
![]()


汎用的な使われ方でも精度の著しい向上が求められる中で、ディープラーニングはインダストリアル領域において実用化に近づきつつあるように見えます。しかし、画像や音声はもちろん、さまざまなセンサーや機械から得られるIoT*データに分析の対象を広げ、ユーザーの課題解決に相応しい学習と推論の仕組みを構築することは容易ではありません。ディープラーニングが真に必要な結果を出すためには、ニューラルネットワークを構成するノード数やレイヤー数など無数のパラメーターを複雑に調整しながら、ネットワークの最適化をはかる必要があるからです。そこで東芝では、パラメーターを自律的に調整しながら、最適なニューラルネットワークを自動的に構築する技術を確立。さまざまな領域で実証実験を積み重ね、先進的な成果を手にしています。今回は、「自動学習実行環境」「並列分散学習技術」に加え、ディープラーニングの導入障壁に風穴をあける「3本目の矢」ともいうべき、「ネットワーク最適化技術」について、その適用事例も含めてご紹介します。
* IoT:Internet of Things(モノのインターネット)
深層化し、急速に進化するニューラルネットワーク
ディープラーニングを支えるニューラルネットワークは、脳のメカニズムを模倣した情報処理の仕組みです。入力層、中間層、出力層の3種類の層からなり、分析対象であるデータはこれらの層を通過して演算処理されます。
ディープラーニングは中間層の数を増やす(深くする)ことで、学習モデルの精度を高めます。例えば、正常値か異常値かの判定を行うためのデータの特徴を学習する場合、入力されたデータが出力層に至るまでの間、ニューロンの数理モデル*で構成された各層は、前の層から受け取った特徴量に重み値を付けて加算し、新たな特徴量を抽出して次の層へと伝播します。同時に、前後の層を逆方向に処理を行い、推論結果の誤差を最小化するためのパラメーター調整を行って学習を自ら進めていきます。
*ニューロンの数理モデル:神経回路網を構成する1つのニューロンを数理的に模擬したモデル
こうしたニューラルネットワークの深い構造と、順方向や逆方向の情報の伝播が、ディープラーニングで高い精度を実現できる秘密です。ディープラーニングを活用すれば、あたかも人間が対象を分類、認識、検知、理解するように、高い精度で画像を見極め、音声を聴き分け、物体を検出し、これから起こることを予測・推論することが可能になるのです。特にニューラルネットワークの深層化はこの数年で劇的に加速しました。2012年のImageNetによる画像認識コンペティションにおいて、中間層が8層で構成された「AlexNet」が誤認識率16.4%を記録。従来の機械学習を大きく引き離す高い認識精度を達成し、ディープラーニングが脚光を浴びるきっかけとなりました。これを皮切りに、2014年は19層の「VGG」や22層の「GoogLeNet」が深層化による劇的な認識精度の改善を実現。2015年には学習の効率を維持しながら152層という超深層を実現した「ResNet」が、遂に人間を超える誤認識率3.56%を達成するに至ったのです。
深層化し、急速に精度をあげるニューラルネットワーク。人間と変わらぬ知覚を身に付けつつあるその進化は一方で、インダストリアル領域でのディープラーニングのスムーズな導入と実用化を困難にする要因にもなっています。
汎用ネットワークを生かした、自動最適化技術を確立
現在、産業界ではディープラーニングへの関心が急速に高まってきていますが、その実用化には大きな課題があります。
インダストリアル領域において分析する対象は、画像や音声はもちろん、センサーから時系列に集められる多種多様なIoTデータにまで広がり、製造ラインの最適化や歩留まり向上、社会インフラの安定稼働などで大きな効果を上げることが期待されています。しかし、これらクリティカルな課題を解決するために必要な精度を求めてニューラルネットワークを多層に構成すればするほど、その構造を工夫し、ノード数やレイヤー数といった多岐にわたるパラメーターを精密かつ複雑に調整しなければならず、エンジニアへの大きな負担となります。ディープラーニングを活用してどのくらい目的を達成できるかは、ニューラルネットワークを構築する専門家やエンジニアの腕とノウハウに依存してしまうのです。
そこで東芝では、多層かつ複雑なニューラルネットワークを自動で最適化する技術を確立しました。まず汎用的な基本ネットワーク(図1)を課題やデータ種別に応じて選択し、最低限の条件を設定して学習をスタートさせます。すると、学習と学習結果の評価を繰り返しながら、ネットワークの層数やユニット数(ニューロン数)といったハイパーパラメーターを調整。最適なニューラルネットワークへと、その構成を柔軟に変更させながら、あたかも自律的に成長していくような画期的な技術です。

その際、肝となるのは基本ネットワークを正しく選択できるか否かです。動体検知や文字認識などの画像処理であれば畳み込み型(CNN)、音声認識や時系列データであれば再帰型(RNN)など、ニューラルネットワークは応用したい分野ごとに必要な構成が異なるからです。東芝はこれまでに培ってきたディープラーニングの研究を生かし、ユーザーの課題に応じた最適な基本ネットワークを見極め、さらに複数の基本ネットワークを組み合わせて活用するノウハウを蓄積。さまざまな課題に対して、ネットワーク最適化を行ったディープラーニング適用の検証を重ね、多くの成果を上げています。
ネットワーク最適化によるディープラーニングの実証実験を推進

東芝では、ディープラーニングを活用することでユーザーに提供できる価値を「識別」「予測/推定」「制御」の3つに分類(#01で詳しく紹介)。特定の項目に対する計測値の時間変化を記録した「時系列データ」と、特定の時点における複数の項目の計測値を集めた「横断面データ」をそれぞれ分析したときに提供できる価値を検証することを目的に、ネットワーク最適化によるディープラーニングを活用した実証実験を進めています。
①隠れた関係性を学習し「データ異常」を検知
基本ネットワークに自己符号化型(AE)を採用し、宅配便の荷物に取り付けたセンサーから取得した温度や湿度、気圧などの時系列データを分析しました。冷蔵便のデータを正常値として学習させたところ、温度と湿度の関係性を見つけ出してモデル化。通常便の温度データだけを冷蔵便の温度に改ざんしても、温度と湿度の関係性からデータの異常として見極めることができました。これにより、単一のセンサーを分析するだけでは判断できないようなものにも、適用できることが確認できました。
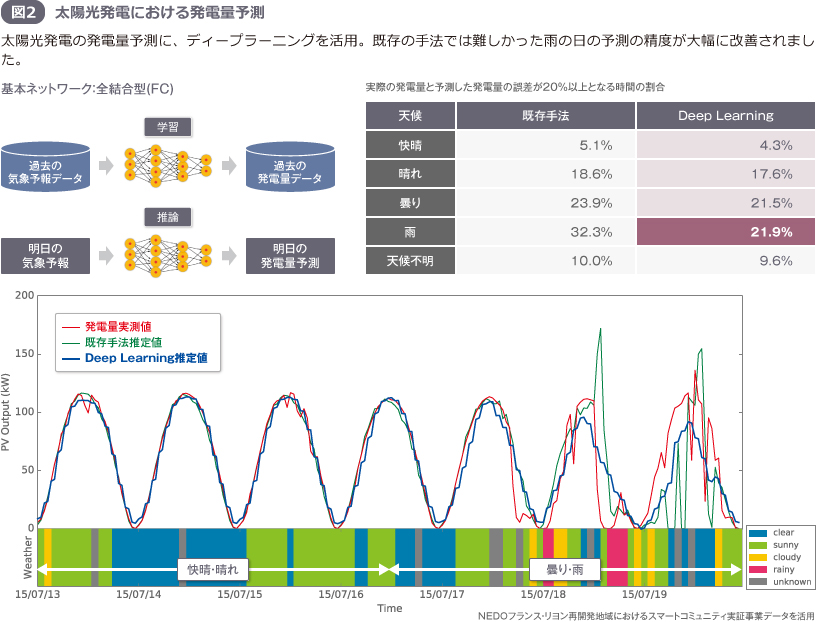
②雨天時の太陽光発電量を、高精度に予測
基本ネットワークに全結合型(FC)を採用し、従来の分析手法では難しかった、雨天時における太陽光発電での発電量を予測しました。過去の気象予報データと発電量データの関係性を学習させて最適化されたネットワークに、明日の気象予報を入力。従来の手法では、実際の発電量と予測した発電量の誤差が20%以上ある時間の割合が32.3%だったのに対し、21.9%にまで縮小。雨天時でも高い精度で太陽光での発電量を予測できるようになりました(図2)。
③人手いらずな機械部品の異常検知
基本ネットワークに、畳み込み型(CNN)と、収束性を高めた再帰型(LSTM)を組み合わせて採用。まず、機械のセンサーから取得した正常・異常条件における動力電流と加速度のデータから、短時間の波形パターンをCNNでモデル化。次にその波形が出現する順序をLSTMでモデル化するという2段構えで、ネットワークの最適化を図りました。その結果、人手による特徴量の設計なしで、目標としていた機械の動力部品の異常検知の適合率90%を超える性能が達成できました。
ここで紹介した以外にも、東芝では製造ラインにおける不良原因の特定やデータセンターにおける電力使用効率の改善など、ネットワーク最適化技術を駆使したディープラーニングの検証を積極的に進めています。また、その根幹を担う基本ネットワークに関しても、独自のフレームワークの開発を積極的に推進。自己符号化型(AE)とデータ生成型(GAN)を組み合わせることにより、例外的な異常を見落とさず、検知漏れや誤差を徹底的に排除して、より高い精度で異常を検知するニューラルネットワークを開発しました。
多数のパラメーターをどう調整すればよいかわからず、思ったほどの精度が出ない。学習モデルの確立にかかるコストと人手を考えると導入をためらってしまう。インダストリアル領域でディープラーニングを活用するために真に必要なことは、そんなお客さまの声に応えて、現状を打開する質の高いパートナーなのかもしれません。東芝は、ネットワーク最適化技術にさらなる磨きをかけ、より多くのお客さまが、さまざまな課題に対して、ディープラーニングをより高い精度で、簡単に活用できるように、今後も先進的な取り組みを進めていくつもりです。
※この記事に掲載の、社名、部署名、役職名などは、2017年3月現在のものです。





