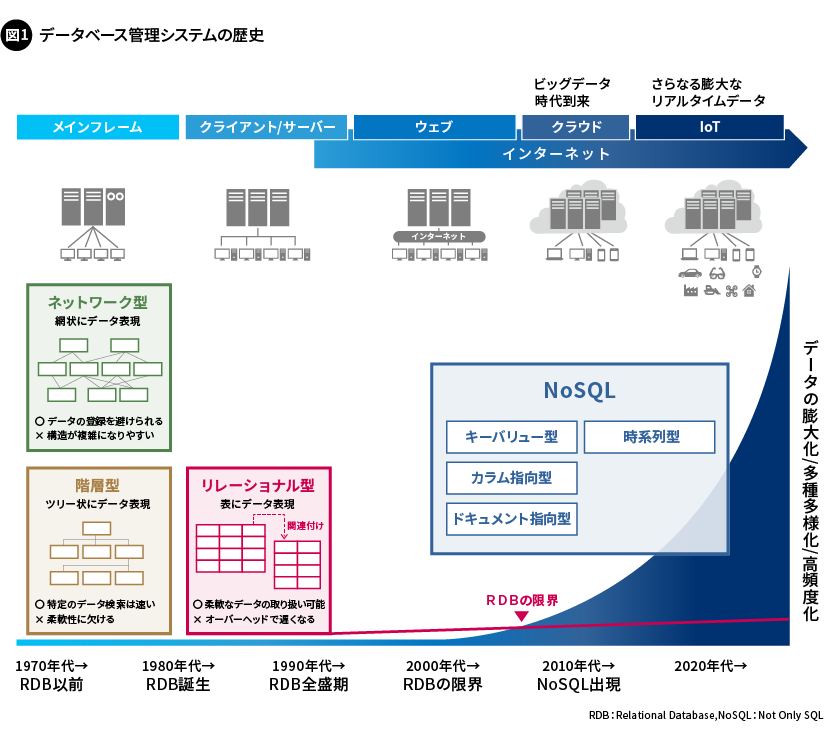
1960年代、データは主にファイルシステムで管理されていました。しかし、複数のファイルシステムに分散して保存されていたため、データには重複や整合性の問題が生じ、その管理は煩雑になっていました。このような問題の解決に向けて出現したのがDBMSです。DBMSとして、次のようなデータモデルが現れました。
- 階層型データベース管理システム(Hierarchical DBMS)
階層型データベース管理システムは、階層的なデータ構造を持つデータを管理するためのDBMSです。1960年代から1970年代にかけて、主に大規模な企業システムで使われました。このDBMSは、データがツリー構造のような階層で組織化されていることから、一連の関連する情報を表現できます。各レコードは、複数の子レコードを持てる一方で、複数の親レコードを持つことはできません。データの構造が決まっているため、管理は簡単にできますが、柔軟性に欠けるため、データ間の複雑な関係性は表現できませんでした。 - ネットワーク型データベース管理システム(Network DBMS)
ネットワーク型データベース管理システムは、階層型データベース管理システムを代替するものとして開発されたDBMSです。1960年代から1980年代にかけて、主に科学技術や製造業の分野で使われました。データは網目状の構造で表現され、複数の親要素を持つことができます。つまり、各レコードは、複数の子レコードと複数の親レコードを持つことが可能です。階層型データベース管理システムよりもデータ間の複雑な関係性を表現できますが、データの変更や更新が複雑なことから、特定のアプリケーションや業界に特化した利用がほとんどで、一般的にはあまり使われませんでした。 - 関係型データベース管理システム(RDBMS: Relational DBMS)
関係型データベース管理システム(RDBMS)は、当時のデータベースの欠点を克服するために、エドガー・F・コッドが1970年に提唱した関係型データモデルに基づき考案されました。このデータモデルは、データを列と行からなる表(テーブル)の形式で表し、テーブル同士をキーで関連付けるものです。このアプローチにより、データ間の関係性が柔軟に表され、管理が容易になります。また、RDBMSは、SQL(Structured Query Language)と呼ばれる標準的な問い合わせ言語に対応したことで、データベースへの命令文(クエリ)を書く作業を大幅に改善しています。
このような特性を持つRDBMSですが、当初は、ハードウェアの性能により効率的に動作することが難しく、すぐには実用化されませんでした。その後、コンピューターのハードウェアの進化に伴い徐々に実用化が進み、1980年代前半からは商業的に導入され始めます。以降は、多くのデータベースで採用されるなど、現在に至るまでDBMSの主流となっています。
2010年代になると、インターネットやセンサーなどのデジタル技術が急速に発展したことで、ビッグデータ時代が到来しました。IoTなどにより収集されたビッグデータは、処理や分析を行い、新たな知見を得たり、より効率的な意思決定が求められるシーンで活用されたりするようになりました。しかしその一方で、RDBMSでは、ビッグデータが持つ「ボリューム(volume、データ量)」「速度(velocity、入出力データの速度)」「バラエティー(variety、データ種とデータ源の範囲)」という3つの特性に対応することが困難になってきました。そこでこれらの特性に対応するために出現したのが、「NoSQL (Not Only SQL)」と呼ばれる新しいタイプのデータベースです。
RDBMSとNoSQL DBMSの違い
インターネットを通じて相互に接続されたさまざまなデバイスやセンサーからデータを収集し、分析や制御を行うIoTシステムが扱うデータには、次のような特性があります。
- 高頻度な発生:ミリ秒/マイクロ秒オーダーの高い頻度でデータが発生することがある。
- 継続的な発生:デバイスやセンサーのほとんどが24時間365日稼働し、絶え間なくデータが収集される。
- リアルタイムな活用:データが発生した直後に、その参照や処理を必要とされる。
- 大量に管理: 大量のデータが収集され、データ量は単調に増加する傾向がある。
これらの特性は、これまでRDBMSが扱ってきた、商取引や商品の売買などのトランザクション型システムのデータ特性とは異なります。そのため、RDBMSは、IoTデータなどのビッグデータの管理に適しているとは言い難いのが現状です。この理由を、RDBMSとNoSQL DBMSの違いを比較しながら、もう少し詳しく解説します(図2)。

データモデル
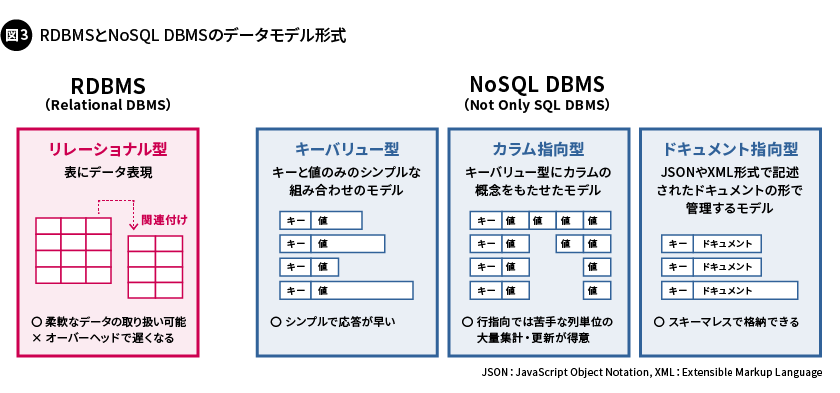
RDBMSは、データを表形式で表現し、関連付けられた複数のデータの扱いに優れています。一方、ほとんどのNoSQL DBMSは、各要素が独立して存在できる、自己完結型のデータ構造でデータを表現します。データの値の形式が異なる、「キーバリュー型」「カラム指向型」「ドキュメント指向型」などのさまざまなデータモデル形式があり、扱うデータの特性に合わせて選択できます(図3)。
データ処理速度
RDBMSは、表形式で関連付けられた複数のデータの参照や、トランザクション処理を得意としています。これを実現するために、データベースの一貫性や整合性を確保する必要があることから、膨大なデータを扱う際にはオーバーヘッドが発生し、データの処理速度が遅くなることがあります。一方、NoSQL DBMSは、シンプルな構造です。複数のデータを参照したり、テーブル間の整合性を取ったりする必要がないため、高速に処理できます。
データの分散性・拡張性
RDBMSは、データの整合性を保つために、1台のサーバーで実行するように設計されていることから、データを複数のサーバーに分散することは困難です。そのため、増加し続ける大量のデータに対応するには、高性能なハードウェアに置き換えてスケールアップすることが必要になります。一方、NoSQL DBMSは、データの整合性を保つ範囲に制限を設けることで、複数のサーバーへの水平分散を実現しています。サーバーを追加するだけでシステムが拡張できる点で、コストメリットも大きいといえます。
データの一貫性
RDBMSは、ACID(Atomicity、Consistency、Isolation、Durability)を強くサポートしています。そのため、例えば、トランザクションの途中でエラーが発生した場合には、その処理をデータベースに反映させないようにして、データの矛盾や不整合を防ぎます。一方、NoSQL DBMSは、CAP定理に基づいたデータの一貫性のモデルを採用しています。CAP定理では、一貫性(Consistency)、可用性(Availability)、分断耐性(Partition tolerance)という3つの要素の中から、分散システムは2つしか選択できないことを示しています。つまり、NoSQL DBMSは、分散システムにおいて、一貫性と可用性と分断耐性のどれを保つのかを選択することになります。RDBMSはトランザクションの信頼性を重視してデータの一貫性を保つのに対し、NoSQL DBMSは柔軟性やスケーラビリティーを重視しているため、データの一貫性は保証されない場合があります。
データ操作
RDBMSは、多くのアプリケーション開発者に長年にわたり支持されている標準的なクエリ言語であるSQLを使用し、データの格納や照会、更新をすることができるメリットがあります。一方、NoSQL DBMSは、独自のAPI(Application Programming Interface)が用意され、特定のアプリケーションやデータモデルに適したクエリ言語を提供します。
RDBMSは、構造化されたデータやトランザクション処理、データの整合性が必要な従来の業務システムに適したデータベース管理システムです。一方のNoSQL DBMSは、高速でスケーラブルな処理が求められるIoTデータなどのビッグデータの管理に適しているといえます。
ビッグデータやIoTシステム向けの時系列データに対応したデータベース「GridDB」
東芝はこれまで、社会インフラシステムや工場のシステムなどで、機器の稼働状況を記録して活用するためのデータ処理を、RDBMSで行ってきました。データ量が、数百メガバイトから数テラバイト程度の時代です。しかし、ビッグデータ時代を迎えてデータの発生する頻度が高まり、データ量が数百テラバイトから数ペタバイトへと膨大になるにつれて、RDBMSではデータを処理することに限界がくることが明らかになってきました。
その一方で、NoSQLデータベースとして一般的なキーバリュー型やドキュメント型などのデータモデルでは、IoTにより高い頻度で発生する時系列データを効率的に処理することが困難でした。これらを受けて当社は、両者のデメリットを補える「GridDB」の開発に着手しました。
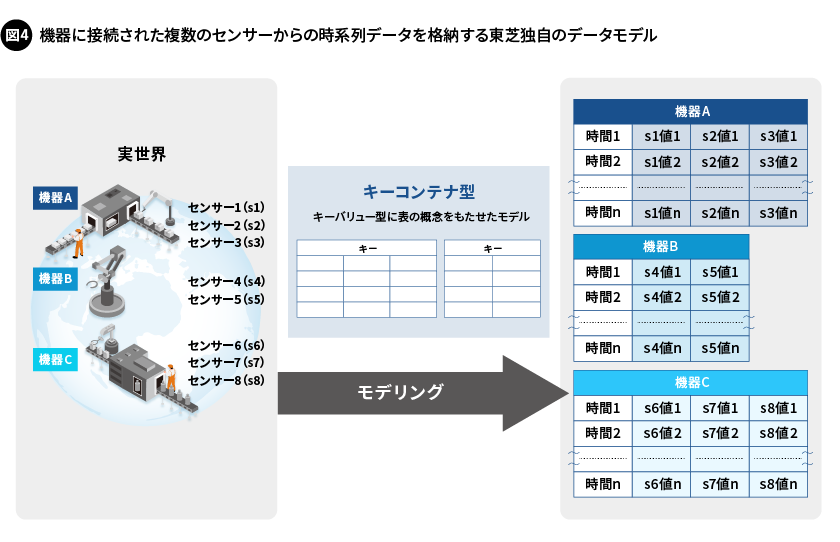
GridDBは、ビッグデータ、特にIoTシステムに特化したNoSQL型の時系列データベース です。実世界では通常、各機器に複数のセンサーが接続され、それらからさまざまな情報を収集します。GridDBでは、これを容易にモデルリングできるように、キーバリューのバリューに「コンテナ」(RDBMSにおける表と似た概念)を導入した、「キーコンテナ型データモデル」を開発しました。この独自のデータモデルによって、例えば、キーには機器名を、コンテナのカラムにはタイムスタンプを、そしてロウにはセンサー1からセンサーnまで複数のセンサーから収集された値を指定することで、時系列データを格納することできます(図4)。

栗田 雅芳(KURITA Masayoshi)
東芝デジタルソリューションズ株式会社
デジタルエンジニアリングセンター マネージドサービス推進部 第二担当
東芝に入社後、産業用コンピューターやワークステーションの基本ソフトウェア/ミドルウェアや、インターネット基盤の研究開発、ビッグデータ/AI/機械学習のプラットフォームの商品企画に従事。現在は、ソフトウェアの企画やオープンソースソフトウェアの普及に取り組んでいる。
- この記事に掲載の、社名、部署名、役職名などは、2023年6月現在のものです。
- この記事に記載されている社名および商品名は、それぞれ各社が商標または登録商標として使用している場合があります。
>> 関連情報
関連記事
連載:IoTが生み出す膨大な時系列データをリアルタイムに処理するデータ基盤技術(連載記事一覧)

