


テレビ局が持つ膨大なアーカイブ映像には、目的の映像コンテンツを検索・特定・抽出するために、コンテンツ単位やシーン単位で「メタ情報」が付与されています。しかし、映像編集や権利管理などの業務では、目的の場面が映っている正確なタイミングをタイムコードで特定する必要があり、これらのメタ情報だけでは十分ではありません。そのため現状では、メタ情報を使って映像を検索した後、人が目視で確認し、目的の場面の位置を手間と時間をかけて特定しています。
この業務の効率化には、シーンよりも細かい「フレーム」単位のメタ情報が有効です。この細かい単位のデータを取得するにあたり、東芝は、映像内に表示される「テロップ」に着目しました。テロップは、番組名や出演者名などを文字情報で映像内に表示し、内容を視聴者にわかりやすく伝えるもので、そこには演出効果を高めるために多くの装飾が施されます。このため、従来の文字認識技術だけでは解析できないという課題がありました。そこで東芝は、長年培ってきたOCR(Optical Character Recognition:光学的文字認識)技術を映像向けに応用し、テロップの文字情報を高精度にデジタル化することに成功しました。これにより、必要な場面の正確な位置を迅速に特定でき、映像コンテンツを扱う業務の効率化を実現します。
映像資産の活用を促進する、AIテロップ文字認識「モジメタ」を紹介します。
膨大なアーカイブ映像から“必要な場面”を探し出す ― テロップのテキストデータ化でテレビ局の現場課題に挑む
テレビ局では、日々膨大な映像コンテンツが制作・放送され、それらはアーカイブ映像として蓄積されていきます。報道やバラエティー、ドキュメンタリー、スポーツなどのジャンルを問わず、これまでに蓄積されている映像の量は、数十年分に及びます。これらのアーカイブ映像は、配信コンテンツとして再利用されたり、新しい番組の映像素材として活用されたりするなど、テレビ局にとっての貴重な資産です。
しかし、この膨大な映像の中から必要な場面の正確な位置を探し出すことは容易ではありません。例えば、ある人物が登場する過去の番組や場面を探す場合、まずその人物の名前を使って検索を試みるのが一般的です。このような、番組やシーンに関連する情報として映像に付与されるテキストデータは「メタ情報」と呼ばれます。ところが、特に古い映像では十分なメタ情報が付与されていないケースも多く、テキスト検索が困難な場合があります。そのため、アーカイブ映像の一つひとつを人が目視で確認しながら、手作業でメタ情報を付与する必要がありますが、その作業は負荷が大きく対応には限界があります。
この課題を解決する鍵となるのが、映像内に表示される「テロップ」と呼ばれる文字情報です。番組名や出演者名、話題のキーワード、商品名、感情のニュアンス、番組の終了時に流れるエンドロールなど、テロップには多くの有用な情報が含まれており、メタ情報の充実に大きく貢献します。
ただし、テロップは映像内に画像として埋め込まれているため、テキストデータとして独立して存在しておらず、機械的に文字情報として扱うことができません。そこでOCR(Optical Character Recognition:光学的文字認識)の技術を活用し、映像内のテロップを高精度に認識してテキストデータとしてデジタル化することで、メタ情報として活用可能にします。
この認識処理を1秒間に複数回実施することで、映像のどのタイミングにどのようなテロップが表示されているのかを詳細に取得し、これをテキストデータ化することで、映像検索の精度と効率を飛躍的に向上します。これにより、必要な場面を迅速かつ正確に抽出できるだけでなく、これまで埋もれていた映像も含めて網羅的に検索できるようになり、より最適な映像選定が可能になります。
50年以上にわたって培った画像処理技術が支える先進のAIテロップ認識
映像内のテロップをOCRで認識しようとすると、期待通りの結果が得られないケースが少なくありません。一般的なOCRの技術では、背景の複雑さや文字の装飾、特殊なフォントといったテロップ特有の装飾などが認識の障壁となり、精度が著しく低下してしまいます。
東芝では、1967年に郵便番号自動読取区分機を開発して以来、50年以上にわたり画像処理技術を磨き続けてきました。文字認識技術は、機械学習やディープラーニングなどの先進技術を取り入れながら進化を遂げており、その技術を映像特有の文字認識に応用したのが、AIテロップ文字認識「モジメタ」です。
※東芝の文字認識技術の詳細については、こちらの記事をご覧ください。
モジメタは、映像内のテロップを高精度に認識し、テキストデータとして抽出するOCRベースのソリューションです。ここで重要なのは、一般的なOCRは帳票のような文書(静止画像)を対象としているのに対し、モジメタは、連続する複数の画像(フレーム)で構成される映像を対象としている点です。
日本のテレビ放送では、1秒間に29.97フレーム(29.97fps)が表示されます。例えば、あるテロップが3秒間表示された場合、そのテロップは90フレームにわたって繰り返し表示されていることになります。
この各フレームを個別にOCR処理すると、同じテロップでもフレームごとに認識結果が分かれてしまい、ばらばらになってしまいます。そこでモジメタでは、映像を連続したフレームとして扱い、複数のフレームにまたがるテロップの認識結果を統合(マージ)する処理を行っています。
モジメタの具体的な処理の流れは以下の通りです(図1)。
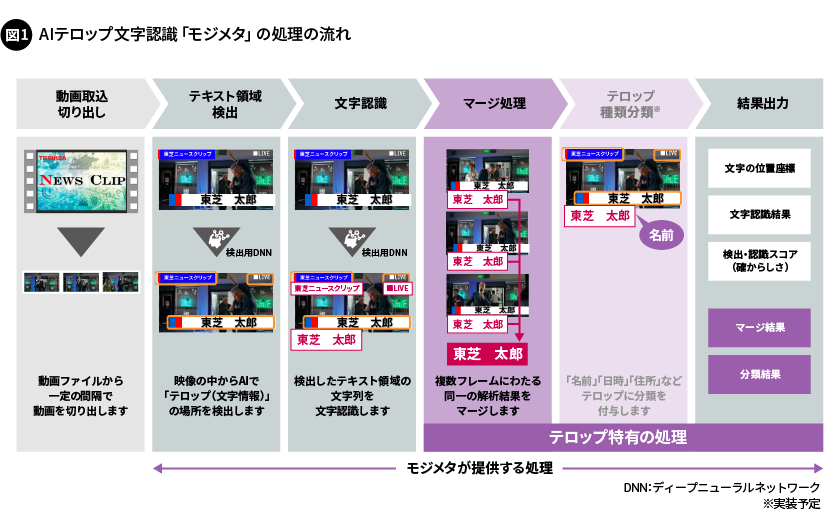
一定間隔で切り出したフレームを取り込みます。一般的なOCRと同様に、テロップが表示されている領域を検出し、領域内にある文字列を認識します。これ以降が、テロップ特有の処理となり、同一と推定される複数のフレームにわたるテロップの解析結果をマージ処理します。マージしたテロップを「名前」「日時」「住所」などの属性ごとに分類※し、最後に結果を出力します。
出力される結果には、一般的なOCRが出力する位置座標や認識文字列、検出・認識の確からしさ(スコア)に加え、マージ処理や分類の結果なども含まれます。これにより、映像内のテロップ情報を、より実用的な形で活用できるようになります。
※テロップを分類する機能は、今後実装を予定しています。
テロップ特有の処理に対応 ― 認識精度を高めるための工夫と技術
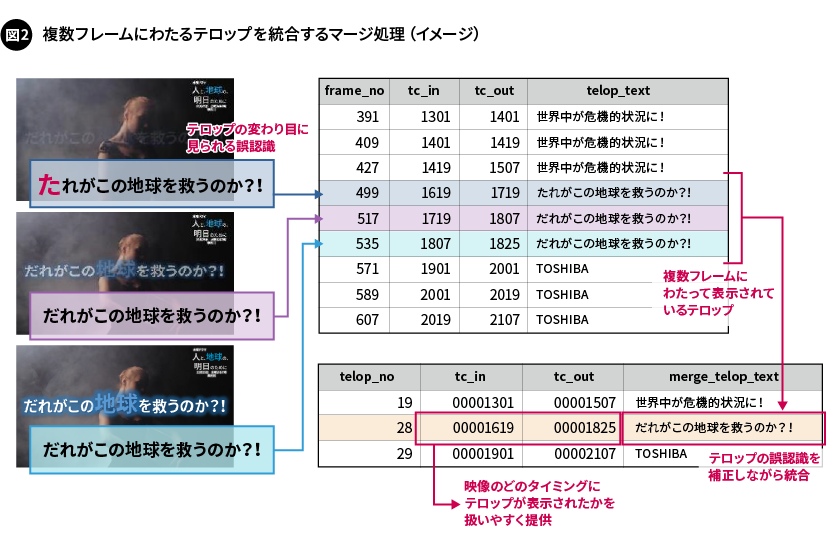
テロップが複数のフレームにわたって表示される場合、その認識結果は必ずしも一定ではありません。例えば、テロップでは、フェードインやフェードアウトと呼ばれる、その表示を徐々に鮮明にしていったり、自然に消えていくように見せたりする演出がよく使われます。この効果はテロップの変わり目で特に強くなり、文字がブレたりぼやけたり、さらには文字の一部が欠けたりすることがあるため、認識精度に影響を与えていました。
図2に示した「だれがこの地球を救うのか?!」というテロップの例のように、フェードインのときに表示された最初のフレームの認識で、「たれがこの地球を救うのか?!」と誤認識するようなことがよく起こります。このような場合、機械的に読み取っただけでは、同じテロップでもそれぞれ異なるテロップとして扱われてしまいます。
そこでモジメタでは、複数のフレームに現れた同一の文字と思われるテロップに対し、補正しながらマージを行う処理を追加しました。このひと手間により、認識精度が向上し、より扱いやすい形での結果出力が可能となりました(図2)。
さらに、モジメタを開発するにあたっては、ベースとなる文字認識の精度を高めることにも注力しました。背景が複雑な文字や、デザイン性の高い文字、縦書きと横書きの混在など、テロップ特有の装飾を学習させることで、認識エンジンを強化しています。また、テレビ局での確認作業などに使われる高圧縮率・低解像度の映像にも対応し、映像特有のさまざまな課題に柔軟に対処しています。
加えて、モジメタでは、人名などに多く使われる異体字の認識にも対応しました。例えば、「高」⇔「髙」、「邉」⇔「邊」、「斎」⇔「齋」といった、読みや意味が同じでも形の異なる文字です。これらの複雑な文字を認識エンジンに学習させる作業は、正字(標準的な字体)の認識に影響を与えないように慎重に行う必要があり、難易度が高くなります。これを、経験豊富な東芝の技術者が、繊細なAIチューニングを行い、バランスの良い学習を施しました。その結果、正字と異体字のどちらも、誤認識を抑えながら高い認識精度を実現しています。
フレーム単位の処理で映像業務支援の幅を広げる ― 品質確認・検索・抽出を効率化する「モジメタ」の活用
モジメタが認識したフレーム単位のテロップ情報は、映像の品質確認作業の効率化に大きく貢献します。映像の品質確認はさまざまな観点から行われ、特に、文字で表記されているテロップに関しては、誤字・脱字、放送にふさわしくない表現、さらには放送するにあたり注意を払うべきガイドラインなど、確認するべき項目が多岐に及びます。
これまでは、担当者が映像を目視でチェックし、膨大な時間と労力をかけて確認作業を行っていました。これに対し、モジメタによって得られたテロップのテキストデータを活用することで、用語辞書との照合による放送にふさわしくない表現の検出や、ほかのAIとの連携による誤字・脱字の検出、事実確認などが可能となり、映像品質の向上とチェック業務の効率化が期待できます。
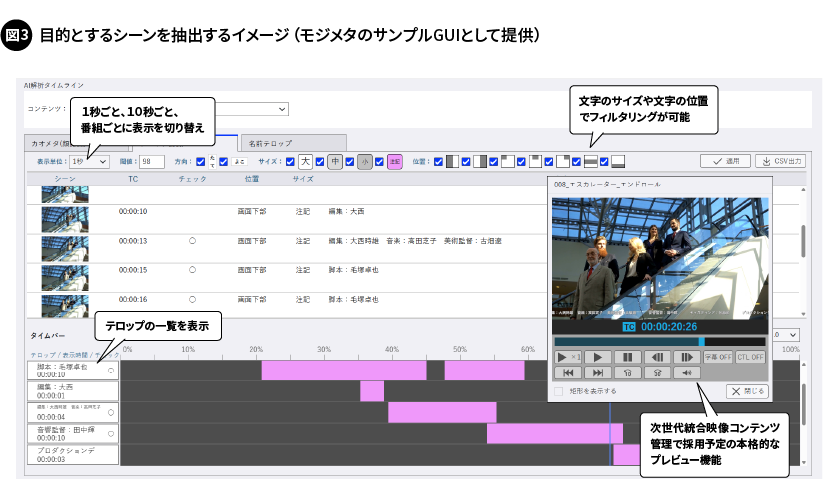
また、モジメタの認識結果は、テレビ局による業務適合性評価などから得られたノウハウを反映した操作画面で確認できます。表示は、1秒単位、10秒単位、そして番組単位で切り替えることができ、用途に応じた使い分けが可能です。例えば、エンドロールの書き起こしには1秒単位を、番組のコーナーテロップを確認する際には10秒単位を選択するなど、柔軟に利用できます。
さらに、モジメタは、テキストデータに加えてテロップが表示された座標データも出力します。この座標データを活用することで、テロップの大きさや表示された位置、縦書き・横書きの形式などを絞り込むことができ、コピーライトや注記のような小さな文字の抽出などにも役立ちます。加えてタイムバー機能では、各文字列が映像のどの時間帯に何秒程度表示されたのかを視覚的に確認することができます。
このように操作画面には、目的の場面を迅速に抽出するためのさまざまな工夫が施されています(図3)。
東芝が描く未来。― 映像の価値を引き出す次世代のコンテンツ管理
東芝では、映像コンテンツに特化したもうひとつのソリューションとして、映像に映る人物を判別・特定する顔認識AI「カオメタ」※を提供しています。モジメタが映像内の文字情報をテキストデータ化するのに対して、カオメタは人物を特定するもので、いずれもフレーム単位のメタ情報を提供する映像コンテンツに特化したソリューションです。
※「カオメタ」については、こちらの記事で詳しく紹介しています。
この「フレーム単位」という細かい粒度によるメタ情報の抽出は、AI技術によって初めて可能となりました。従来の番組単位やシーン単位のメタ情報に加えて、フレーム単位のメタ情報が利用できるようになったことで、映像が飛躍的に扱いやすくなります。
例えば、新たに制作する番組で過去の映像素材を活用する場合、膨大なアーカイブ映像の中から最適な場面を抽出する必要があります。このとき、番組単位のメタ情報は「どの番組の映像を使うのか」の判断に、フレーム単位のメタ情報は「その番組のどの場面を使うか」の判断に役立ちます。また、配信などマルチユースを行う際の権利処理や、映像品質の確認作業においても、対象とする映像の特定の場面を直接確認する必要があるため、フレーム単位のメタ情報が業務の効率化に大きく貢献します。
「モジメタ」は、これまで十分に活用されてこなかった映像内の文字情報に“新たな価値”を見いだす革新的なソリューションです。映像内の文字をテキストデータとして扱えるようになることで、メタ情報の拡充によるアーカイブ映像の検索性向上や、映像品質の確認業務の効率化、そして新たな価値創造へとつながっていきます。
今後は、次世代コンテンツ管理システムとの連携を予定しており、映像コンテンツのライフサイクル全体を通して、メタ情報の整備や各種情報の共有・管理をスムーズに行えるようにするとともに、作業の重複や漏れを防ぎ、業務全体のさらなる効率化を推進します。
東芝は、高精度なAI技術と進化し続ける次世代のコンテンツ管理で、映像業務全体の効率化と映像資産の活用の促進に貢献していきます。今後の展開に、ぜひご期待ください。
- この記事に掲載の、社名、部署名、役職名などは、2025年9月現在のものです。
- この記事に記載されている社名および商品名は、それぞれ各社が商標または登録商標として使用している場合があります。

