
活動事例
開発秘話
当社開発の製品や技術について、そのきっかけや開発過程のエピソードなどを紹介します。
「郵便物処理システムに用いられる住所認識技術」
- 人間でも判読困難な筆記体の読み取り -
郵便局では、毎日大量に集められる郵便物を宛先ごとに仕分けしなければなりません。この作業を効率化するため、郵便番号を読み取ることで自動化するシステムが1960年代から実用化されています。最近では、郵便番号だけでなく、住所も読み取っているのをご存知でしょうか?現在では番地まで読み取り、配達する順番に並べるところまで自動化されています。

図1 郵便物処理システム*1
*1:東芝プレスリリース http://www.toshiba.co.jp/about/press/2003_08/pr_j0401.htm
筆記体認識の難しさ
図2は、フランスの住所に存在する単語です。この単語、何と書かれていると思いますか?“adiene”? “aclieru”?...実は正解は“adresse”です。このように、筆記体の認識には、「文字の境目がわからない」、「一つの文字がいろいろなアルファベットに見えてしまう」という難しさがあり、人間でも判読が困難なことが少なくありません。それでも、きっとフランスの人にはこの単語が読めるでしょう。それは、“adiene” “aclieru”という単語は存在しないが、“adresse”という単語は存在することを知っているからです。このように、筆記体の認識では、単語が存在するかどうかをデータベースを用いて照合する技術が非常に重要になります。
![]()
図2 筆記体の例
筆記体認識の高速化と精度向上
一般的に単語の認識を行う際は、まず文字の境目を検出し、文字列の候補を生成します(図3)。そして、これらの候補とデータベースを総当りで比較し、最もスコアの高い組合せをもって認識結果とします。データベースを参照して認識結果を決定するので、図の例のように、読めない文字や誤っている文字を補完できることもあります。
ところが、筆記体の場合は文字の境目が様々に考えられるので、多い時は数百万通りにも及ぶ文字列候補が生成されます。また、データベースには、住所に使用される単語が数十万件も登録されます。これらを総当りで比較するプログラムを試作してみたところ、一つの住所を読み取るのに数分かかってしまい、とても実用に耐えるものではありませんでした。そこで、住所の階層構造をうまく利用したり、繰り返し同じ計算を行う部分を徹底的に効率化したりと、数々の高速化技術を駆使し、ついには1秒間に10通以上読み取るまでの高速化を実現しました。
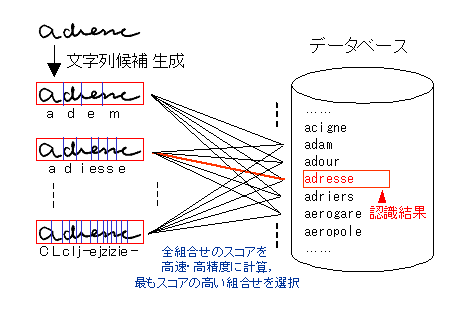
図3 データベースとのマッチング
高速処理は実現することができましたが、まだ問題が残っていました。それは認識精度です。文字列候補がたくさん生成されるため、正解文字列がその他たくさんの候補に埋もれてしまい、認識精度が落ちてしまったのです。そこで私たちは、文字列候補とデータベースをマッチングをする際のスコア計算に注目しました。従来は「一致した文字の数」のような単純なスコアが使われていましたが、ここに統計的な手法を取り入れることを試みました。統計的パターン認識の世界では、「事後確率が最大となる組合せを認識結果とすれば誤認識率を最小にできる」という基本原理があります。「事後確率」とは、一種の「条件付き確率」のことで、生成された文字列候補や各文字の認識結果全て(つまり図3における左側全て)を条件としたときに、データベース内の単語(“adresse”など)が正解である確率を表します。この値を計算することが従来難しかったのですが、私たちは簡単な計算式で求める手法「事後確率比法」を考案、事後確率をスコアに採用することできるようになり、大きく性能向上させることに成功したのです。従来法に比べ誤認識率を50%低減する例も確認しており、学会でも注目を集めています。
今後の展開
以上のように、住所認識処理の高速化および精度向上を重ね、2004年にはスウェーデン、2006年にはフランスに郵便処理システムを納めることができました。いずれのシステムも、お客様に高い評価を頂いています。
筆記体認識の技術は、アルファベットの筆記体だけでなく、各国の言語、書体への適用が可能と考えられます。更に、文字にとどまらず、音声等のパターン認識への展開も考えられ、今後の応用範囲の拡大が期待されています。